Scala集合(二)
将函数映射到集合
map方法
val names = List("Peter" , "Paul", "Mary")
names.map(_.toUpperCase) // 等同于 for(n <- names) yield n.toUpperCase
flatMap方法,如果函数产出一个集合,又想将所有值串联在一起
def ulcase(s:String) = Vector(s.toUpperCase(), s.toLowerCase())
names.map(ulcase)得到
List(Vector("PETER","peter"), Vector("PAUL","paul"), Vector("MARY","mary"))
names.flatMap(ulcase)得到
List("PETER","peter","PAUL","paul","MARY","mary")
collect 方法用于 partial function,那些并没有对所有可能的输入值进行定义的函数, 产出被定义的所有参数的函数值得集合
"-3+4".collect(case '+' -> 1; case '-' -> -1) // vector(-1,1)
foreach方法
names.foreach(println)
化简、折叠和扫描
List(1,7,2,9).reduceLeft(_ - _)
( ( 1 - 7 ) - 2 ) - 9 = 1- 7 - 2 - 9 = -17
List(1,7,2,9).reduceRight(_ - _)
1 - ( 7 - ( 2 - 9 ) ) = 1-7 + 2 -9 = -13
以不同首元素开始计算
List(1,7,2,9).foldLeft(0)(_ - _)
0-1-7-2-9 = -19
List(1,7,2,9).foldLeft(" ")(_ + _) // 由柯里化判断第二个参数类型定义(String, Int) => String
" " +1 + 7+2+9 = " 1729"
(0 /: List(1,7,2,9))(_ - _) // /: 操作符代替了foldLeft操作
Scala 也提供了foldRight 和 :\的变体
折叠有时可以代替循环,比如计算字母出现频率
val freq = scala.collection.mutable.Map[Char, Int]() // 可变映射
for( c <- "Mississippi")
freq(c) =freq.getOrElse(c,0)+1 // Map('i' ->4, 'M' -> 1, 's' -> 4, 'p' ->2)
折叠实现
(Map[Char, Int]() /:"Mississippi"){
(m,c) => m + (c -> (m.getOrElse(c,0) +1)
}// 这里的 Map是不可变,每次计算出一个新的Map
scanLeft,scanRight, 得到包含所有中间结果的集合
(1 to 10).scanLeft(0)(_ + _)
Vector(0,1,3,6,10,15,21,28,36,45,55)
拉链操作
zip
val prices = List(5.0,20.0,9.95) // 价格
val quantities = List(10,2,1) //数量
prices zip quantities 得到一个List[(Double, Int)] , 一个个对偶的列表
List[(Double, Int)] = List( (5.0, 10), (20.0, 2 ), (9.95, 1))
计算总价
((prices zip quantities) map {p => p._1 * p._2}) sum
如果两个集合数量不一致
List( 5.0, 20.0, 9.95 ) zip List(10, 2) // List((5.0, 10), (20.0, 2))
zipAll 指定短列表的缺省值:第二个参数补充左边,第三个参数补充右边
List(1,1).zipAll(List(2),6,7) // List((1,2),(1,7))
List(1).zipAll(List(2,3),6,7)// List((1,2), (3,6))
zipWithIndex, 返回对偶列表,第二个组成部分是元素下标
"Scala".zipWithIndex // Vector(('S',0),('c',1),('a',2),('l',3),('a',4))
求最大编码的值得下标为
"Scala".zipWithIndex.max._2
迭代器 (相对于集合而言是一个“懒”的替代品,只有在需要时才去取元素,如果不需要更多元素,不会付出计算剩余元素的代价)
对于那些完整构造需要很大开销的集合,适合用迭代器
如Source.fromFile产出一个迭代器,因为整个文件加载进内存不高效。
迭代器的两种用法
while(iter.hasNext)
iter.next()
for(elem <- iter)
对elem操作
上述两种循环都会讲迭代器移动到集合末端,不能再被使用,
调用 map filter count sum length方法后, 迭代器也会位于集合的末端,不能使用
find 或 take ,迭代器位于找到的元素之后
流(stream)
迭代器每次调用next都会改变指向,
如果要缓存之前的值,可以使用流
流是一个尾部被懒计算的不可变列表,也就是说只有需要时才计算
def numsForm(n:BigInt) : Stream[BigInt] = n #:: numsForm(n+1) // #:: 操作符 构建出来的是一个流
var tenOrMore = numsForm(10) // Stream(10,?), 其尾部是未被求值得
tenOrMore.tail.tail.tail // Stream(13,?)
val squares = numsForm(1).map{ x=> x*x) // Stream(1,?)
take 可以一次获得多个值, force强制求值
squares.take(5).force // Stream(1,4,9,16,25)
squares.force // 会尝试对一个无穷流的所有成员求值,最后OutOfMemoryError
迭代器可以用来构造一个流
Source.getLines返回一个Iterator[String],用这个迭代器,对于每一行只能访问一次,而流将缓存访问过的行,允许重新访问
val words = Sourcce.fromFile("/usr/share/dict/words").getLines.toStream
words // Stream(A, ?)
words(5) // Aachen
words // Stream(A, A'o, AOL, AOL's, Aachen, ?)
懒视图(应用于集合)
类似流的懒理念
与流的不同
1、连第一个元素都不会求值
2、不会缓存求过的值
val powers = (0 unti 1000).view.map(pow(10,_))
powers(100) // pow(10,100)被计算,其他值未计算,同时也不缓存,下次pow(10,100)将重新计算
force方法可以对懒视图强制求值,得到与原集合相同类型的新集合,
懒视图的好处:可以避免在多种变换下产生的中间集合
(0 to 1000).map(pow(10,_)).map(1/_) //先第一个map,再第二个map, 构建了一个中间集合
(0 to 1000).view.map(pow(10,_)).map(1/_).force // 记住两个map操作,每个元素被两个操作同时执行,不需要额外构中间集合
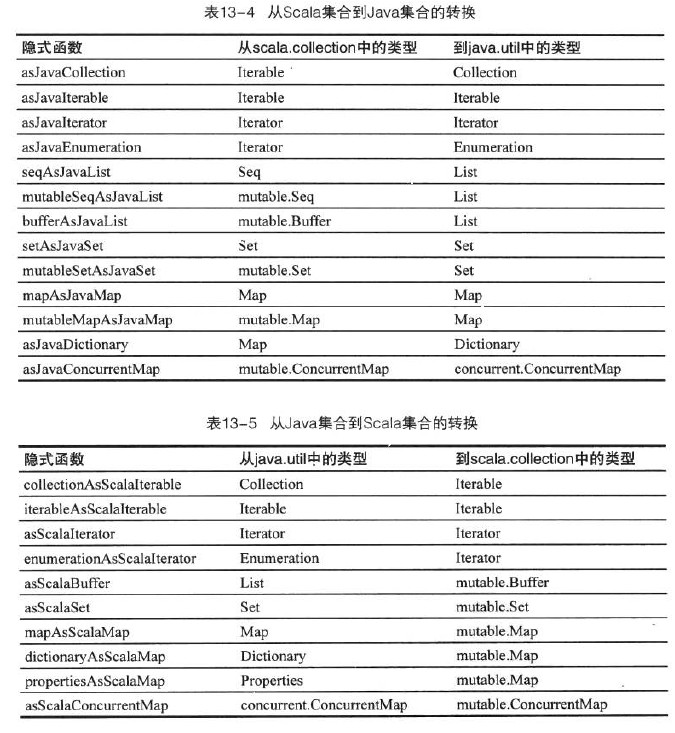
与Java集合的互操作
import scala.collection.JavaConversions._
val props:scala.collection.mutable.Map[String,String] = System.getProperties()
如果担心那些不需要的隐式转换也被引入的话,只引入需要的即可
import scala.collection.JavaConversions.propertiesAsScalaMap
这些转换产出的是包装器,让你可以使用目标接口来访问原本的值
props("name") = "clat" //props既是包装器
包装器将调用底层Properties对象的put("name","clat")
线程安全的集合
Scala类库提供了六个特质,将他们混入集合,让集合的操作变成同步
SynchromizedBuffer
SynchromizedMap
SynchromizedPriorityQueue
SynchromizedQueue
SynchromizedSet
SynchromizedStack
val scores =new scala.collection.collection.mutable.HashMap[String, Int] with scala.collection.mutalbe.SynchronizzedMap[String,Int]
注:这里可以确保scores不会被破坏,任何操作都必须先完成,其他线程才可执行另一个操作。但并发修改和遍历集合并不安全。
通常来说,最好使用java.util.concurrent包中的类.
并行集合
为了更好利用计算机的多个处理器,支持并发通常是必需的
如果coll是个大型集合,那么
coll.par.sum //并发求和,par方法产出当前集合的一个并行实现,该实现会尽可能地并行执行集合方法
coll.par.count(_ % 2 ==0) //计算偶数的数量
对数组、缓冲、哈希表、平衡树而言,并行实现会直接重用底层实际集合的实现,所以很高效。
可以通过对要遍历的集合应用.par并行化for循环
for( i <- (0 until 100).par) print( i + " " ) //数字是按照作用于该任务的线程产出的顺序输出
在for/yield循环中,结果是依次组装的
for( i <- (0 until 100).par) yield i +" "
par返回的并行集合扩展自ParSeq ParSet Parmap,都是ParIterable的子类型,不是Iterable的子类型,所以不能将并行集合传递给预期Iterable Seq Set Map的方法。
可以用ser方法将并行集合转换回串行的版本。
只有可以自由结合的操作 可以用平行集合
(a op b) op c = a op( b op c), 加是可自由结合的
(a -b ) -c != a - (b -c) 减法不是自由结合
有一个fold方法对集合的不同部分进行操作,但是不像foldLeft和foldRight那样灵活,
该操作符的两个操作元都必须是集合的元素类型,要求fold的参数类型与集合元素一样,不像上面foldLeft,参数是String, 集合是Int 那样
coll.par.fold(0)(_ + _)
aggregate方法,可以解决上面的问题,该操作符应用于集合的不同部分,然后再用你另一个操作符组合结果
str.par.aggregate(Set[Char]())(_ + _, _ ++ _) //等同于 str.foldLeft(Set[Char]())(_ + _)
产出一个str中所有不同字符的集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号