Partitioners
Components of Cassandra - Partitioners
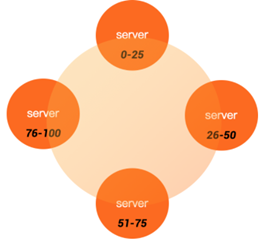
A partitioner determines how data is distributed across the nodes in the cluster.
Basically, a partitioner is a function for deriving a token representing a row from its partition key, typically by hashing.
Cassandra offers the following partitioners that can be set in the cassandra.yaml file.
Murmur3Partitioner (default): uniformly distributes data across the cluster based on MurmurHash hash values.
RandomPartitioner: uniformly distributes data across the cluster based on MD5 hash values.
ByteOrderedPartitioner: keeps an ordered distribution of data lexically by key bytes
Note: However, the partitioners are not compatible, and data partitioned with one partitioner cannot be easily converted to the other partitioner.
整个启动流程会启动前端cql server用来接收客户端cql请求,启动node互相通信用的MessageService。
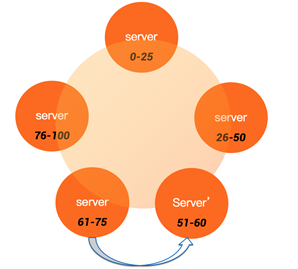
cassandra启动过程对于新节点加入还是正常启动还是有区分的,新节点会造成数据重分布,所以需要先执行bootstrap
数据分区和数据放置是逻辑和物理的关系,逻辑是顶层设计,物理是具体实现,逻辑设计决定物理实现,物理约束反过来影响逻辑设计。
考虑为什么要进行数据分区?
举个例子,
给你10个乒乓球,要求放入3个盒子里。
如何决定哪个球放入哪个盒子?比如
按照编号大小:0-2放入盒子A,3-5放入盒子B,6-9放入盒子C
按照编号特征:对3取余0放入盒子A,取余1放入盒子B,取余==2放入盒子C
...
上面的策略就是选择数据分区的过程,既然有这么多分区方法可以选,选哪个最好?有一个比较重要的考虑因素是,3个盒子到底是什么特征?比如是否一样大小。比如我告诉你盒子A和B只能放1个,盒子C可以放100个,那么上面两种策略都不行。如果我告诉你,盒子ABC都能放100个,那么上面两种策略都可以。具体到一个盒子里面,怎么放也有讲究,比如随便扔,或者用格子一个个放。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号