Spark Sort-Based Shuffle具体实现内幕和源码详解
为什么讲解Sorted-Based shuffle?2方面的原因:
一,可能有些朋友看到Sorted-Based Shuffle的时候,会有一个误解,认为Spark基于Sorted-Based Shuffle 它产出的结果是有序的。
二,Sorted-Based Shuffle要排序,涉及到一个排序算法。
Sorted-Based Shuffle 的核心是借助于 ExternalSorter 把每个 ShuffleMapTask 的输出,排序到一个文件中 (FileSegmentGroup),为了区分下一个阶段 Reducer Task 不同的内容,它还需要有一个索引文件 (Index) 来告诉下游 Stage 的并行任务,哪一部份是属于你的。
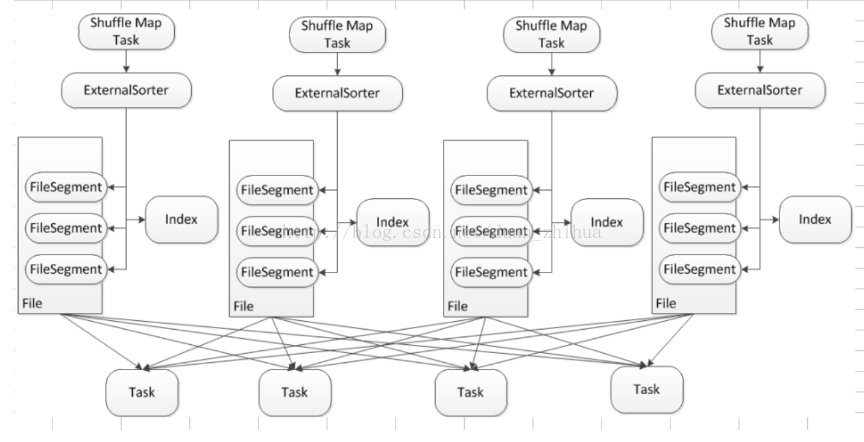
Shuffle Map Task 在ExternalSorter 溢出到磁盘的时候,产生一组 File (File Group是hashShuffle中的概念,理解为一个file文件池,这里为区分,使用File的概念,FileSegment根据PartionID排序)和 一个索引文件,File 里的 FileSegement 会进行排序,在 Reducer 端有4个Reducer Task,下游的 Task 可以很容易跟据索引 (index) 定位到这个 Fie 中的哪部份 FileSegement 是属于下游的,它相当于一个指针,下游的 Task 要向 Driver 去碓定文件在那里,然后到了这个 File 文件所在的地方,实际上会跟 BlockManager 进行沟通,BlockManager 首先会读一个 Index 文件,根据它的命名则进行解析,比如说下一个阶段的第一个 Task,一般就是抓取第一个 Segment,这是一个指针定位的过程。
再次强调 Sort-Based Shuffle 最大的意义是减少临时文件的输出数量,且只会产生两个文件:一个是包含不同内容划分成不同 FileSegment 构成的单一文件 File,另外一个是索引文件 Index。
一件很重要的事情:在Sorted-Shuffle中会排序吗?从测试的结果来看,结果一般不排序。(例如我们可以在spark2.0中做一个wordcount测试,结果是不排序的)
Sort-Based Shuffle Mapper端的 Sort and Spill 的过程 (ApependOnlyMap时不进行排序,Spill 到磁盘的时候再进行排序的)
现在我们从源码的角度去看看到底Sorted-Based Shuffle这个排序实际上是在干什么的。
SparkEnv.scala:默认情况是sort类型,全称org.apache.spark.shuffle.sort.SortShuffleManager
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
进入org.apache.spark.shuffle.sort.SortShuffleManager,我们怎么去看这个源代码,再看一下上面的架构图

SortShuffleManager中没找到这个ExternalSorter,那我们从ShuffleMapTask中去看怎么写数据的。
看一下ShuffleMapTask中runTask的writer
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
manager = SparkEnv.get.shuffleManager是从SparkEnv中通过反射的获取的shuffleManager,就是SortShuffleManager。那 manager.getWriter是SortShuffleManager的getWriter
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
SortShuffleManager getWriter Handle提供的三种方式
- unsafeShuffleHandle : tungsten深度优化的方式
- bypassMergeSortHandle:Sorted-Shuffle在一定程度上可以退化为hashShuffle的方式
- BaseShuffleHandle:是SortShuffleWriter
再回到之前ShuffleMapTask中,获取shufflemanager getWriter之后,要write写数据。
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
那我们看SortShuffleWriter的write方法(idea按ctrl+F12),代码是非常清晰,简洁的。经过千辛万苦,一步一步追踪,我们终于看到了
ExternalSorter
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
ExternalSorter.scala中有2个很重要的数据结构:
// Data structures to store in-memory objects before we spill. Depending on whether we have an
// Aggregator set, we either put objects into an AppendOnlyMap where we combine them, or we
// store them in an array buffer.
@volatile private var map = new PartitionedAppendOnlyMap[K, C]
@volatile private var buffer = new PartitionedPairBuffer[K, C]
1,在map端进行combine:PartitionedAppendOnlyMap 是map类型的数据结构,map是key-value ,在本地进行聚合,在本地key值不变,Value不断进行更新;PartitionedAppendOnlyMap 底层还是一个数组,基于数组实现map的原因是更节省空间,效率更高。那么直接基于数组怎么实现map:把数组的标记 0 1 2 3 4 .。。。把偶数设置为map的key值,把奇数设置为map的value值。
2,在map端没有combine:使用PartitionedPairBuffer
看一下insertAll方法:
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
首先判断是否聚合shouldCombine:
1,如果聚合,map.changeValue此时key不变,在历史value基础上进行combine。
2,没有聚合,直接在buffer数据结构中插入一条记录。
注意:这个时候没有排序。
继续回到SortShuffleWriter的write方法:
根据dep.shuffleId, mapId获取输出文件output
写数据 根据dep.shuffleId, mapId, partitionLengths, tmp,tmp是中间临时文件写入文件和更新索引。
task运行结束以后返回的mapStatus数据结构,告诉数据放在哪里。
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
我们看一下writePartitionedFile,分别实现了spill和不spill怎么做。
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics)
if (spills.isEmpty) {
// Case where we only have in-memory data
val collection = if (aggregator.isDefined) map else buffer
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
val segment = writer.commitAndGet()
lengths(partitionId) = segment.length
}
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
val segment = writer.commitAndGet()
lengths(id) = segment.length
}
}
}
writer.close()
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
lengths
}
大家看一下里面有没有排序的事情?可能没有看见,里面有一句很关键的代码:val it = collection.destructiveSortedWritablePartitionedIterator(comparator),生成一个it WritablePartitionedIterator写数据
那我们看一下WritablePartitionedPairCollection
private[spark] trait WritablePartitionedPairCollection[K, V] {
/**
* Insert a key-value pair with a partition into the collection
*/
def insert(partition: Int, key: K, value: V): Unit
/**
* Iterate through the data in order of partition ID and then the given comparator. This may
* destroy the underlying collection.
*/
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)]
这个地方看到了排序:以partition ID进行排序,实现快速的写,方便的读操作;关键的一点对KEY进行操作。
看一下继承结构PartitionedAppendOnlyMap
/**
* Implementation of WritablePartitionedPairCollection that wraps a map in which the keys are tuples
* of (partition ID, K)
*/
private[spark] class PartitionedAppendOnlyMap[K, V]
extends SizeTrackingAppendOnlyMap[(Int, K), V] with WritablePartitionedPairCollection[K, V] {
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
destructiveSortedIterator(comparator)
}
def insert(partition: Int, key: K, value: V): Unit = {
update((partition, key), value)
}
}
点击destructiveSortedIterator
/**
* Return an iterator of the map in sorted order. This provides a way to sort the map without
* using additional memory, at the expense of destroying the validity of the map.
*/
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = {
destroyed = true
// Pack KV pairs into the front of the underlying array
var keyIndex, newIndex = 0
while (keyIndex < capacity) {
if (data(2 * keyIndex) != null) {
data(2 * newIndex) = data(2 * keyIndex)
data(2 * newIndex + 1) = data(2 * keyIndex + 1)
newIndex += 1
}
keyIndex += 1
}
assert(curSize == newIndex + (if (haveNullValue) 1 else 0))
new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
new Iterator[(K, V)] {
var i = 0
var nullValueReady = haveNullValue
def hasNext: Boolean = (i < newIndex || nullValueReady)
def next(): (K, V) = {
if (nullValueReady) {
nullValueReady = false
(null.asInstanceOf[K], nullValue)
} else {
val item = (data(2 * i).asInstanceOf[K], data(2 * i + 1).asInstanceOf[V])
i += 1
item
}
}
}
}
里面的关键的地方有一个new Sorter
class Sorter[K, Buffer](private val s: SortDataFormat[K, Buffer]) {
private val timSort = new TimSort(s)
/**
* Sorts the input buffer within range [lo, hi).
*/
def sort(a: Buffer, lo: Int, hi: Int, c: Comparator[_ >: K]): Unit = {
timSort.sort(a, lo, hi, c)
}
}
sorter里面使用的是timSort算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号