数据质量(一)
数据质量分析的主要任务是检查原始数据中是否存在脏数据,脏数据一般指的是不符合要求,以及不能直接进行相应分析的数据。数据的质量分析侧重于脏数据的发现,而数据清洗则是对这些脏数据的修正或者丢弃。一般情况下,数据的质量分析与数据清洗是相伴而行的,在分析出脏数据的时候伴随着数据的清洗。
常见的脏数据包括如下:
1.缺失值
缺失值产生的一般由如下原因造成:
(1) 有些信息无法获取;
(2) 有些信息出现遗漏;
(3) 属性值不存在,有些情况下,缺失值并不意味着数据有错误。对一些对象来说某些属性值是不存在的,比如未结婚的配偶姓名。
缺失值的影响:
(1) 数据挖掘建模将丢失大量有用数据;
(2) 数据挖掘模型所表现出来的不确定性更加显著,模型中蕴含的规律更难把握;
(3) 包含空值的数据会使得建模过程陷入混乱,导致不可靠的输出。
如何发现缺失值
那如何发现缺失值呢?pandas可以帮助我们轻松的完成任务。pandas使用浮点值NaN(Not a Number)表示浮点和非浮点数组中的缺失值,如下所示:
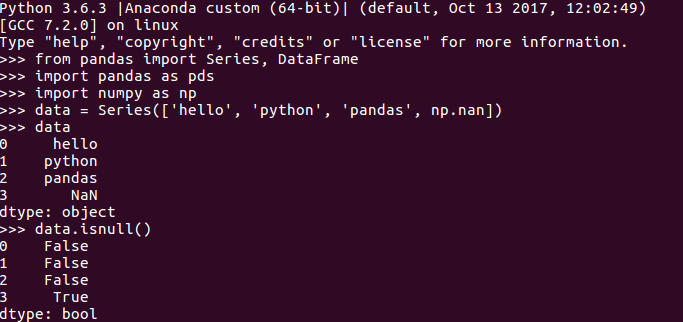
另外,Python内置的None值也会被当做NA处理:

2.异常值
异常值是指数据是否有录入错误以及含有不合理的数据,这些是通常是样本中的个别值,其数值明显偏离其余的观测值,异常值也称之为离群点,异常值的分析也称为离群点分析。
常用的异常值分析方法如下:
(1) 简单统计量分析
对数据进行描述下统计,进而查看哪些数据是不合理的。最常用的统计量是最大值和最小值,用来判断这个变量的取值是否超出了合理的范围。例如客户年龄最大值为200岁,则改数据存在异常。
pandas拥有一组常用的数学和统计方法可以实现简单的计量分析。
(2) 3σ原则
(3) 箱型图分析
3.不一致的值
数据不一致是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相悖的挖掘结果。
不一致的数据产生主要发生在数据集成过程中,这可能是由于被挖掘的数据是来自不同的数据源、对于重复性存放的数据未能进行一致性更新造成。例如,两张表中都存储了用户的电话号码,但在用户的号码发生改变时只更新了一张表中的数据,那么两张表中就有了不一致的数据。
4.重复数据以及含有特殊符号的数据(如#、¥、$、*等)的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号