redis 学习 - 基础篇
本篇已收录至redis in action 学习笔记系列
1. 介绍
redis 是一款开源的内存型数据库工具. 在项目中通常会被用于作为数据缓存工具, 这样会提升某些热点数据的访问效率, 同样也降低了数据库的压力. 所以了解和掌握使用 redis 是非常之必要的.
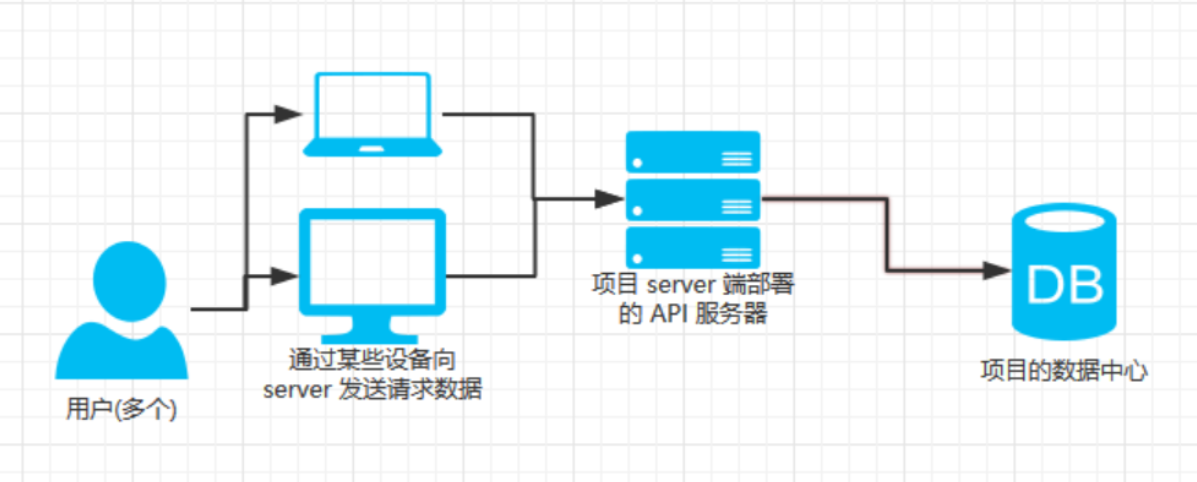
下图是没有使用缓存数据库的结构, 数据都是从数据库获取的. 对于热点数据的频繁访问会对数据库造成很大的压力, 可能会导致服务不可用等问题:
此时为了提升数据访问效率, 我们可以对热点数据进行缓存, 放入 redis 数据库中. 由于 redis 是利用内存对数据进行存储的. 所以速度超快. 但是内存的资源往往是有限的.
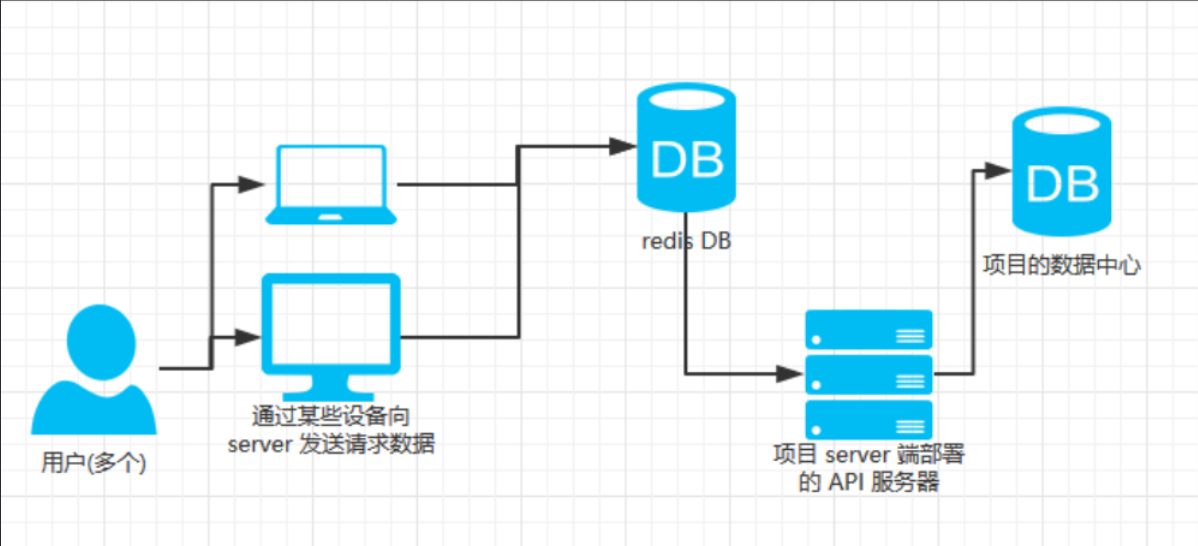
如果数据通过 redis 能够获取得到, 就可以直接返回给用户使用. 如果访问不到, 再通过服务器端访问数据库得到.
(上述内容和图片都是极为简化版本的描述, 这里旨在对 redis 的理解, 而不针对复杂场景中具体的问题的解决方案)
2. windows 环境下安装和运行 Redis
redis 属于 C/S 结构的工具. 也就是说你要有一个 redis server, 还有一个 redis client.
http://try.redis.io/ 这个网站提供了线上使用 redis. 基于学习为目的线上和线下都可以我觉得.
下载地址:
https://github.com/microsoftarchive/redis/releases
windows 下载 zip 压缩文件后, 解压到本地即可.
运行 Redis Server
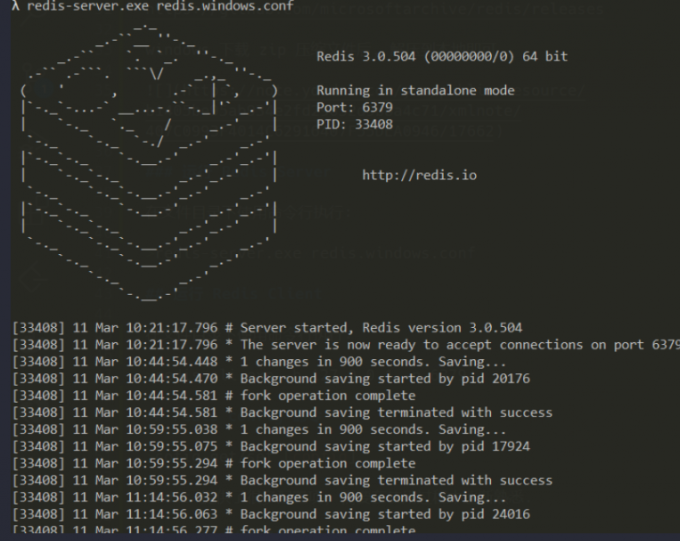
在文件目录下使用命令行执行:
redis-server.exe redis.windows.conf
运行 Redis Client
在文件目录下使用命令行执行:
redis-cli.exe -h 127.0.0.1 -p 6379

Redis server 与 client
redis server 是单线程服务器. 基于 Event-Loop 模式来处理 Client 的请求,这样就不必考虑线程安全的问题, 以及线程之间切换带来的损耗.
什么是 event-loop (事件循环): 事件循环被称作循环的原因在于,它一直在查找新的事件并且执行。一次循环的执行称之为 tick, 在这个循环里执行的代码称作 task, 本篇文章不做详述. 详情可以上网查或者看看知乎大神写的帖子 一次搞懂Event loop
项目初期, client 的数量比较少的时候, redis server 能够很有效的提升数据访问效率. 但是当 client 逐渐变多后, 原来的结构此时就显得效率不是那么高了, 主要原因是:
-
client 多了以后, 需要访问的数据也会变多, 然而单一 server 的内存资源是有限的. 会造成部分数量的数据无法命中缓存.
-
单一 redis 的吞吐量无法满足数量增多的 client. 这个比较好理解, 其实就是 server 端的单一时间内的处理任务的能力有限.
此时则需要增加 redis 服务器. 使用分布式最常使用的解决方案, redis 服务器集群来解决上述两个问题.
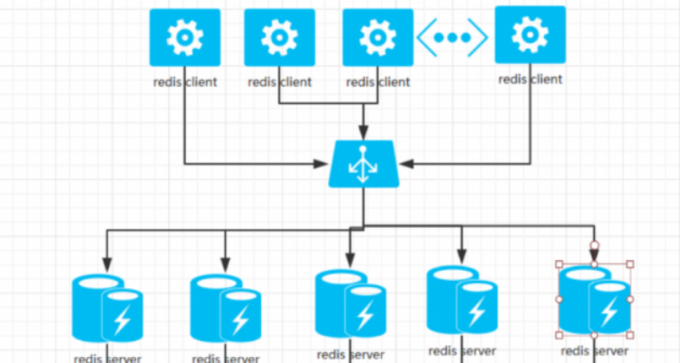
解决两个问题:
- 扩大缓存容量
- 提升事件吞吐能力
提出问题: 怎样根据业务场景设计出合理的复杂均衡算法, 将不同的热点数据平均分布到 redis server 中? 这个算法在服务端一般在什么位置?
上图中的架构虽然能够解决一部分问题, 但是还不能满足更复杂的场景. 比如:
- 当某一台 redis server 宕机, 数据丢失时会导致大量的数据访问请求直接到数据库端.
- 某一热点数据的访问量激增, 导致单一服务器过于忙碌, 服务器使用体验降低.
为解决上面两个问题, 可能除了分布式集群外, 我们还需要引入"Master-Slave(主-从)"服务器机制来解决.
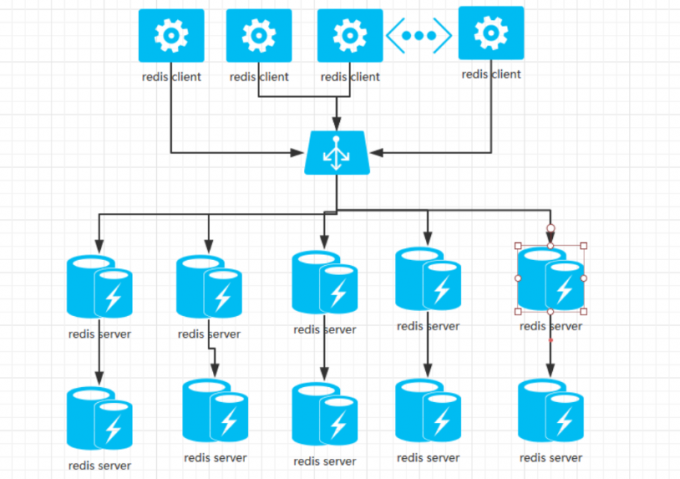
比如每个缓存数据中心都安排两台 redis 服务器, Master负责接收客户端的写入请求,将数据写到Master后,同步给Slave,实现数据备份。一旦Master挂了,可以将Slave提拔为Master;或者一旦Master发现自己忙不过来了,可以把一些查询请求,转发给Slave去处理,也就是Master负责读写或者只负责写,Slave负责读. 这样就能够解决上面的两个问题.
始终记住在分布式的架构中, 当单一服务器无法满足需求时, 架构的设计要允许服务器能够横向扩展, 才是好的分布式架构. 比如上面的方案, 在更重要的缓存中心节点上, 可能会安排更多个 slave 服务器, 以保证性能.

