Spark预准备环境、源码剖析(转载)
链接:https://zhuanlan.zhihu.com/p/85105155
一个JOB提交到spark集群中时候,需要预准备一些环境变量这里涉及到主要三个关键词:
SparkContext,SparkConf,SparkSession
Spark版本历史演进中非常重要的一个节点是Spark2.0的到来,其中不仅仅是通信机制彻底更新,而且Spark启动方式做彻底分调整。那么其中就涉及到了SparkContext到SparkSession的转变。
Spark2.0之前,SparkContext是所有Spark功能结构,驱动器(Dirver)通过SparkContext连接到集群。创建一个SparkContext代码如下:
from pyspark import SparkConf,SparkContext val conf = SparkConf().setAppName("app").setMaster('local') val sc = SparkContext(conf=conf)
其中SparkConf是配置入口,setAppName是设置Application的名称,setMaster设置运行模式(“local”,“yarn”.etc)
Spark2.0之后版本,引入了一个新入口SparkSession,其中还有新版本的Dataset和之前的DataFrame的使用,但是也同时保留了SparkContext。创建一个SparkSession代码如下:
val spark = SparkSession.builder.appName('testSQL')\ .config('spark.some.config.option','some-value')\ .getOrCreate()
如果要使用SparkContext的API
spark.sparkContext.uiWebUrl
拓扑关系图

Application:用户编写的Spark应用程序,Driver 即运行上述 Application 的 main() 函数并且创建 SparkContext。
SparkSession:SparkContext,SqlContext,HiveContext,Stream等API统一入口
SparkContext:整个应用的上下文,控制应用的生命周期。
RDD:不可变的数据集合,可由 SparkContext 创建,是 Spark 的基本计算单元。
今天继续学习,翻阅到一张时序图讲的很清楚如下:
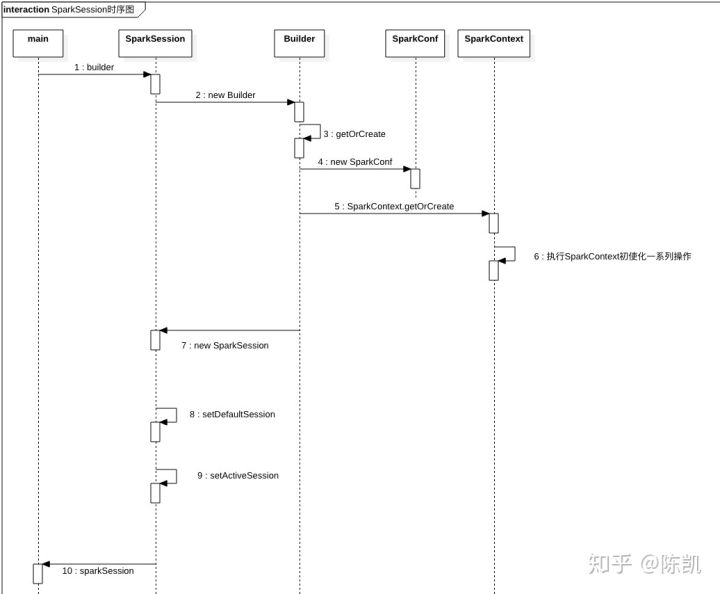
【上面是阐述三个关键词,下面开始三个关键词源码阅读剖析】
SparkSession源码阅读
上面创建SparkSession代码中
val spark = SparkSession.builder.appName('testSQL')\ .config('spark.some.config.option','some-value')\ .getOrCreate()
源码路径如下



首先Builder用来创建SparkSession实例,Builder类是一个内部类,Builder类继承了Logging日志,同时加载了一些外部规则。spark的一些外部的扩展点(分析规则,检查分析规则,优化器规则,规划策略,自定义解析器,(外部)目录侦听器)
private[this] val extensions = new SparkSessionExtensions
核心方法之-appName,设置Application名称,其实通过config方法指定key“spark.app.name”创建设置

核心方法之-master,设置Spark的Mater的URL连接。例如“local”,“local[4]”本地运行4cores,“spark://master:7977”用来运行Spark的standalone集群等

核心方法之-getOrCreate,如果没有SparkSession实例则创建一个,如果存在则获取当前SparkSession实例。
这个方法首先检查是否有一个有效的线程本地SparkSession,如果是,返回那个然后它检查是否有一个有效的全局默认SparkSession,如果是,返回那个。如果没有有效的全局缺省SparkSession,该方法将创建一个新的SparkSession,并将新创建的SparkSession分配为全局默认值。如果返回现有的SparkSession,则该构建器中指定的配置选项将应用于现有的SparkSession。

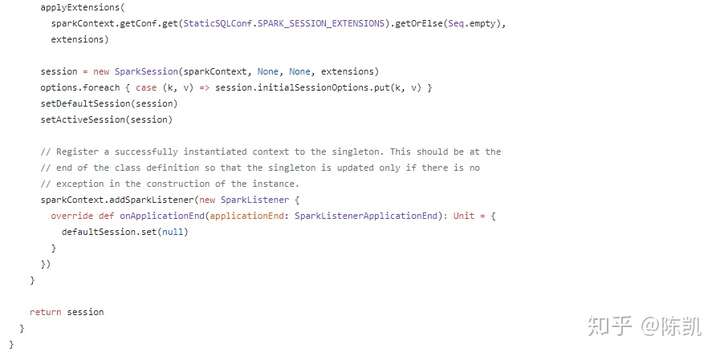
核心方法之-enableHiveSupport,支持Hive,“including connectivity to a persistent Hive metastore”包括到持久化配置单元元存储的连接;“ support for Hive serdes”支持使用Hive serdes;“Hive user-defined functions”Hive的自定义函数。
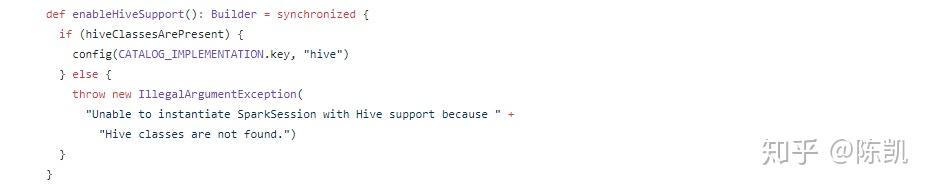
核心方法之-config,这个方法有五个重载(Overload)
1,config(key: String, value: String),创建key和value均为String类型的builder

2,config(key: String, value: Long),创建key为String,value为Long类型的builder
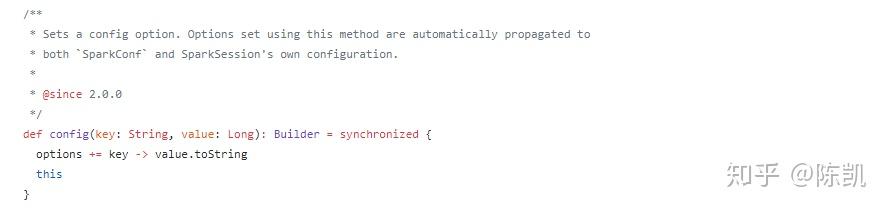
3,config(key: String, value: Double),创建key为String,value为Double类型的builder
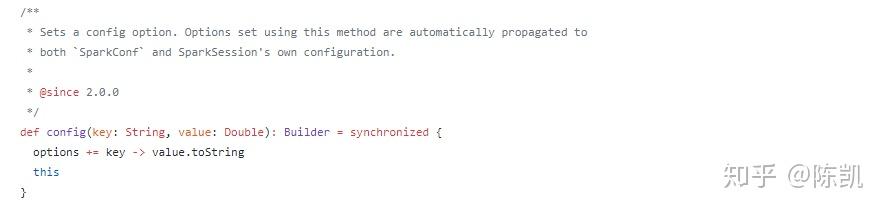
4,config(key: String, value: Boolean),创建key为String,value为Boolean类型的builder

5,config(conf: SparkConf),基于一个由option集合构成的SparkConf创建Builder

SparkSession有个核心方法conf(conf: SparkConf)则是传入一个SparkConf实例变量。
那么接下来阅读SparkConf源码
源码入口如下:

SparkConf继承了Cloneable,Logging日志和Serializable序列化

Spark的Application中配置类,Spark parameters是以key-value形式配置的。大部分时间我们是通过如下方式创建一个SparkConf实例:
val conf = new SparkConf();
也同时支持链路方式创建SparkConf
new SparkConf().setMaster("local").setAppName("My app")
通过this方式创建默认方式

SparkConf源码中相对比较简单,都是通过key-value方式配置的,其中核心方法如下所示:
核心方法之-setAppName(name: String),设置Application的名称,这个会在SparkUI显示中出现

核心方法之-setMaster(master: String),设置Spark的Mater的URL连接。例如“local”,“local[4]”本地运行4cores,“spark://master:7977”用来运行Spark的standalone集群等

核心方法之-setJars(jars: Seq[String]),设置分布式存储jars包路径,这里的jar一定是分布式的,因为在执行过程中是分布式的。同时Java-friendly version的方式另外一个重载方法setJars(jars: Array[String]),实则jars.toSeq转为Seq然后调用setJars(jars: Seq[String])


核心方法之-set(key: String, value: String),设置指定key-value的配置

核心方法之-contains(key: String),判断指定key参数是否存在,返回boolean类型结果

核心方法之-get(key: String),根据指定key参数,获取对应的value值,如果SparkConf中不存在该key参数,则抛出NoSuchElementException

核心方法之-get(key: String, defaultValue: String),根据指定key参数,获取对应的value值,如果SparkConf中不存在该key参数,怎返回defaultValue
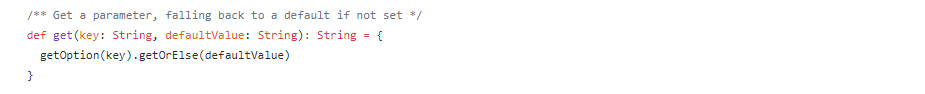
核心方法之-getExecutorEnv,获取所有执行executor环境参数,在SparkConf中配置的一个set集合。

其中是通过getAllWithPrefix获取

核心方法之-getAll,获取所有参数,返回一个Array类型key-value的集合,其中所有设置的参数都是配置在全局变量setting中的,setting是一个哈希Map


核心方法之-getBoolean;getDouble;getInt;getLong,都是根据指定参数key获取对应value,如果SparkConf中不存在该key参数,则返回默认defaultValue,而不同点在于这个defaultValue类型不一样。

核心方法之-getAppId,获取当前Spark的Application的ID。在taskscheduler注册后在Driver程序中有效,并且从executor开始。

SparkContext源码阅读


SparkContext继承了Logging日志类,通过new SparkConf()方式创建实例,SparkContext是Spark功能点的主要入口点。主要集中的功能点是:连接Spark集群,创建RDD,存储器,做广播等,
构造器行为
- 完成对SparkContext的构造
- createSparkEnv
- Started SparkUI
- 注册端点HeartbeatReceiver
- createTaskScheduler
- new DAGScheduler
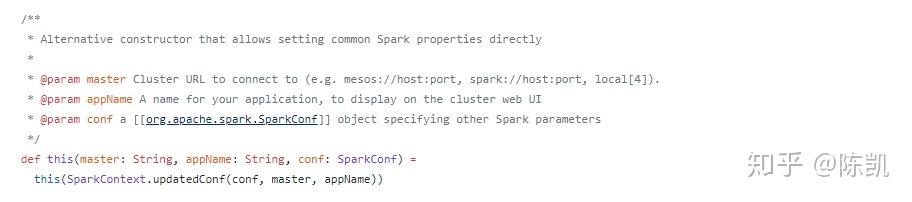
SparkContext如下全局构造器有三个,第一个无参数,后两个是有参去实例化。源码如下

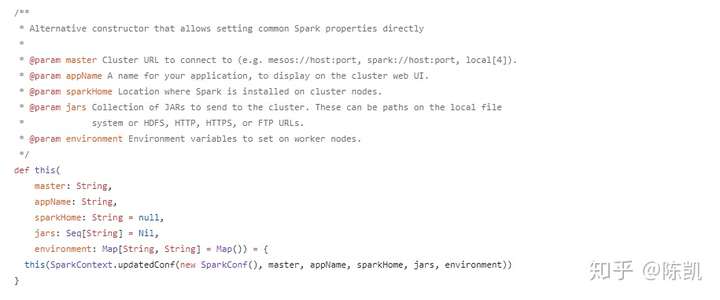
在spark包下构造器有另外三个,源码如下
注:private[spark]表示,只能在spark这个包及子包下使用。这个是scala特有作用域。

SparkContext定义私有属性变量
为何是私有变量,是为了保障运行时候属性是安全的,同时这些私有变量是可变的,因为初始化是要复制这些私有变量。
/* ------------------------------------------------------------------------------------- *
| Private variables. These variables keep the internal state of the context, and are |
| not accessible by the outside world. They're mutable since we want to initialize all |
| of them to some neutral value ahead of time, so that calling "stop()" while the |
| constructor is still running is safe. |
* ------------------------------------------------------------------------------------- */创建SparkEnv
- SparkEnv对象是在这个方法中构造的
- new SecurityManager()
- new NettyRpcEnvFactory()
- 创建NettyRpcEnv
- Utils.startServiceOnPort(启动sparkDriver)
- new BroadcastManager
- 注册端点MapOutputTracker
- ShuffleManager:SortShuffleManager
- 默认内存管理器:UnifiedMemoryManager
- 注册端点MapOutputTracker
- SortShuffleManager
- UnifiedMemoryManager
- 注册端点BlockManagerMaster
- new BlockManager
- 注册端点OutputCommitCoordinator


创建SparkUI

创建任务调度器


构造器入参,SparkContext实例,Master连接方式UI,deployMode方式,返回2元TUPLE
- 根据master配置匹配对应的任务调度器
- 本地模式 local
- 本地模式n个线程 LOCAL_N_REGEX
- standalone模式 SPARK_REGEX
checkResourcesPerTask,每个Task执行任务前做资源监测
- 每个执行器的核心数必须至少满足一个任务要求。
- 确保通过config指定了执行器资源。
- 确保执行器资源足够大,可以启动至少一个任务。
- 比较和更新每个执行器可以提供的最大时隙。
- 上面已经进行了检查,以确保指定了执行器资源,并且如果指定了任何任务资源,则资源足够大。


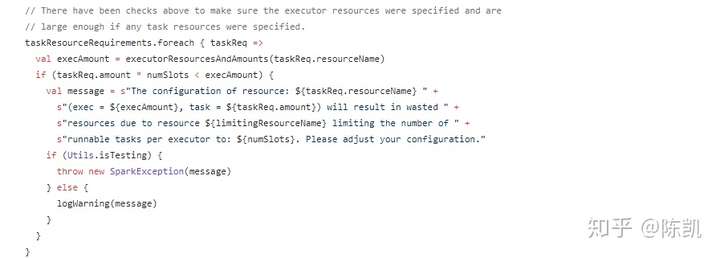
这里依据不同提交模式做了多个分支


分析standalone模式分支的处理方式
SparkContext.createTaskScheduler standalone模式
- 任务调度器 val scheduler = new TaskSchedulerImpl(sc)
- standalone后端调度器 val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
- 调用任务调度器的 initialize(backend) 方法
- 返回(backend, scheduler)

TaskSchedulerImpl.initialize
- 给变量backend 赋值: StandaloneSchedulerBackend
- 匹配调度模式,用schedulableBuilder构建调度池
- 默认FIFO方式

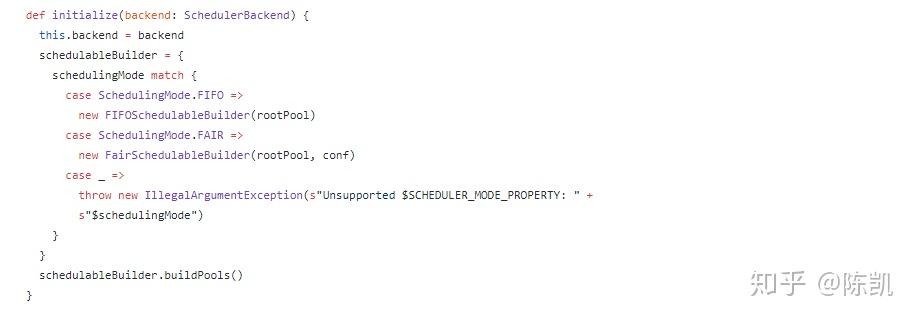
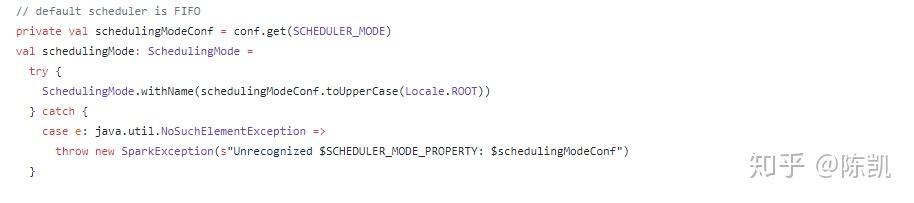
SparkContext 起动任务调度器
- SparkContext.DAGScheduler
- 调用TaskSchedulerImpl.start()函数

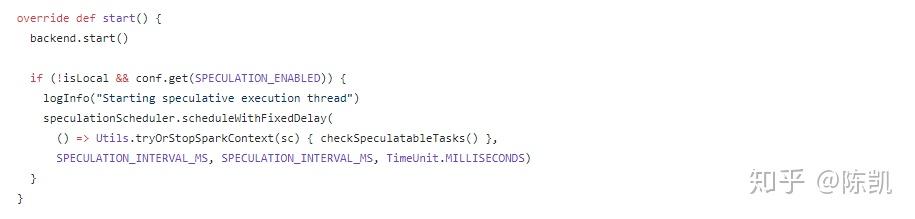
- StandaloneSchedulerBackend.start()
- StandaloneSchedulerBackend extends CoarseGrainedSchedulerBackend
- super.start()调用CoarseGrainedSchedulerBackend.start()函数
- client = new StandaloneAppClient() 实例化StandaloneAppClinet
- client.start() 函数调度
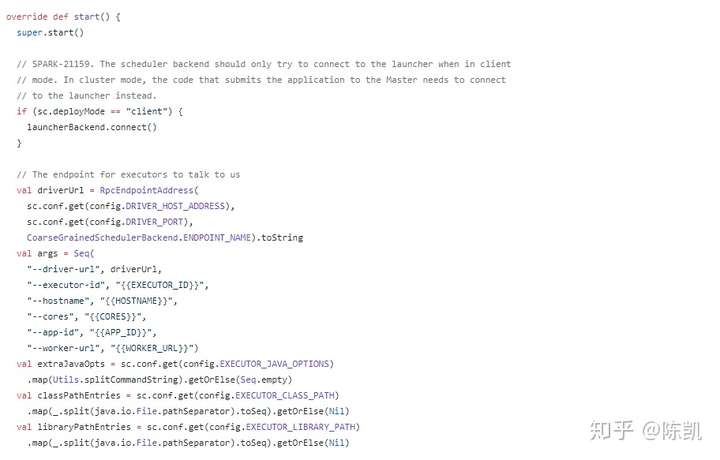
- CoarseGrainedSchedulerBackend.start()
- 注册DriverEndpoint: CoarseGrainedScheduler
- 首先调用DriverEndpoint.OnStart()函数
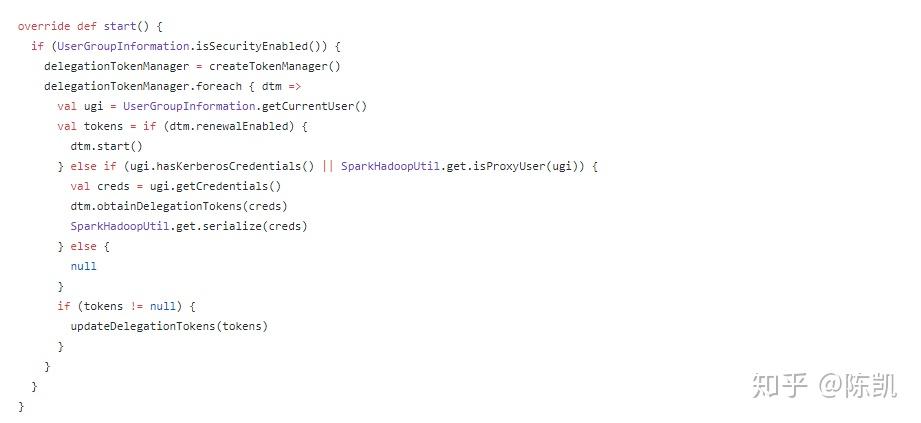
DriverEndpoint.OnStart()函数
- 调用线程池定时任务,默认每隔一秒发送消息:ReviveOffers
- DriverEndpoint.receive()函数对ReviveOffers消息进行处理
- 调用CoarseGrainedSchedulerBackend.DriverEndpoint.makeOffers()函数,为所有的executor分配资源

StandaloneAppClient.start()

- 注册通信端点: AppClient
- 注意,通信端点首先调用OnStart()函数,即调用ClientEndpoint.OnStart()函数,该函数会向master注册应用程序

ClientEndpoint.OnStart()
- 调用函数 registerWithMaster(1)向master注册应用程序
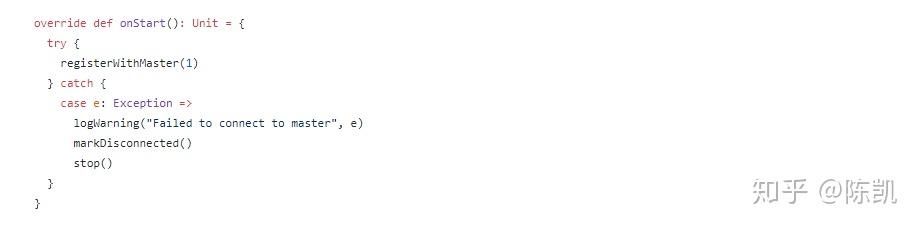
ClientEndpoint.registerWithMaster()
- 调用函数 tryRegisterAllMasters() 向所有master注册应用程序

ClientEndpoint.tryRegisterAllMasters()
- 向所有master发送消息: RegisterApplication()
- 注意 ClientEndpoint 是一个通信端点,函数receive*()也可以接收消息,如接收master发过来的消息:RegisteredApplication

ClientEndpoint.receive()
- 接收master发过来的注册应用程序完成消息: RegisteredApplication
- case RegisteredApplication “Application注册”
- case ApplicationRemoved “Application移除”
- case ExecutorAdded “新增Executor”
- case ExecutorUpdated “Executor更新”
- case WorkerRemoved “Worker移除”
- case MasterChanged “Master变更”


 浙公网安备 33010602011771号
浙公网安备 33010602011771号