深入理解Redis之简单动态字符串
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。Reids自己构建的sds要比默认的c字符串性能更好,也更安全。
SDS
那么sds的结构是什么样的呢?与C字符串有什么不同?
下面是sds的定义
struct sdshdr {
//记录buf数组中已使用字节的数量
//等于sds所保存字符串的长度
int len;
//记录buf数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
在64位系统下,属性len和属性free各占4个字节,紧接着存放字节数组。
上面的buf[]是一个柔性数组。柔性数组成员(flexible array member),也叫伸缩性数组成员,只能被放在结构体的末尾。包含柔性数组成员的结构体,通过malloc函数为柔性数组动态分配内存。
关于柔性数组,可以看这篇文章:C语言柔性数组讲解
下面展示一个SDS示例:
set name "Redis"
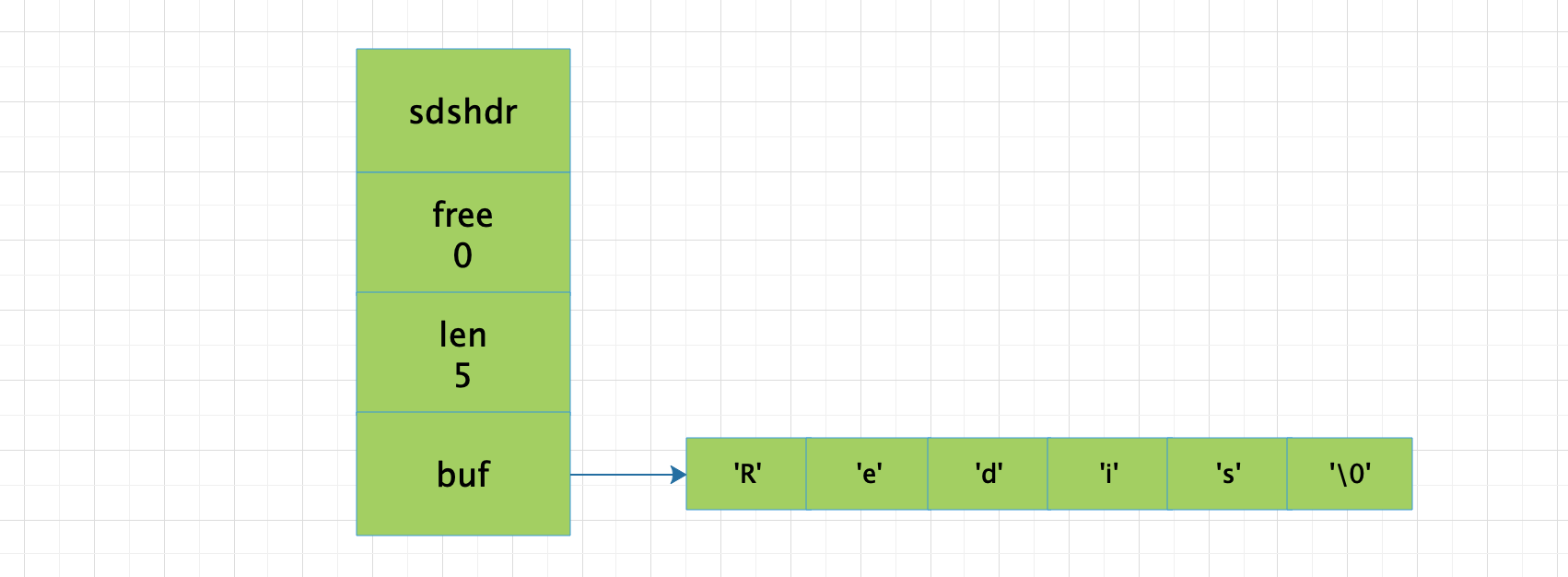
- free属性的值为0,表示这个SDS没有分配任何未使用空间。
- len属性的值为5,表示这个SDS保存了一个物字节长的字符串。
- buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而最后一个字节则保存了空字符'\0'。
SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配额外的1字节空间,以及添加空字符到字符串末尾等操作,都是由SDS函数自动完成的,所以这个空字符对于SDS的使用者来说是完全透明的。遵循空字符串结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
SDS与C字符串的区别
C语言使用长度为N+1的字符数组来表示长度为N的字符串,并且字符数组的最后一个元素总是空字符'\0'。但是C语言使用的这种简单的字符串表示方式,并不能满足Redis对字符串在安全性、效率以及功能方面的要求,下面来聊聊为什么SDS比C字符串更适合用于Redis。
SDS获取字符串长度复杂度为O(1),C字符串为O(N)
由于C字符串并不记录自身的长度信息,所以为了获取一个C字符串的长度,程序必须遍历整个字符串,对遇到的每个字符进行计数,直到遇到代表字符串结尾的空字符为止,这个操作的复杂度为O(N)。
和C字符串不,因为SDS在len属性中记录了SDS本身的长度,所以获取一个SDS长度的复杂度为O(1)。
通过使用SDS而不是C字符串,Redis将获取字符串长度所需的复杂度从O(N)降低到了O(1),这确保了获取字符串长度的工作不会成为Redis的性能瓶颈。所以,即使我们对一个非常长的字符串反复执行STRLEN命令,也不会对系统性能造成任何影响,因为STRLEN命令的复杂度仅为O(1)。
SDS杜绝了缓存区溢出
C字符串不记录自身长度除了会导致获取字符串长度复杂度高之外,还带来的另一个问题就是容易造成缓存区溢出(buffer overflow)。举个例子,假设程序里有两个在内存中紧邻着的C字符串s1和s2,其中s1保存了字符串"Redis",而s2则保存了字符串"MongoDB",如下图所示。

如果一个程序员决定通过strcat(s1, " Cluster")将s1的内容修改为"Redis Cluster",但粗心的他却忘了在执行strcat之前为s1分配足够的空间,那么在strcat函数执行之后,s1的数据将溢出到s2所在的空间中,导致s2保存的内容被意外地修改,如下图所示。

这是使用C字符串所会带来的问题。与C字符串不同,SDS的空间分配策略完全杜绝了发生缓存区溢出的可能性:当SDS API需要对SDS进行修改时,API会先检查SDS的空间是否满足修改所需的要求,如果不满足的话,API会自动将SDS的空间扩展至修改所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现前面所说的缓存区溢出问题。
减少修改字符串时带来的内存重分配次数
因为C字符串并不记录自身的长度,所以对于一个包含了N个字符的C字符串来说,这个C字符串的底层实现总是一个N+1个字符长的数组(额外的一个字符空间用于保存空字符)。因为C字符串的长度和底层数组的长度之间存在着这种关联性,所以每次增长或者缩短一个C字符串,程序都总要对保存这个C字符串的数组进行一次内存重分配操作:
- 如果程序执行的是增长字符串的操作,比如拼接操作(append),那么在执行这个操作之前,程序需要先通过内存重分配来扩展底层数组的空间大小--如果忘了这一步就会产生缓存区溢出。
- 如果程序执行的是缩短字符串的操作,比如截断操作(trim),那么在执行这个操作之后,程序需要通过内存重分配来释放字符串不再使用的那部分空间--如果忘了这一步就会产生内存泄漏。
为了避免C字符串的这种缺陷,SDS通过未使用空间解除了字符串长度和底层数组长度之间的关联:在SDS中,buf数组的长度就不一定是字符数量加一,数组里面可以包含未使用的字节,而这些字节的数量就由SDS的free属性记录。
通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略。
1.空间预分配
空间预分配用于优化SDS字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空间。其中额外分配的未使用空间数量由以下公司决定:
- 如果对SDS进行修改之后,SDS的长度(也即len属性的值)小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。举个例子,如果进行修改之后,SDS的len将变成13字节,那么程序也会分配13字节的未使用空间,SDS的buf数组的实际长度将变成13+13+1字节(额外的一字节用于保存空字符)。
- 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。举个例子,如果进行修改之后,SDS的len变成了30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际长度为30MB+1MB+1byte。
通过空间预分配策略,Redis可以减少连续执行字符串增长操作所需的内存重分配次数。
2.惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作:当SDS的API需要缩短SDS保存的字符串是,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用free属性来将这些字节的数量记录起来,并等待将来使用。
通过惰性空间释放策略,SDS避免了缩短字符串时所需的内存重分配操作,并未将来可能有的增长操作提供了优化。与此同时,ADS也提供了相应的API,让我们可以在有需要时,真正地释放SDS的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
二进制安全
什么是二进制安全?
通俗地将,C语言中,用'\0'表示字符串的结束,如果字符串本身就有'\0'字符,字符串就会被截断,既非二进制安全;若通过某种机制,保证读写字符串时不损害其内容,则是二进制安全。
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
为了确保Redis可以适用于各种不同的使用场景(保存文本、图像、音视频等),SDS的API都是二进制安全的(binary-safe),所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设,数据在写入时是神峨眉样的,它被读取时就是什么样的。
这也是将SDS的buf属性成为字节数组的原因----Redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
整理自:
《redis设计与实现(第二版)》
《redis5设计与源码分析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号