Cassandra Overview
Cassandra 的目标
To handle big data workloads across multiple nodes without any single point of failure.
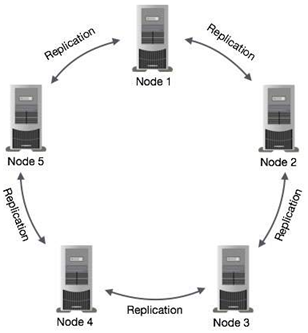
Cassandra has peer-to-peer distributed system across its nodes, and data is distributed among all the nodes in a cluster.
All the nodes in a cluster play the same role. Each node is independent and at the same time interconnected to other nodes.
Each node in a cluster can accept read and write requests, regardless of where the data is actually located in the cluster.
When a node goes down, read/write requests can be served from other nodes in the network.
Cassandra uses the Gossip Protocol in the background to allow the nodes to communicate with each other and detect any faulty nodes in the cluster.
Components of Cassandra
Node − It is the place where data is stored.
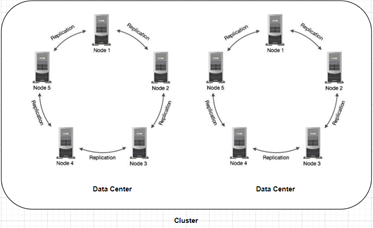
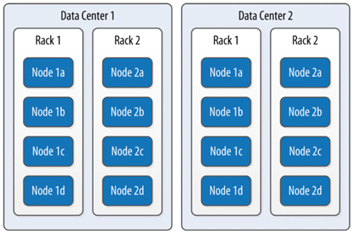
Data center − It is a collection of related nodes. Replication is set by datacenter. Using separate datacenters prevents Cassandra transactions from being impacted by other workloads and keeps requests close to each other for lower latency. Depending on the replication factor, data can be written to multiple datacenters. One datacenter must never span physical locations.
Cluster − A cluster is a component that contains one or more data centers. It can span physical locations.