redis 学习 - 常见命令
本篇已收录至redis in action 学习笔记系列
string 字符串数据类型的相关命令用于管理 redis 字符串值
| cmd | desc |
|---|---|
| set k v | - |
| get k | - |
| getrange k start end | - |
| getset k newV | |
| getbit k offset | 指的是获取 k 对应的 value 的二进制的值对应的位上的0 或者 1 |
| setbit k offset value | - |
| mget k1 k2 | - |
| setex k [seconds] v | expire |
| setnx k v | not exist |
| setrange k offset v | 用 v 的值覆写 k 当前的值, 从偏移量开始 |
| strlen k | 返回 k 的 v 的长度 |
| mset k v k1 v1.. | - |
| msetnx k v k1 v1 .. | - |
| psetex k [milliseconds] value | - |
| incr key | ++1 |
| incrby key [increment] | - |
| incrbyfloat k [increment] | - |
| decr k | - |
| decrby k decrement | - |
| append k v | 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾。 |
list Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
| cmd | desc |
|---|---|
| blpop l1 [l2] 100 | 阻塞方式弹出 list 的第一个元素, 如果list 中没有元素, 就阻塞到有或者超时为止 |
| brpop l1 [l2] 100 | - |
| brpoplpush l1 l2 100 | 从列表尾部弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| lindex l1 [index] | 通过索引获取列表中的元素 |
| linsert l1 before/after value newvalue | 在列表的元素前或者后插入元素 |
| llen l1 | 获取列表长度 |
| lpop l1 | - |
| lpush l1 v1 v2 v3.. | - |
| lpushx l1 v1 | 将一个值插入到已存在的列表头部 |
| lrange l1 start end | - |
| lrem l1 [count] v | 移除列表中count个value |
| lset l1 [index] v | 通过索引设置列表元素的值 |
| ltrim l1 start stop | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
| cmd | desc |
|---|---|
| hmset h1 f1 v1 [f2 v2...] | 同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| hgetall h1 | - |
| hdel h1 f1 f2 | - |
| hexists h1 f1 | - |
| hget h1 f1 | 获取一个 h1 中的f 的值 |
| hincreby h1 f1 [increment] | - |
| hincrebyfloat h1 f1 [increment] | - |
| hkeys h1 | 获取所有哈希表中的字段 |
| hlen h1 | 获取哈希表中字段的数量 |
| hmget h1 f1 f2.. | 获取多个 h1 中 f 的值 |
| hset h1 f1 v1 | 将哈希表 key 中的字段 field 的值设为 value 。 |
| hsetnx h1 f2 v2 | 只有在字段 field 不存在时,设置哈希表字段的值。 |
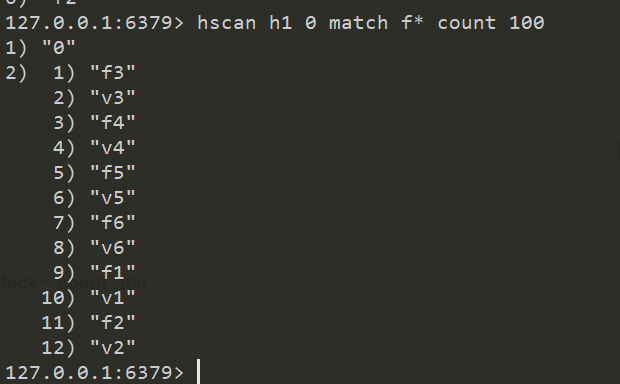
scan hscan
当需要遍历Redis所有key或者指定模式的key时,首先想到的是KEYS命令,但是如果redis数据非常大,并且key也非常多的情况下,查询的时候很可能会很慢,造成整个redis阻塞
基于游标的迭代器. 意味着命令的每次调用, 都需要上次调用这个命令返回的游标作为此次命令的游标, 以此来延续迭代过程.
当 scan 命令的游标设置为 0 时, 开始新的一轮迭代, 当返回值为 0 时表示迭代结束.
hscan h1 [cursor] mathc [f*] count [count]
set Redis 的 Set 是 String 类型的无序集合
添加,删除,查找的复杂度都是 O(1)
| cmd | desc |
|---|---|
| sadd s1 m1 m2.. | - |
| scard s1 | 返回个数 |
| sdiff s1 s2 | 返回差集 |
| sdiffstore destination s1 s2 | 返回的差集放入des中 |
| sinter s1 s2 | 返回交集 |
| sinterstore destination s1 s2 | 返回的交集放入des中 |
| sismember s1 m1 | 判断 m1 是否是 s1 的成员 |
| smembers s1 | 返回 s1 中所有成员 |
| smove s1 destination m1 | 将 m1 从 s1 移动到 destination |
| srem s1 m1 m2... | 移除多个 m |
| sunion s1 s2... | 返回给定集合的并集 |
| sunionstore destination s1 s2... | - |
sorted set
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序
有序集合的成员是唯一的,但分数(score)却可以重复。
针对min和max参数需要额外说明的是,-inf和+inf分别表示Sorted-Sets中分数的最高值和最低值。缺省情况下,min和max表示的范围是闭区间范围,即min <= score <= max内的成员将被返回。然而我们可以通过在min和max的前面添加"("字符来表示开区间,如(min max表示min < score <= max,而(min (max表示min < score < max。
| cmd | desc |
|---|---|
| zadd z1 score1 m1 score2 m2... | 添加参数中指定的所有成员及其分数到指定key的Sorted-Set中,在该命令中我们可以指定多组score/member作为参数。如果在添加时参数中的某一成员已经存在,该命令将更新此成员的分数为新值,同时再将该成员基于新值重新排序。如果键不存在,该命令将为该键创建一个新的Sorted-Sets Value,并将score/member对插入其中。如果该键已经存在,但是与其关联的Value不是Sorted-Sets类型,相关的错误信息将被返回 |
| zcard z1 | 获取有序集合的成员数 |
| zcount z1 min-score max-score | 该命令返回顺序在参数start和stop指定范围内的成员,这里start和stop参数都是0-based,即0表示第一个成员,-1表示最后一个成员。如果start大于该Sorted-Set中的最大索引值,或start > stop,此时一个空集合将被返回。如果stop大于最大索引值,该命令将返回从start到集合的最后一个成员。如果命令中带有可选参数WITHSCORES选项,该命令在返回的结果中将包含每个成员的分数值,如value1,score1,value2,score2... |
| zincrby z1 increment member | 该命令将为指定Key中的指定成员增加指定的分数。如果成员不存在,该命令将添加该成员并假设其初始分数为0,此后再将其分数加上increment。如果Key不存,该命令将创建该Key及其关联的Sorted-Sets,并包含参数指定的成员,其分数为increment参数。如果与该Key关联的不是Sorted-Sets类型,相关的错误信息将被返回。 |
| zinterstore destination numofkeys z1 z2...zk | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| zlexcount z1 min max | 在有序集合中计算指定字典区间内成员数量 |
| zrem key member [member..] | 该命令将移除参数中指定的成员,其中不存在的成员将被忽略。 |
| zRemRangeByRank key start stop | 删除索引位置位于start和stop之间的成员,start和stop都是0-based,即0表示分数最低的成员,-1表示最后一个成员,即分数最高的成员。 |
| zRemRangeByScore key min max | 删除分数在min和max之间的所有成员,即满足表达式min <= score <= max的所有成员。对于min和max参数,可以采用开区间的方式表示,具体规则参照ZCOUNT。 |
| zrange z1 min-index max-index [withscores] | 通过索引区间返回有序集合指定区间内的成员 |
| zrangebylex z1 min max [limic offset count] | 通过字典区间返回有序集合的成员 |
| ZRANGEBYSCORE zset (1 5 [withscores] [limit] | 该命令将返回分数在min和max之间的所有成员,即满足表达式min <= score <= max的成员,其中返回的成员是按照其分数从低到高的顺序返回,如果成员具有相同的分数,则按成员的字典顺序返回。 可选参数LIMIT用于限制返回成员的数量范围。 可选参数offset表示从符合条件的第offset个成员开始返回,同时返回count个成员。 可选参数WITHSCORES的含义参照ZRANGE中该选项的说明。 |
| zRevRangeByScore key max min [withscores] [limit] [offset] [count] | 该命令除了排序方式是基于从高到低的分数排序之外,其它功能和参数含义均与ZRANGEBYSCORE相同。 |
| zrevrange key 0 -1 | 该命令的功能和ZRANGE基本相同,唯一的差别在于该命令是通过反向排序获取指定位置的成员,即从高到低的顺序。如果成员具有相同的分数,则按降序字典顺序排序 |
| zrank key member | 该命令将返回参数中指定成员的位置值,其中0表示第一个成员, |
| zrevrank key member | 该命令的功能和ZRANK基本相同,唯一的差别在于该命令获取的索引是从高到低排序后的位置,同样0表示第一个元素,即分数最高的成员。 |
| zscore key member | 获取指定Key的指定成员的分数。 |
key 相关的命令
| cmd | desc |
|---|---|
| key pattern | 获取所有匹配pattern参数的Keys。需要说明的是,在我们的正常操作中应该尽量避免对该命令的调用,因为对于大型数据库而言,该命令是非常耗时的,对Redis服务器的性能打击也是比较大的。pattern支持glob-style的通配符格式,如*表示任意一个或多个字符,?表示任意字符,[abc]表示方括号中任意一个字母。 |
| DEL key [key ...] | 从数据库删除中参数中指定的keys,如果指定键不存在,则直接忽略。还需要另行指出的是,如果指定的Key关联的数据类型不是String类型,而是List、Set、Hashes和Sorted Set等容器类型,该命令删除每个键的时间复杂度为O(M),其中M表示容器中元素的数量。而对于String类型的Key,其时间复杂度为O(1)。 |
| EXISTS key | 判断指定键是否存在。 |
| MOVE key db | 将当前数据库中指定的键Key移动到参数中指定的数据库中。如果该Key在目标数据库中已经存在,或者在当前数据库中并不存在,该命令将不做任何操作并返回0。 |
| RENAME key newkey | 为指定指定的键重新命名,如果参数中的两个Keys的命令相同,或者是源Key不存在,该命令都会返回相关的错误信息。如果newKey已经存在,则直接覆盖。 |
| PERSIST key | 如果Key存在过期时间,该命令会将其过期时间消除,使该Key不再有超时,而是可以持久化存储。 |
| EXPIRE key seconds | 该命令为参数中指定的Key设定超时的秒数,在超过该时间后,Key被自动的删除。如果该Key在超时之前被修改,与该键关联的超时将被移除。 |
| EXPIREAT key timestamp | 该命令的逻辑功能和EXPIRE完全相同,唯一的差别是该命令指定的超时时间是绝对时间,而不是相对时间。该时间参数是Unix timestamp格式的,即从1970年1月1日开始所流经的秒数。 |
| TTL key | 获取该键所剩的超时描述。 |
| RANDOMKEY | 从当前打开的数据库中随机的返回一个Key |
| TYPE key | 获取与参数中指定键关联值的类型,该命令将以字符串的格式返回。 |
服务器命令
Redis在设计之初就被定义为长时间不间断运行的服务进程,因此大多数系统配置参数都可以在不重新启动进程的情况下立即生效。即便是将当前的持久化模式从AOF切换到RDB也无需重启。
| cmd | desc |
|---|---|
| bgrewriteaof | 异步执行一个 AOF(AppendOnly File) 文件重写操作 |
| bgsave | 在后台异步保存当前数据库的数据到磁盘 |
| CLIENT KILL [ip:port] [ID client-id] | 关闭客户端连接 |
| client list | 获取连接到服务器的客户端连接列表 |
| cofig get/set * | 获取 configs |
| dbSize | 获取当前的key的数量 |
| flushAll | 清空当前服务器管理的数据库中的所有Keys,不仅限于当前打开的数据库。 |
| flushdb | 清空当前数据库中的所有Keys。 |
| save | 设置RDB持久化模式的保存策略。 |
| shutDown | 停止所有的客户端,同时以阻塞的方式执行内存数据持久化。如果AOF模式被启用,则将缓存中的数据flush到AOF文件。退出服务器。 |
| SlavOf Host Port | 该命令用于修改SLAVE服务器的复制设置。如果一个Redis服务器已经处于SLAVE状态,SLAVEOF NO ONE 命令将关闭当前服务器的被复制状态,与此同时将该服务器切换到MASTER状态。该命令的参数将指定MASTER服务器的监听IP和端口。 还有一种情况是,当前服务器已经是另外一台MASTER的SLAVE了,在执行该命令后,当前服务器将终止和之前MASTER之间的复制关系,而将成为新MASTER的SLAVE,之前MASTER中的数据也将被清空,改为新MASTER中的数据。 然而如果在当前SLAVE服务器上执行的是 SLAVEOF NO ONE 命令,那么该服务器只是中断与当前MASTER的复制关系,并升级为独立的MASTER,其中的数据也不会被清空。 |
| SlowLog subCommand [args] | 该命令主要用于读取执行时间较长的命令。 1. 和该命令相关的配置参数主要有两个,第一个就是执行之间的阈值(以微秒为单位),即执行时间超过该值的命令都会被存入slowlog队列,以供该命令读取。 2. 第二个是slowlog队列的长度,如果当前命令在存入之前,该队列中的命令已经等于该参数,在命令进入之前,需要将队列中最老的命令移出队列。这样可以保证该队列所占用的内存总量保持在一个相对恒定的大小。 3. 由于slowlog队列不会被持久化到磁盘,因此Redis在收集命令时不会对性能产生很大的影响。 该命令还包含以下几个子命令: 1. SLOWLOG GET N: 从slowlog队列中读取命令信息,N表示最近N条命令的信息。2. SLOWLOG LEN:获取slowlog队列的长度. 3. SLOWLOG RESET:清空slowlog中的内容。 |
| CLIENT SETNAME connection-name | 设置当前连接的名称 |
| DEBUG SEGFAULT | 让 Redis 服务崩溃 |
各个数据类型的实际使用场景列举
list
-
消息传递
-
任务队列
-
存储任务信息
-
最近历史记录
-
常用联系人等
集合
- 组合集合和关联集合
散列
- 可以看做关系数据库的行

