
From:
https://blog.csdn.net/wuxintdrh/article/details/69056188
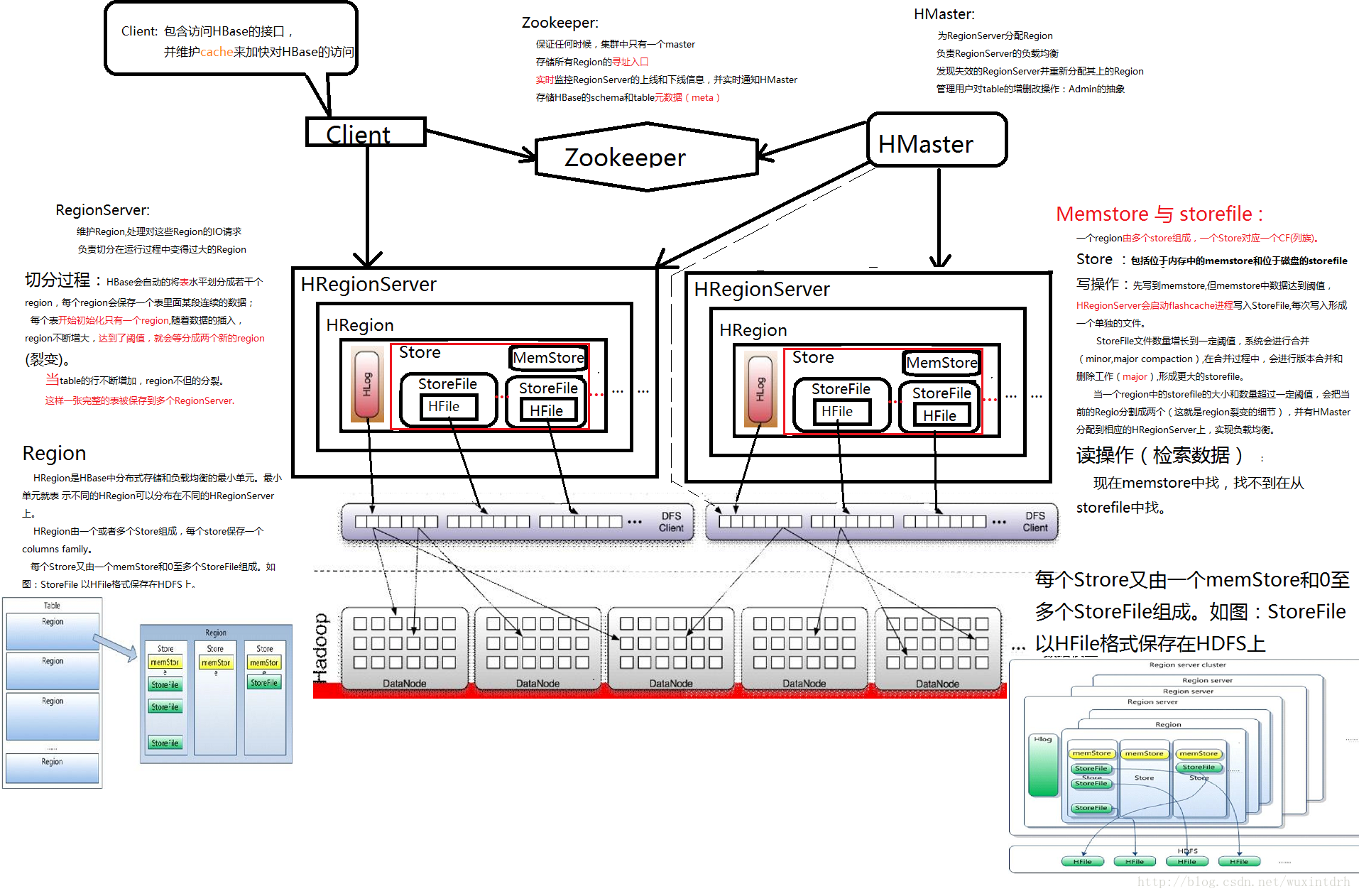
写操作:
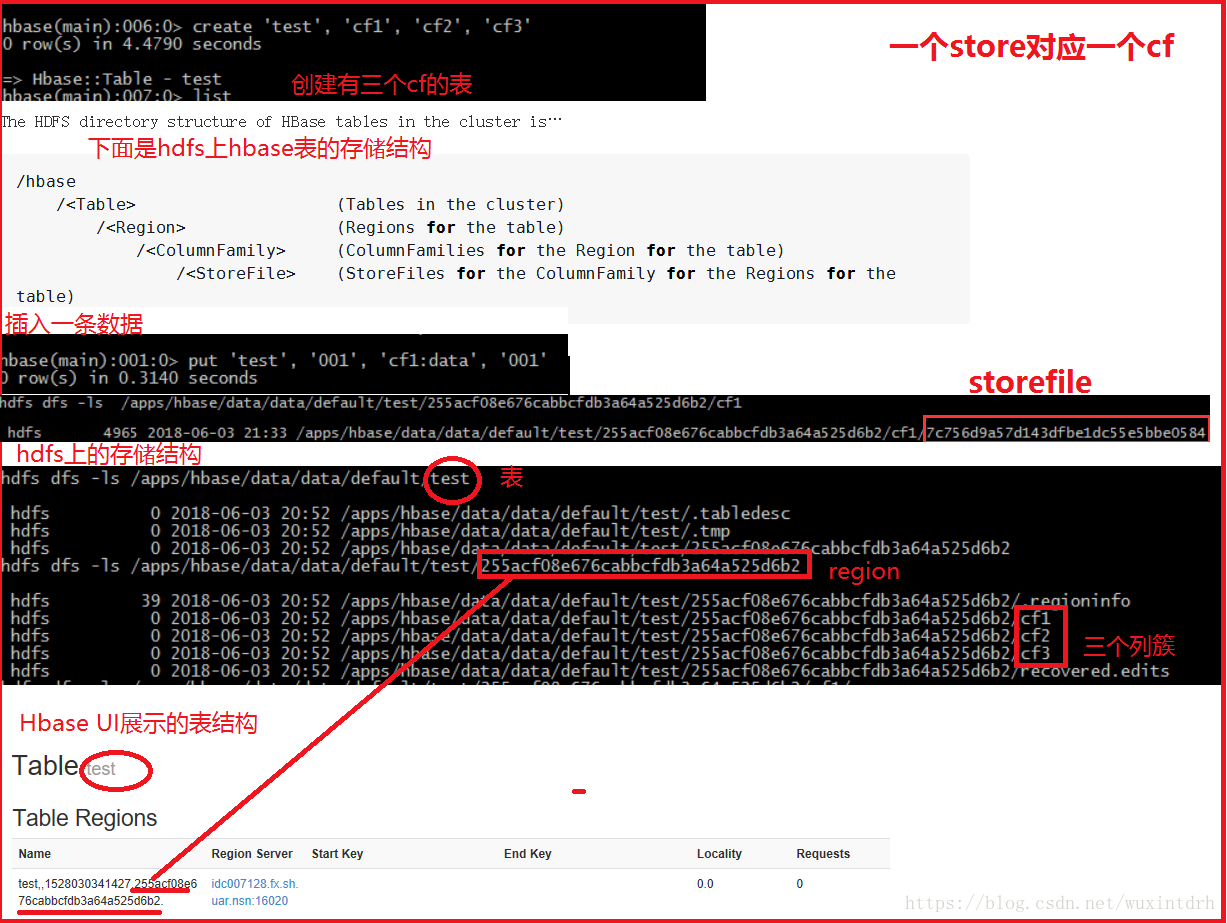
Client写入,存入Memstore,Memstore满则Flush成一个Storefile,Storefile文件数量增长到一定的阈值,触发Compact合并操作,多个Storefile合并成一个Storefile,同时进行版本合并和数据删除,当Storefile compact后,逐步形成越来越大的store file,单个store file大小超过一定的阈值后触发split操作,把当前region分裂为两个region,原来的region下线,新的2个region会被hmaster分配到hregionserver上(负载均衡),使得原先1个Region的压力分流到两个上,Hbase只是增加数据,所有的更新和删除操作都是在COMPACT阶段做的。所以用户操作只需要写入到内存即返回,保证IO性能
写入先memstore, storefile,compact,split
读操作:
Client->zookeeper->.ROOT->.META->用户数据表zookeeper记录了.ROOT的路径信息(root只有一个region),.ROOT理记录了.META的region信息(.META信息可能有多个region)
Hbase中,所有的存储文件都被划分成若干小块存储,这些小存储块在get或scan操作时会加载到内存中
Hbase顺序的读取一个数据块到内存缓存中,其读取相邻的数据时就可以在内存中读取而不是从磁盘中再次读取,减少IO次数
HLog
每个HRegionServer中都会有一个HLog(Write Ahead Log),每次用户操作写入Memstore的同时,也写入一份到HLog文件,该文件定期滚动出新,并删除旧的文件(已经持久化到Storefile中的数据)。当HRegionServer意外终止后,HMaster会通过zookeeper感知,HMaster首先处理遗留的HLog文件,将不同的region的log数据拆分,分别放到相应的region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在load region的过程中,会发现有历史的HLog需要处理,因此会replay HLog中的数据到memstore中,然后flush到storefile,完成数据恢复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号