HBase在特征工程中的应用
前言
HBase是一款分布式的NoSQL DB,可以轻松扩展存储和读写能力。
主要特性有:
按某精确的key获取对应的value(Get)
通过前缀匹配一段相邻的数据(Scan)
多版本
动态列
服务端协处理器(可以支持用户自定义)
TTL:按时间自动过期
今天我们来聊一聊HBase以上特性在特征工程中的应用,先从最简单的获取一条数据说起:
应用场景介绍
Get
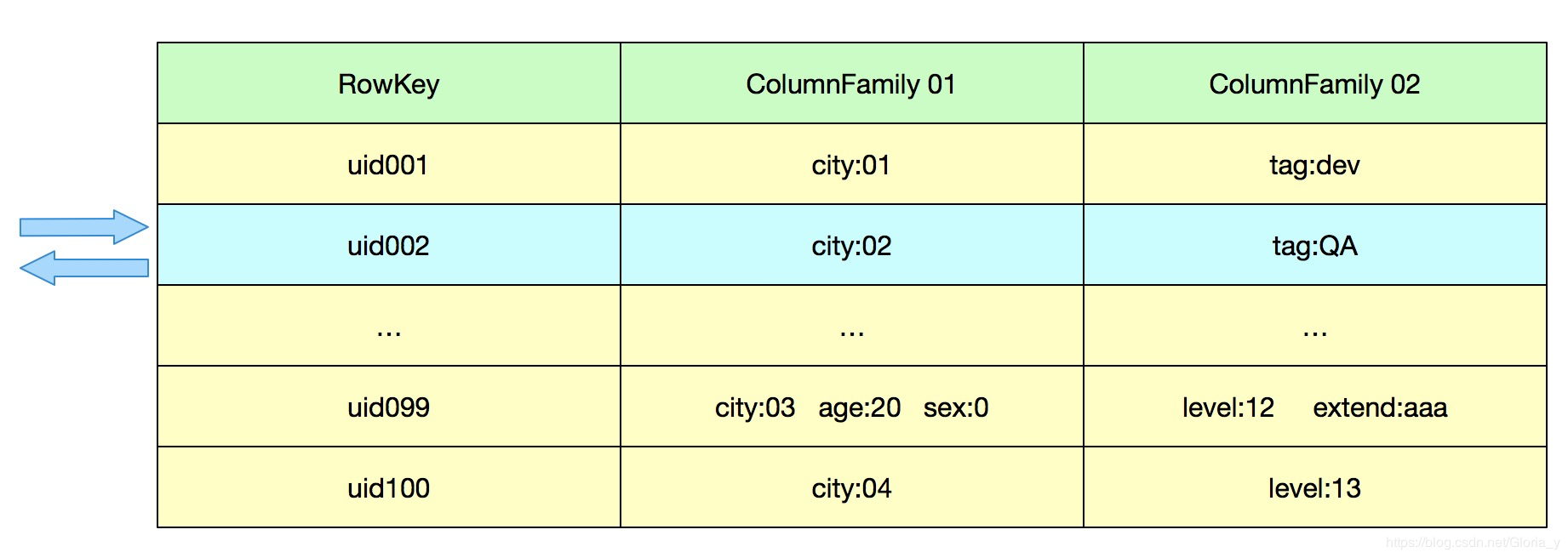
这是HBase中最简单的一个查询操作,根据id读某一个id的属性
比如根据用户id获取这个用户的 城市,年龄,标签等信息
进阶-前缀匹配扫描-Scan
常见场景:
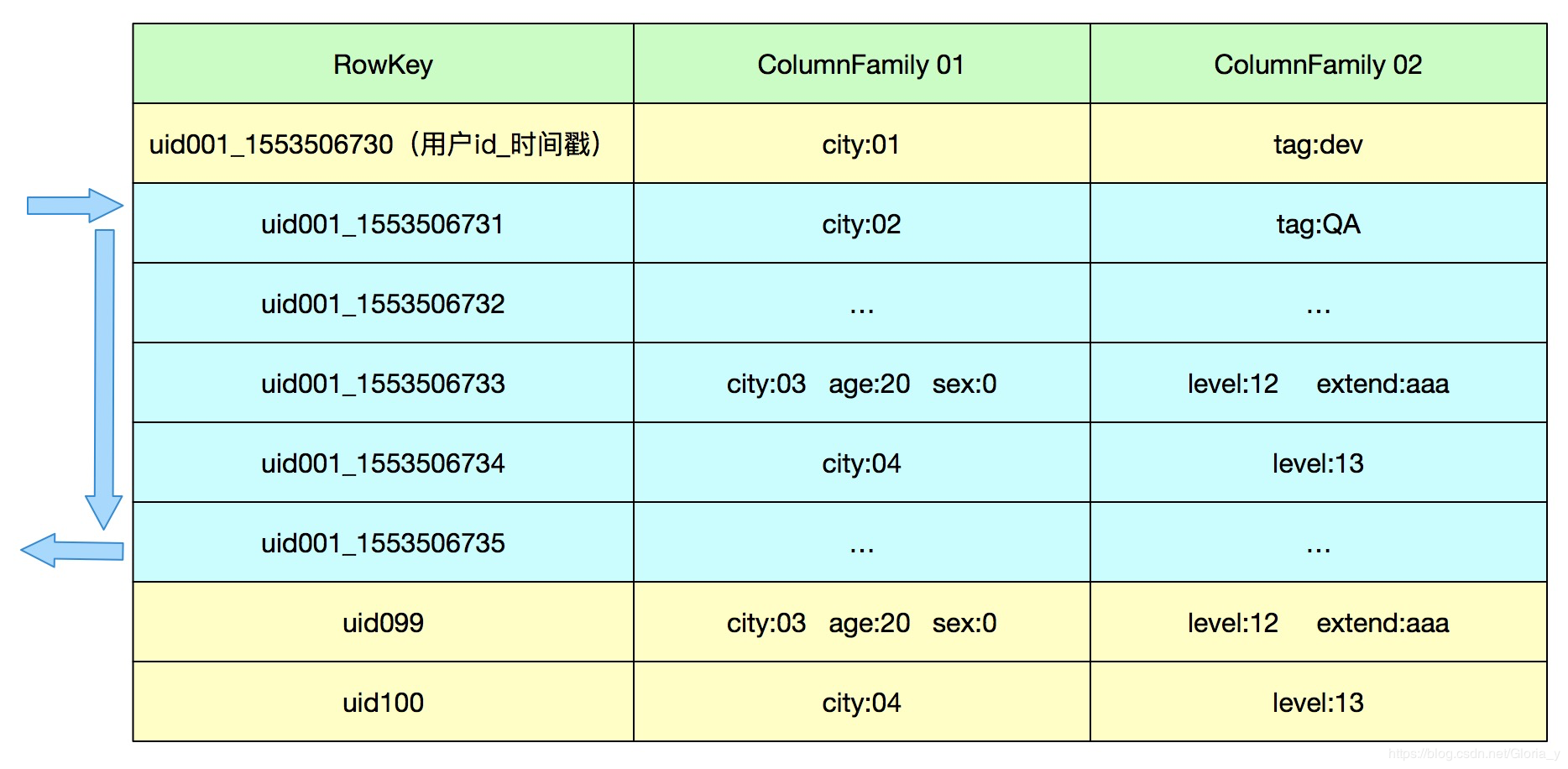
下图是经典的scan用法
hbase中rowkey是按字典序排列
因此非常经典的用法为:
rowkey: 散列(用户id)_时间戳
然后这样就可以通过制定startkey,endkey来扫描一段时间内的数据,并且这些数据是存储在一起的
HBase天生对Scan(扫描)操作有良好的支持,
这里要从HBase的存储特点说起:
NoSQL DB有两种常见的分散数据的方案,一种是按完整的key做hash,数据完全是分散的,另外一种是按Range划分,连续的key存储上是相邻的,这样可以通过在rowkey上做一些业务逻辑的拼接,使得在扫描一定量级逻辑连续的数据的时候,直接扫描的同一块文件下的数据,而不是到分散的各个机器上去查找
HBase选择的是第二种方式来存储数据
1.相邻数据通过scan前缀匹配查询
例如:查某一个用户一个时间段内的数据
2.为scan操作赋能——Filter
可以根据rowkey,列等维度设置过滤器,减少服务端到客户端的数据传输
Tips:过滤器是个好东西,需要的过滤操作在服务端都进行完了,减少了网络传输,只返回符合条件的数据。
但是因为符合条件的数据,可能是在设置的范围中最后一条,所以实际扫描的数据还是Scan的startkey到endkey之间的,还是要注意扫描的范围不要过大
3.使用Scan的正确姿势
经过一定的测试和实践,我们发现持续的进行Scan,稳定可控的并发下,发起Scan,每次Scan 1000条的时候最佳
因为此场景下HBase的RPC队列会得到快速的消费,从而有能力处理新的请求,而不是一直堆积等待一个大的请求的完成
很多同学看到可以做扫描操作,就希望通过扫描操作来查询几百万几千万甚至更多的数据来代替HIVE?
如果是希望一次性读大量数据的时候(比如加载一个月的几百万用户明细数据,或者通过一个月所有用户明细做聚合),不如直接跑离线任务读文件或者使用预聚合的NoSQL 引擎比较好。
短小快的请求则可以通过HBase的cache,文件的index,bloomfilter等特性来施展更多。
Tips:Get就是一个只读一行的小Scan
灵活的动态列
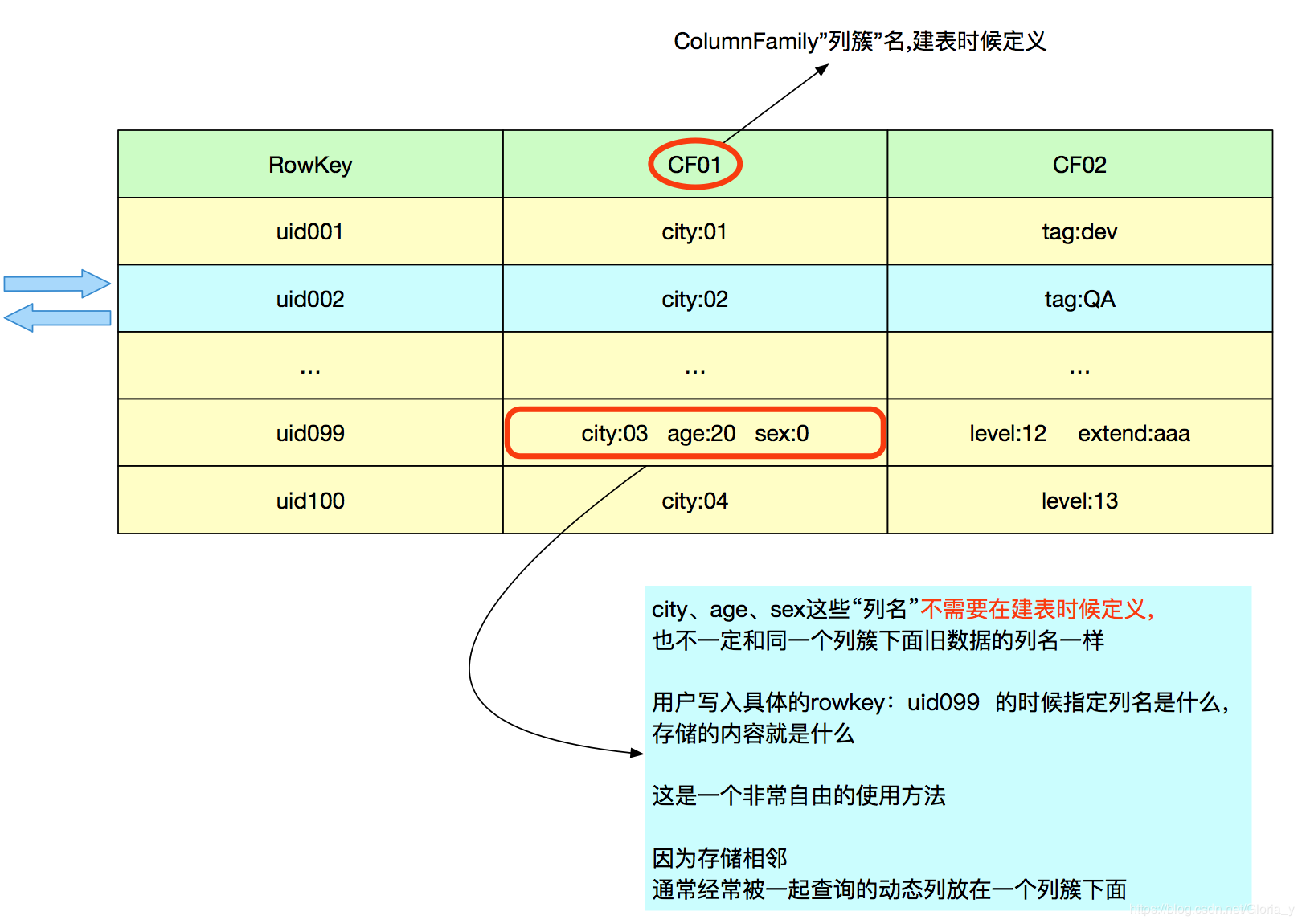
传统数据库以及大部分数据存储需要在建表的时候定义好“字段”,
但是实际应用的时候,比如特征训练中,有很多场景是“字段”或者tag不确定的情况
HBase的动态列则很好的解决了这个问题
1.建表不需要指定列名
2.一次取出一个rowkey所有动态列或者多个动态列
3.也可以table.get( list ),一次获取多个id对应的数据
在实际应用中的使用:
实际应用中,HBase的每一个Column对应一个特征,RowKey的设计为 md5(业务ID)+时间戳,md5用来对ID散列,使数据均匀分布在不同Region上,时间戳用来在SCAN操作时对时间遍历
摘抄自用户的way社区文章:http://way.xiaojukeji.com/article/13662
多版本
HBase中可以查看版本的N个历史版本,通过数据的时间戳实现的
常见场景:
查看某特征随时间变化情况
或者
当发现计算不符合预期的时候,回溯查询某一个id某特征的历史版本
原理简述:
HBase的每条数据都是带时间戳信息的,
会按rowkey,列簇,列,时间戳有序排列,默认会查询到指定的rowkey,列簇,列的最新时间戳的value
而指定查询历史N个版本,就会从最新的数据往前找N个时间戳对应的版本
快照
HBase可以导出快照文件,来进行离线分析
常见场景:
需要获取表中所有数据或者大部分数据的时候,可以通过快照方式,将截止到某一时间的数据文件导出到离线集群,来进行数据分析
原理简述:
数据实时写入HBase,触发快照操作的时候,实时写入的数据会落盘,落盘的文件不会再被修改,HBase内部会记录当前有哪些文件(生成引用),后续可以将快照引用对应的实际数据文件导出到Hadoop进行MR或Spark分析
Tips:导出文件对磁盘IO有一定压力,因此导出操作也是会进行限流的
总结
本文介绍了HBase在特征训练数据存储方面常用的几个特性:Get,Scan,动态列,多版本,以及具体应用场景。
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号