spark-submit --files 动态加载外部资源文件
在做spark时,有些时候需要加载资源文件,需要在driver或者worker端访问。在client模式下可以使用IO流直接读取,但是在cluster模式下却不能直接读取,需要如下代码:
val is: InputStream = this.getClass.getResourceAsStream(“./xxx.sql”)
val bufferSource = Source.fromInputStream(is)
这是直接读取classPath路径下的文件,但是cluster模式下,driver有可能不再程序提交的客户端上,以上代码会发生空指针异常。这是,就需要通过--files把外部资源文件加载到classpath路径下。正常情况加载---files filename1,filename2....,当知道外部源文件都是有哪些时,直接列举出来就可以。但是在某些情况下,开发者开发的是一个通用工具,不知到所要加载的是一个什么文件。这时就需要动态加载,我曾尝试过使用--files ../xxx/*.sql,这个可以动态加载指定目录下数据。但是后来发现,这样加载只能加载一个文件,文件夹中超过多余一个文件就会报错。试了很多种方式也没有测试成功。最后通过shell脚本列举文件夹中的文件拼装成字符串,才算完成。
程序打包目录如下: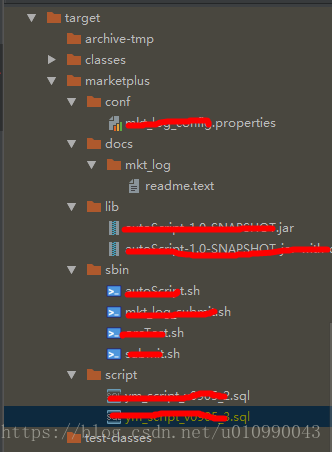
代码实现如下:
##########################################################################################
####由于spark2_submit --files /../*.sql 不能加载多个文件所以只能拼装script路径下的文件####
##########################################################################################
###获取当前项目绝对路径###
#project_home=$(dirname $(readlink -f "$0"))"/.."
project_home="$(readlink -f $(cd "`dirname "$0"`"/..; pwd))"
###获取script绝对路径###
script_path=${project_home}"/script/"
###获取项目中script目录下所有的脚本文件
files=$(ls $script_path);
files=${files// / };
file_arr=($files);
files_str=""
for ele in ${file_arr[*]}
do
file_str=${file_str}${script_path}${ele},
done
len=`expr ${#file_str} - 1`
file_str=`expr substr "$file_str" 1 $len`
echo $file_str
/usr/bin/spark2-submit --executor-memory 15G \
--master yarn \
--queue dataengine \
--files $project_home/script/* \
--executor-cores 5 \
--driver-cores 3 \
--name AutoScript \
--deploy-mode cluster \
--class xx.xx.xxx \
--driver-memory 10G \
--conf "spark.dynamicAllocation.executorIdleTimeout=300" \
--conf "spark.shuffle.file.buffer=16k" \
--conf "spark.yarn.appMasterEnv.JAVA_HOME=/opt/jdk1.8.0_45" \
--conf "spark.dynamicAllocation.minExecutors=11" \
--conf "spark.dynamicAllocation.maxExecutors=11" \
--conf "spark.speculation.quantile=0.85" \
--conf "spark.executorEnv.JAVA_HOME=/opt/jdk1.8.0_45" \
--conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+UseG1GC " \
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC " \
--conf "spark.driver.extraClassPath=/home/sunkl/hive-exec-1.1.0-cdh5.7.6.jar" \
--conf "spark.speculation=true" \
--conf "spark.rpc.askTimeout=400" \
--conf "spark.shuffle.service.enabled=true" \
$project_home/lib/******.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号