redis 学习 - 降低内存使用
本篇已收录至redis in action 学习笔记系列
降低 redis 的内存占用有助于减少创建快照和加载快照所需的时间, 提升载入 AOF 文件的速度以及重写 AOF 文件的效率, 缩短从服务器数据同步的时间.
短结构
我们首先要了解 redis 中列表
list的实现是双链表.使用散列表表示散列,使用散列表和跳跃表表示有序集合. 当这三个数据结构的长度较短, 或者体积较小的时候, redis 可以选择使用一种名为ziplist的结构存储它们. 压缩列表会以序列化的方式存储数据, 读取的时候需要解码. 每次被写入的时候也需要局部进行编码.
个人理解就是, 如果 redis 真正按照列表, 散列, 有序集合的原始结构存储的话, 空间利用上会非常低. 所以在一定程度上, redis 是按照一种压缩后的格式存储数据的. 比如列表的原始结构如下:
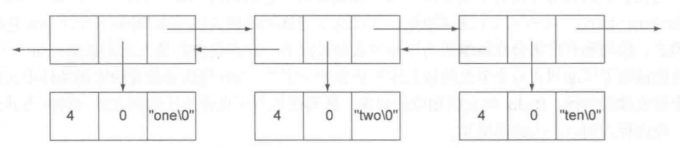
这里面存在不少浪费的空间, 于是 redis 会根据config中的配置项, 如果你存入列表的数据范围没有超过, redis会以默认压缩的方式存储数据:

比如对一个列表加入数据后, 看看这个列表的type:
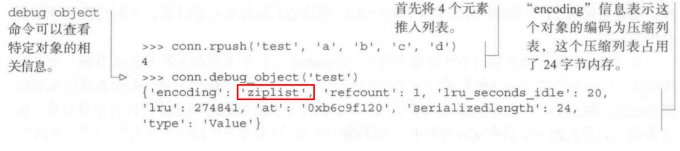
当数据超过配置时, 会改成原始列表存储:
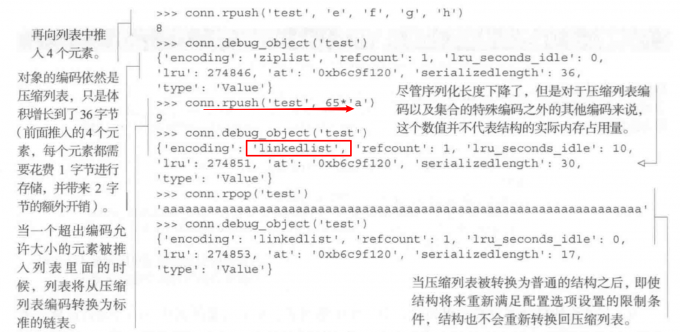
跟列表, 散列, 有序集合不同, 集合没有使用压缩列表存储, 而是使用了另一种方式存储.
集合的整数集合(intset)编码
一个集合要符合什么样的条件才能存储为整数集合呢.

只要集合存储的整数数量没有超过配置设定的大小, redis 就会使用整数集合来替代集合去减少数据体积.

为什么设定超过大小后就还原数据结构
因为短数据结构一旦过大会带来性能问题
书中使用了一段代码来测性能, 当配置的值不断地增大时, 操作一个大的压缩结构的速度会受到的影响有多大.


所以这就是为啥不建议将压缩数据的阈值调的过大的原因.
使用短key名也可以节省内存空间
这是一个小tip, 当内存中的键数量巨大时, 效果才明显.
分片结构
对有序集合进行分片是没有太大意义的. 因为无论怎么分, 都会影响到有序集合的读写速度
对散列进行分片
散列的主要作用就是存储批量的键值对. 比如存储以城市id为key的城市信息散列, 可能需要存储约37万个键值对. 所以把如此多的数据放入一个散列中肯定会使用原有数据结构存储, 那么我们次节的主要目的是对其进行分片
散列分片的原则是根据基础键和value中的键进行分片.
下面是根据存入散列中的key是否是整数, 对key进行换算, 得到share_id的过程:

然后是新的hset和hget:


对城市id与信息重新导入redis
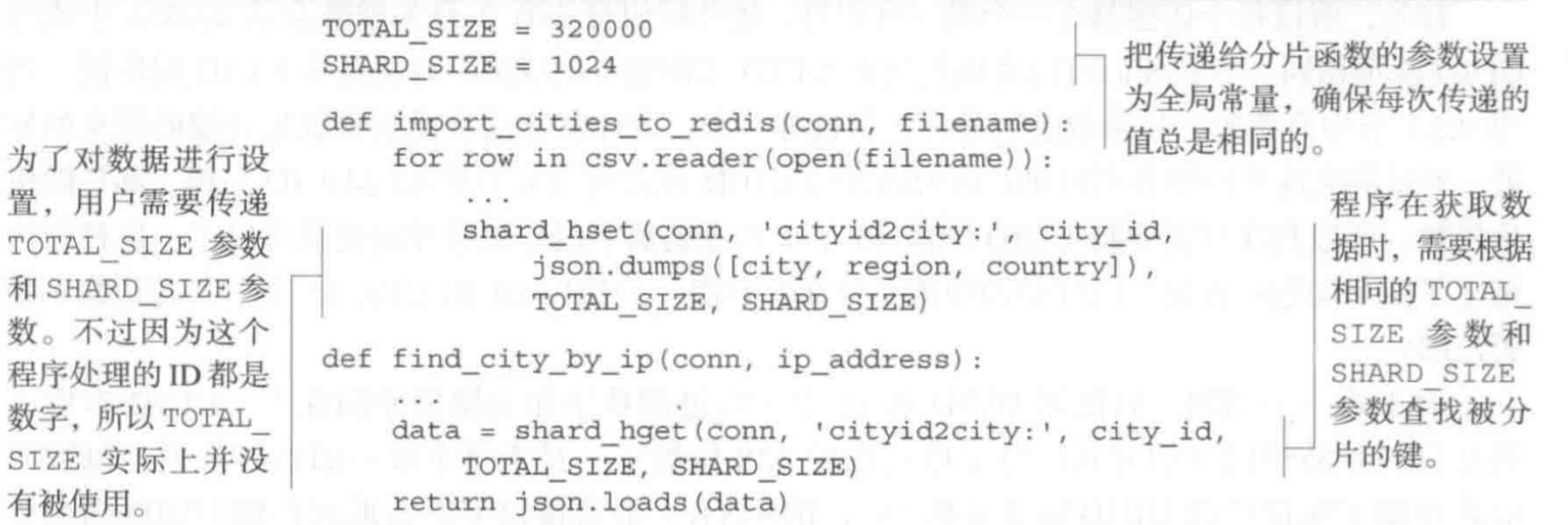
使用之前没有压缩分片的方式存储这些数据大概要使用内存44MB, 而经过压缩和分片后, 程序只花费了12MB内存
对集合进行分片
集合set的主要作用是存储不同的元素, 比如记录某个站点每天不同的访客的数量, 就可以在内存中搞这么一个集合, 但是如果这个网站像淘宝那么火爆, 一个集合就会越来越大.所以我们次节的目的是对大体积的集合进行分片
假设每个用户的id是不同的, 所以网站准备通过存储访问者的uuid来辨识是否是不同的用户.
在这里又有一个内存使用提升的策略就是对uuid进行取舍, 这里可以从书中详细了解.

通过对集合进行分片的优化, 对于每天有100万人次的访问量的站点, 原来的存储结构要花费56mb内存, 而新的结构则花费9.5mb内存
打包存储二进制位和字节的方式
即将数据打包存储到字符串键里面
小结
本文的目的是让redis使用者谨慎的选择数据的存储方式, 可以有效地降低程序在使用redis时对内存的占用.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号