深度剖析Spark分布式执行原理
转载自:https://zhuanlan.zhihu.com/p/25772054
让代码分布式运行是所有分布式计算框架需要解决的最基本的问题。
Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如何处理代码分布式执行问题的资料少之又少,这也是我撰写文本的目的。
Spark运行在JVM之上,任务的执行依赖序列化及类加载机制,因此本文会重点围绕这两个主题介绍Spark对代码分布式执行的处理。本文假设读者对Spark、Java、Scala有一定的了解,代码示例基于Scala,Spark源码基于2.1.0版本。阅读本文你可以了解到:
- Java对象序列化机制
- 类加载器的作用
- Spark对closure序列化的处理
- Spark Application的class是如何加载的
- Spark REPL(spark-shell)中的代码是如何分布式执行的
根据以上内容,读者可以基于JVM相关的语言构建一个自己的分布式计算服务框架。
Java对象序列化
序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。所谓的状态信息指的是对象在内存中的数据,Java中一般指对象的字段数据。我们开发Java应用的时候或多或少都处理过对象序列化,对象常见的序列化形式有JSON、XML等。
JDK中内置一个ObjectOutputStream类可以将对象序列化为二进制数据,使用ObjectOutputStream序列化对象时,要求对象所属的类必须实现java.io.Serializable接口,否则会报java.io.NotSerializableException的异常。
基本的概念先介绍到这。接下来我们一起探讨一个问题:Java的方法能否被序列化?
假设我们有如下的SimpleTask类(Java类):
import java.io.Serializable; public abstract class Task implements Serializable { public void run() { System.out.println("run task!"); } } public class SimpleTask extends Task { @Override public void run() { System.out.println("run simple task!"); } }
还有一个用于将对象序列化到文件的工具类FileSerializer:
import java.io.{FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream} object FileSerializer { def writeObjectToFile(obj: Object, file: String) = { val fileStream = new FileOutputStream(file) val oos = new ObjectOutputStream(fileStream) oos.writeObject(obj) oos.close() } def readObjectFromFile(file: String): Object = { val fileStream = new FileInputStream(file) val ois = new ObjectInputStream(fileStream) val obj = ois.readObject() ois.close() obj } }
简单起见,我们采用将对象序列化到文件,然后通过反序列化执行的方式来模拟代码的分布式执行。SimpleTask就是我们需要模拟分布式执行的代码。我们先将SimpleTask序列化到文件中:
val task = new SimpleTask() FileSerializer.writeObjectToFile(task, "task.ser")
然后将SimpleTask类从我们的代码中删除,此时只有task.ser文件中含有task对象的序列化数据。接下来我们执行下面的代码:
val task = FileSerializer.readObjectFromFile("task.ser").asInstanceOf[Task]
task.run()
请各位读者思考,上面的代码执行后会出现什么样的结果?
- 输出:run simple task! ?
- 输出:run task! ?
- 还是会报错?
实际执行会出现形如下面的异常:
Exception in thread "main" java.lang.ClassNotFoundException: site.stanzhai.serialization.SimpleTask at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at java.io.ObjectInputStream.resolveClass(ObjectInputStream.java:628) at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1620) at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1781) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1353) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:373) at site.stanzhai.serialization.FileSerializer$.readObjectFromFile(FileSerializer.scala:20)
从异常信息来看,反序列过程中找不到SimpleTask类。由此可以推断序列化后的数据是不包含类的定义信息的。那么,ObjectOutputStream到底序列化了哪些信息呢?
对ObjectOutputStream实现机制感兴趣的同学可以去看下JDK中这个类的实现,ObjectOutputStream序列化对象时,从父类的数据开始序列化到子类,如果override了writeObject方法,会反射调用writeObject来序列化数据。序列化的数据会按照以下的顺序以二进制的形式输出到OutputStream中:
- 类的descriptor(仅仅是类的描述信息,不包含类的定义)
- 对象的primitive类型数据(int,boolean等,String和Array是特殊处理的)
- 对象的其他obj数据
回到我们的问题上:Java的方法能否被序列化?通过我们代码示例及分析,想必大家对这个问题应该清楚了。通过ObjectOutputStream序列化对象,仅包含类的描述(而非定义),对象的状态数据,由于缺少类的定义,也就是缺少SimpleTask的字节码,反序列化过程中就会出现ClassNotFound的异常。
如何让我们反序列化的对象能正常使用呢?我们还需要了解类加载器。
类加载器:ClassLoader
ClassLoader在Java中是一个抽象类,ClassLoader的作用是加载类,给定一个类名,ClassLoader会尝试查找或生成类的定义,一种典型的加载策略是将类名对应到文件名上,然后从文件系统中加载class file。
在我们的示例中,反序列化SimpleTask失败,是因为JVM找不到类的定义,因此要确保正常反序列化,我们必须将SimpleTask的class文件保存下来,反序列化的时候能够让ClassLoader加载到SimpleTask的class。
接下来,我们对代码做一些改造,添加一个ClassManipulator类,用于将对象的class文件导出到当前目录的文件中,默认的文件名就是对象的类名(不含包名):
object ClassManipulator { def saveClassFile(obj: AnyRef): Unit = { val classLoader = obj.getClass.getClassLoader val className = obj.getClass.getName val classFile = className.replace('.', '/') + ".class" val stream = classLoader.getResourceAsStream(classFile) // just use the class simple name as the file name val outputFile = className.split('.').last + ".class" val fileStream = new FileOutputStream(outputFile) var data = stream.read() while (data != -1) { fileStream.write(data) data = stream.read() } fileStream.flush() fileStream.close() } }
按照JVM的规范,假设对package.Simple这样的一个类编译,编译后的class文件为package/Simple.class,因此我们可以根据路径规则,从当前JVM进程的Resource中得到指定类的class数据。
在删除SimpleTask前,我们除了将task序列化到文件外,还需要将task的class文件保存起来,执行完下面的代码,SimpleTask类就可以从代码中剔除了:
val task = new SimpleTask() FileSerializer.writeObjectToFile(task, "task.ser") ClassManipulator.saveClassFile(task)
由于我们保存class文件的方式比较特殊,既不在jar包中,也不是按package/ClassName.class这种标准的保存方式,因此还需要实现一个自定义的FileClassLoader按照我们保存class文件的方式来加载所需的类:
class FileClassLoader() extends ClassLoader { override def findClass(fullClassName: String): Class[_] = { val file = fullClassName.split('.').last + ".class" val in = new FileInputStream(file) val bos = new ByteArrayOutputStream val bytes = new Array[Byte](4096) var done = false while (!done) { val num = in.read(bytes) if (num >= 0) { bos.write(bytes, 0, num) } else { done = true } } val data = bos.toByteArray defineClass(fullClassName, data, 0, data.length) } }
ObjectInputStream类用于对象的反序列化,在反序列化过程中,它根据序列化数据中类的descriptor信息,调用resolveClass方法加载对应的类,但是通过Class.forName加载class使用的并不是我们自定义的FileClassLoader,所以如果直接使用ObjectInputStream进行反序列,依然会因为找不到类而报错,下面是resolveClass的源码:
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException, ClassNotFoundException { String name = desc.getName(); try { return Class.forName(name, false, latestUserDefinedLoader()); } catch (ClassNotFoundException ex) { Class<?> cl = primClasses.get(name); if (cl != null) { return cl; } else { throw ex; } } }
为了能让ObjectInputStream在序列化的过程中使用我们自定义的ClassLoader,我们还需要对FileSerializer中的readObjectFromFile方法做些改造,修改的代码如下:
def readObjectFromFile(file: String, classLoader: ClassLoader): Object = { val fileStream = new FileInputStream(file) val ois = new ObjectInputStream(fileStream) { override def resolveClass(desc: ObjectStreamClass): Class[_] = Class.forName(desc.getName, false, classLoader) } val obj = ois.readObject() ois.close() obj }
最后,我们将反序列化的代码调整为:
val fileClassLoader = new FileClassLoader() val task = FileSerializer.readObjectFromFile("task.ser", fileClassLoader).asInstanceOf[Task] task.run()
反序列化的过程中能够通过fileClassLoader加载到所需的类,这样我们在执行就不会出错了,最终的执行结果为:run simple task!。到此为止,我们已经完整地模拟了代码分布式执行的过程。完整的示例代码,请参阅:https://github.com/stanzhai/jvm-exercise/tree/master/src/main/scala/site/stanzhai/exercise/serialization
Spark对closure序列化的处理
我们依然通过一个示例,快速了解下Scala对闭包的处理,下面是从Scala的REPL中执行的代码:
scala> val n = 2 n: Int = 2 scala> val f = (x: Int) => x * n f: Int => Int = <function1> scala> Seq.range(0, 5).map(f) res0: Seq[Int] = List(0, 2, 4, 6, 8)
f是采用Scala的=>语法糖定义的一个闭包,为了弄清楚Scala是如何处理闭包的,我们继续执行下面的代码:
scala> f.getClass res0: Class[_ <: Int => Int] = class $anonfun$1 scala> f.isInstanceOf[Function1[Int, Int]] res1: Boolean = true scala> f.isInstanceOf[Serializable] res2: Boolean = true
可以看出f对应的类为$anonfun$1是Function1[Int, Int]的子类,而且实现了Serializable接口,这说明f是可以被序列化的。
Spark对于数据的处理基本都是基于闭包,下面是一个简单的Spark分布式处理数据的代码片段:
val spark = SparkSession.builder().appName("demo").master("local").getOrCreate()
val sc = spark.sparkContext
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
val sum = distData.map(x => x * 2).sum()
println(sum) // 30.0
对于distData.map(x => x * 2),map中传的一个匿名函数,也是一个非常简单的闭包,对distData中的每个元素*2,我们知道对于这种形式的闭包,Scala编译后是可以序列化的,所以我们的代码能正常执行也合情合理。将入我们将处理函数的闭包定义到一个类中,然后将代码改造为如下形式:
class Operation { val n = 2 def multiply = (x: Int) => x * n } ... val sum = distData.map(new Operation().multiply).sum() ...
我们在去执行,会出现什么样的结果呢?实际执行会出现这样的异常:
Exception in thread "main" org.apache.spark.SparkException: Task not serializable at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298) ... Caused by: java.io.NotSerializableException: Operation
Scala在构造闭包的时候会确定他所依赖的外部变量,并将它们的引用存到闭包对象中,这样能保证在不同的作用域中调用闭包不出现问题。
出现Task not serializable的异常,是由于我们的multiply函数依赖Operation类的变量n,虽然multiply是支持序列化的,但是Operation不支持序列化,这导致multiply函数在序列化的过程中出现了NotSerializable的异常,最终导致我们的Task序列化失败。为了确保multiply能被正常序列化,我们需要想办法去除对Operation的依赖,我们将代码做如下修改,在去执行就可以了:
class Operation { def multiply = (x: Int) => x * 2 } ... val sum = distData.map(new Operation().multiply).sum() ...
Spark对闭包序列化前,会通过工具类org.apache.spark.util.ClosureCleaner尝试clean掉闭包中无关的外部对象引用,ClosureCleaner对闭包的处理是在运行期间,相比Scala编译器,能更精准的去除闭包中无关的引用。这样做,一方面可以尽可能保证闭包可被序列化,另一方面可以减少闭包序列化后的大小,便于网络传输。
我们在开发Spark应用的时候,如果遇到Task not serializable的异常,就需要考虑下,闭包中是否或引用了无法序列化的对象,有的话,尝试去除依赖就可以了。
Spark中实现的序列化工具有多个:

从SparkEnv类的实现来看,用于闭包序列化的是JavaSerializer:
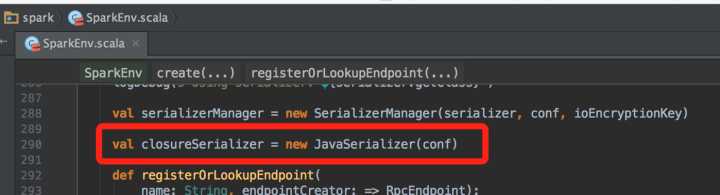
JavaSerializer内部使用的是ObjectOutputStream将闭包序列化:
private[spark] class JavaSerializationStream( out: OutputStream, counterReset: Int, extraDebugInfo: Boolean) extends SerializationStream { private val objOut = new ObjectOutputStream(out) ... }
将闭包反序列化的核心代码为:
private[spark] class JavaDeserializationStream(in: InputStream, loader: ClassLoader) extends DeserializationStream { private val objIn = new ObjectInputStream(in) { override def resolveClass(desc: ObjectStreamClass): Class[_] = try { Class.forName(desc.getName, false, loader) } catch { case e: ClassNotFoundException => JavaDeserializationStream.primitiveMappings.getOrElse(desc.getName, throw e) } } ... }
关于ObjectInputStream我们前面已有介绍,JavaDeserializationStream有个关键的成员变量loader,它是个ClassLoader,可以让Spark使用非默认的ClassLoader按照自定义的加载策略去加载class,这样才能保证反序列化过程在其他节点正常进行。
通过前面的介绍,想要代码在另一端执行,只有序列化还不行,还需要保证执行端能够加载到闭包对应的类。接下来我们探讨Spark加载class的机制。
Spark Application的class是如何加载的
通常情况下我们会将开发的Spark Application打包为jar包,然后通过spark-submit命令提交到集群运行,下面是一个官网的示例:
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ ... \ --jars /path/to/dep-libs.jar \ /path/to/examples.jar \
此时,我们编写的代码中所包含的闭包,对应的类已经被编译到jar包中了,所以Executor端只要能加载到这个jar包,从jar包中定位闭包的class文件,就可以将闭包反序列化了。事实上Spark也是这么做的。
Spark Application的Driver端在运行的时候会基于netty建立一个文件服务,我们运行的jar包,及--jars中指定的依赖jar包,会被添加到文件服务器中。这个过程在SparkContext的addJar方法中完成:
/** * Adds a JAR dependency for all tasks to be executed on this SparkContext in the future. * The `path` passed can be either a local file, a file in HDFS (or other Hadoop-supported * filesystems), an HTTP, HTTPS or FTP URI, or local:/path for a file on every worker node. */ def addJar(path: String) { if (path == null) { logWarning("null specified as parameter to addJar") } else { var key = "" if (path.contains("\\")) { // For local paths with backslashes on Windows, URI throws an exception key = env.rpcEnv.fileServer.addJar(new File(path)) } else { val uri = new URI(path) // SPARK-17650: Make sure this is a valid URL before adding it to the list of dependencies Utils.validateURL(uri) key = uri.getScheme match { // A JAR file which exists only on the driver node case null | "file" => try { env.rpcEnv.fileServer.addJar(new File(uri.getPath)) } catch { case exc: FileNotFoundException => logError(s"Jar not found at $path") null } // A JAR file which exists locally on every worker node case "local" => "file:" + uri.getPath case _ => path } } if (key != null) { val timestamp = System.currentTimeMillis if (addedJars.putIfAbsent(key, timestamp).isEmpty) { logInfo(s"Added JAR $path at $key with timestamp $timestamp") postEnvironmentUpdate() } } } }
Executor端在执行任务的时候,会从任务信息中得到依赖的jar包,然后updateDependencies从Driver端的文件服务器下载缺失的jar包,并将jar包添加到URLClassLoader中,最后再将task反序列化,反序列化前所需的jar都已准备好,因此能够将task中的闭包正常反序列化,核心代码如下:
override def run(): Unit = { ... try { val (taskFiles, taskJars, taskProps, taskBytes) = Task.deserializeWithDependencies(serializedTask) // Must be set before updateDependencies() is called, in case fetching dependencies // requires access to properties contained within (e.g. for access control). Executor.taskDeserializationProps.set(taskProps) updateDependencies(taskFiles, taskJars) task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader) ... } finally { runningTasks.remove(taskId) } }
这么来看,整个Spark Application分布式加载class的机制就比较清晰了。Executor端能够正常加载class,反序列化闭包,分布式执行代码自然就不存在什么问题了。
Spark REPL(spark-shell)中的代码是如何分布式执行的
spark-shell是Spark为我们提供的一个REPL的工具,可以让我们非常方便的写一些简单的数据处理脚本。下面是一个运行在spark-shell的代码:
scala> val f = (x: Int) => x + 1 f: Int => Int = <function1> scala> val data = Array(1, 2, 3, 4, 5) data: Array[Int] = Array(1, 2, 3, 4, 5) scala> val distData = sc.parallelize(data) distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26 scala> distData.map(f).sum() res0: Double = 20.0
我们已知,闭包f会被Scala编译为匿名类,如果要将f序列化到Executor端执行,必须要加载f对应的匿名类的class数据,才能正常反序列化。
Spark是如何得到f的class数据的?Executor又是如何加载到的?
源码面前,了无秘密。我们看一下Spark的repl项目的代码入口,核心代码如下:
object Main extends Logging { ... val rootDir = conf.getOption("spark.repl.classdir").getOrElse(Utils.getLocalDir(conf)) val outputDir = Utils.createTempDir(root = rootDir, namePrefix = "repl") def main(args: Array[String]) { doMain(args, new SparkILoop) } // Visible for testing private[repl] def doMain(args: Array[String], _interp: SparkILoop): Unit = { interp = _interp val jars = Utils.getUserJars(conf, isShell = true).mkString(File.pathSeparator) val interpArguments = List( "-Yrepl-class-based", "-Yrepl-outdir", s"${outputDir.getAbsolutePath}", "-classpath", jars ) ++ args.toList val settings = new GenericRunnerSettings(scalaOptionError) settings.processArguments(interpArguments, true) if (!hasErrors) { interp.process(settings) // Repl starts and goes in loop of R.E.P.L Option(sparkContext).map(_.stop) } } ... }
Spark2.1.0的REPL基于Scala-2.11的scala.tools.nsc编译工具实现,代码已经相当简洁,Spark给interp设置了2个关键的配置-Yrepl-class-based和-Yrepl-outdir,通过这两个配置,我们在shell中输入的代码会被编译为class文件输出到执行的文件夹中。如果指定了spark.repl.classdir配置,会用这个配置的路径作为class文件的输出路径,否则使用SPARK_LOCAL_DIRS对应的路径。下面是我测试过程中输出到文件夹中的class文件:
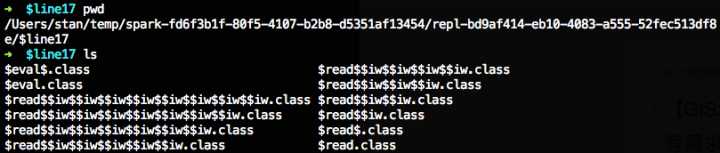
我们已经清楚Spark如何将shell中的代码编译为class了,那么Executor端,如何加载到这些class文件呢?在org/apache/spark/executor/Executor.scala中有段和REPL相关的代码:
private val urlClassLoader = createClassLoader() private val replClassLoader = addReplClassLoaderIfNeeded(urlClassLoader) /** * If the REPL is in use, add another ClassLoader that will read * new classes defined by the REPL as the user types code */ private def addReplClassLoaderIfNeeded(parent: ClassLoader): ClassLoader = { val classUri = conf.get("spark.repl.class.uri", null) if (classUri != null) { logInfo("Using REPL class URI: " + classUri) try { val _userClassPathFirst: java.lang.Boolean = userClassPathFirst val klass = Utils.classForName("org.apache.spark.repl.ExecutorClassLoader") .asInstanceOf[Class[_ <: ClassLoader]] val constructor = klass.getConstructor(classOf[SparkConf], classOf[SparkEnv], classOf[String], classOf[ClassLoader], classOf[Boolean]) constructor.newInstance(conf, env, classUri, parent, _userClassPathFirst) } catch { case _: ClassNotFoundException => logError("Could not find org.apache.spark.repl.ExecutorClassLoader on classpath!") System.exit(1) null } } else { parent } } override def run(): Unit = { ... Thread.currentThread.setContextClassLoader(replClassLoader) val ser = env.closureSerializer.newInstance() ... }
Executor启动时会判断是否为REPL模式,如果是的话会使用ExecutorClassLoader做为反序列闭包时所使用的ClassLoader,ExecutorClassLoader会通过网络从Driver端(也就是执行spark-shell的节点)加载所需的class文件。这样我们在spark-shell中写的代码就可以分布式执行了。
总结
Spark实现代码的分布式执行有2个关键点:
- 对象必须可序列化
- Executor端能够加载到所需类的class文件,保证反序列化过程不出错,这点通过自定义的ClassLoader来保障
满足以上2个条件,我们的代码就可以分布式运行了。
当然,构建一个完整的分布式计算框架,还需要有网络通信框架、RPC、文件传输服务等作为支撑,在了解Spark代码分布式执行原理的基础上,相信读者已有思路基于JVM相关的语言构建分布式计算服务。
类比其他非JVM相关的语言,实现一个分布式计算框架,依然是需要解决序列化,动态加载执行代码的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号