Netty - 2
参考:Scalable IO in Java - http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf

mainReactor负责处理客户端的连接请求,并将accept的连接注册到subReactor的其中一个线程上;subReactor负责处理客户端通道上的数据读写;Thread Pool是具体的业务逻辑线程池,处理具体业务。
参考: https://www.jianshu.com/nb/6812432
Selector监听多个通道的事件,可以用一个线程监听多个channel事件,SelectionKey表示通道和选择器之间的关系,追踪对应通道是否就绪。
ServerSocketChannel监听新进来的TCP连接的通道,当连接达到会创建SocketChannel
Buffer可存放固定数量数据的缓冲,与通道一起工作,读写数据。数据只能通过buffer写入到channel或者从channel读出到Buffer
Netty服务端简单例子,源自源码测试中
EventLoopGroup是Netty实现的线程池接口,两个线程池:bossGroup和workerGroup分别对应mainReactor和subReactor,其中boss专门用于接受客户端连接,worker也就是常说的IO线程专门用于处理IO事件。用户自定义的业务线程池须实现EventExecutorGroup接口,4.1版本则可以直接使用JAVA自带的线程池
Netty提供了两个启动器ServerBootstrap和Bootstrap,分别用于启动服务器端和客户端程序
group(EventLoopGroup...)方法用于指定一个或两个Reactor
channel(Channel)方法本质用来指定一个Channel工厂
option(Key, Value)用于指定TCP相关的参数以及一些Netty自定义的参数
childHandler()用于指定subReactor中的处理器
handler()用于指定mainReactor的处理器
ChannelInitializer,它是一个特殊的Handler,功能是初始化多个Handler,完成初始化工作后,ChannelInitializer会从Handler链中删除
bind(int)方法将服务端Channel绑定到本地端口,成功后将accept客户端的连接,从而是整个框架运行起来
不在addLast(Handler)方法中指定线程池,那么将使用默认的subReacor即woker线程池也即IO线程池执行处理器中的业务逻辑代码
// Configure the server. EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); // 用户可以自定义ThreadPool EventExecutorGroup threadPool = new ThreadPool(); //在后面p.addLast的时候可以指定是否使用单独的Pool还是和前面的在一起 final EchoServerHandler serverHandler = new EchoServerHandler(); try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .option(ChannelOption.SO_BACKLOG, 100) .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); if (sslCtx != null) { p.addLast(sslCtx.newHandler(ch.alloc())); } //p.addLast(new LoggingHandler(LogLevel.INFO)); p.addLast(serverHandler); } }); // Start the server. ChannelFuture f = b.bind(PORT).sync(); // Wait until the server socket is closed. f.channel().closeFuture().sync(); } finally { // Shut down all event loops to terminate all threads. bossGroup.shutdownGracefully(); workerGroup.shutdownGracefully(); }
NioEventLoop以及NioEventLoopGroup即线程和线程池
EventExecutorGroup
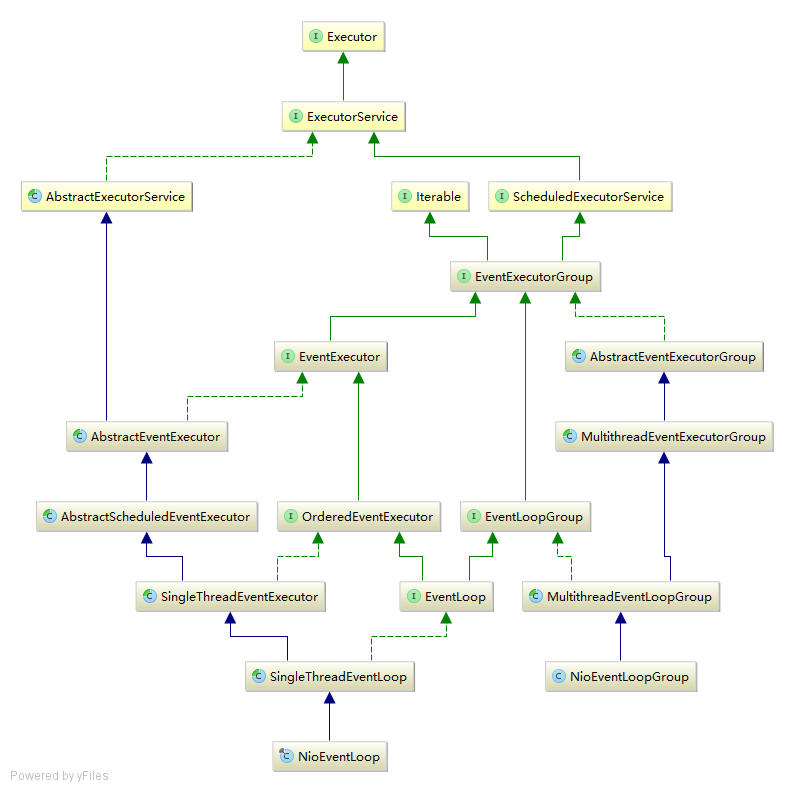
The EventExecutorGroup is responsible for providing the EventExecutor's to use via its next() method. Besides this, it is also responsible for handling their life-cycle and allows shutting them down in a global fashion.
AbstractEventExecutorGroup implements EventExecutorGroup 包含都如类似实现,(1).找一个线程。(2).交给线程执行。
@Override public void execute(Runnable command) { next().execute(command); }
MultithreadEventExecutorGroup 实现了线程的创建和线程的选择
public abstract class MultithreadEventExecutorGroup extends AbstractEventExecutorGroup { private final EventExecutor[] children; private final Set<EventExecutor> readonlyChildren; private final AtomicInteger terminatedChildren = new AtomicInteger(); private final Promise<?> terminationFuture = new DefaultPromise(GlobalEventExecutor.INSTANCE); private final EventExecutorChooserFactory.EventExecutorChooser chooser;
MultithreadEventLoopGroup
ByteBuf:
清空前: +-------------------+------------------+------------------+ | discardable bytes | readable bytes | writable bytes | +-------------------+------------------+------------------+ | | | | 0 <= readerIndex <= writerIndex <= capacity 清空后: +------------------+-------------------------------------+ | readable bytes | writable bytes (got more space) | +------------------+-------------------------------------+ | | | readerIndex(0)<= writerIndex (decreased) <= capacity
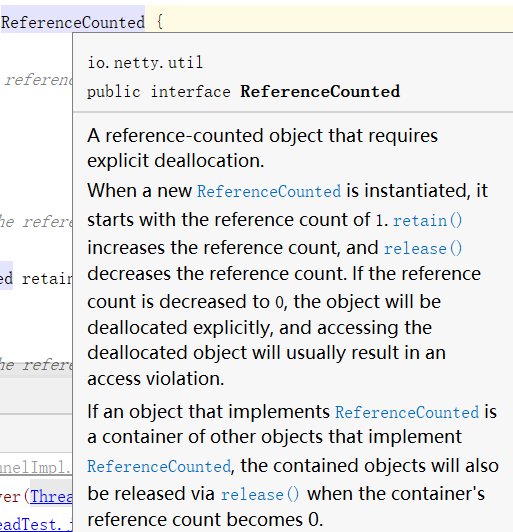
Netty4开始引入了引用计数的特性,缓冲区的生命周期可由引用计数管理,当缓冲区不再有用时,可快速返回给对象池或者分配器用于再次分配,从而大大提高性能,进而保证请求的实时处理,引用计数并不专门服务于缓冲区ByteBuf。用户可根据实际需求,在其他对象之上实现引用计数接口ReferenceCounted
使用retain()使引用计数增加1,使用release()使引用计数减少1
通过duplicate(),slice()等等生成的派生缓冲区ByteBuf会共享原生缓冲区的内部存储区域。此外,派生缓冲区并没有自己独立的引用计数而需要共享原生缓冲区的引用计数。也就是说,当我们需要将派生缓冲区传入下一个组件时,一定要注意先调用retain()方法
HeapByteBuf的底层实现为JAVA堆内的字节数组。
DirectByteBuf的底层实现为操作系统内核空间的字节数组,直接缓冲区的字节数组位于JVM堆外的NATIVE堆,由操作系统管理申请和释放,而DirectByteBuf的引用由JVM管理。
CompositeByteBuf,顾名思义,有以上两种方式组合实现, 需要将后一个缓冲区的数据拷贝到前一个缓冲区;而使用组合缓冲区则可以直接保存两个缓冲区,因为其内部实现组合两个缓冲区并保证用户如同操作一个普通缓冲区一样操作该组合缓冲区,从而减少拷贝操作。
UnpooledByteBuf为不使用对象池的缓冲区,不需要创建大量缓冲区对象时建议使用该类缓冲区。
PooledByteBuf为对象池缓冲区,当对象释放后会归还给对象池,所以可循环使用。
slice()和duplicate()方法生成的ByteBuf与原ByteBuf共享相同的底层实现,只是各自维护独立的索引和标记,使用这两个方法时,特别需要注意结合使用场景确定是否调用retain()增加引用计数
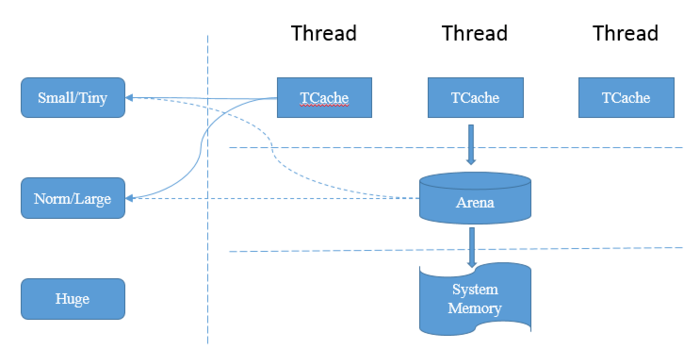
在Netty中,小件商品和大件商品都首先从同城仓库(ThreadCache-tcache)送出;如果同城仓库没有,则会从区域仓库(Arena)送出。
From: https://www.jianshu.com/p/15304cd63175
-
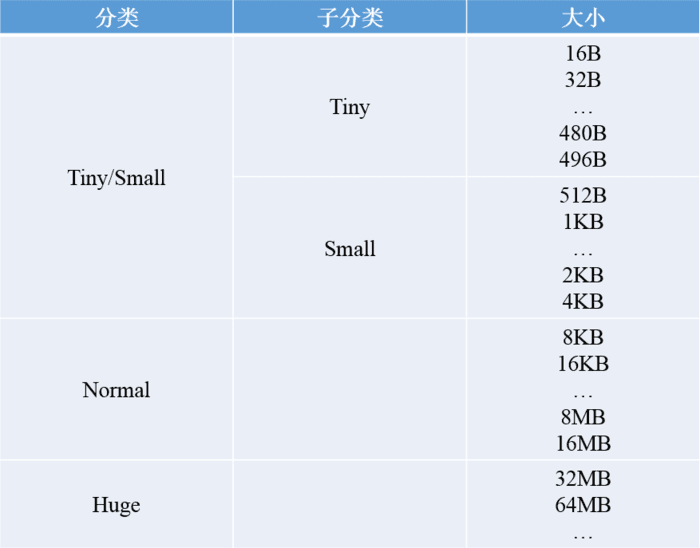
内存分配的最小单位为16B。
-
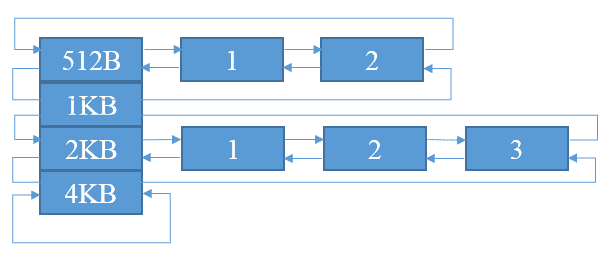
< 512B的请求为Tiny,< 8KB(PageSize)的请求为Small,<= 16MB(ChunkSize)的请求为Normal,> 16MB(ChunkSize)的请求为Huge。
-
< 512B的请求以16B为起点每次增加16B;>= 512B的请求则每次加倍。
-
不在表格中的请求大小,将向上规范化到表格中的数据,比如:请求分配511B、512B、513B,将依次规范化为512B、512B、1KB
为了提高内存分配效率并减少内部碎片,jemalloc算法将Arena切分为小块Chunk,根据每块的内存使用率又将小块组合为以下几种状态:QINIT,Q0,Q25,Q50,Q75,Q100。Chunk块可以在这几种状态间随着内存使用率的变化进行转移
-
QINIT的内存使用率为[0,25)、Q0为(0,50)、Q100为[100,100]。
-
Chunk块的初始状态为QINIT,当使用率达到25时转移到Q0状态,再次达到50时转移到Q25,依次类推直到Q100;当内存释放时又从Q100转移到Q75,直到Q0状态且内存使用率为0时,该Chunk从Arena中删除。注意极端情况下,Chunk可能从QINIT转移到Q0再释放全部内存,然后从Arena中删除。
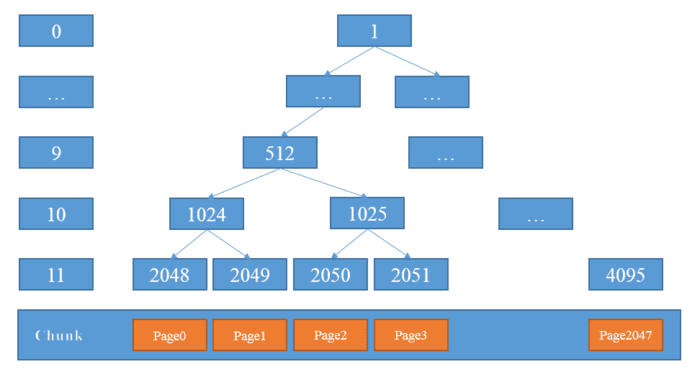
虽然已将Arena切分为小块Chunk,但实际上Chunk是相当大的内存块,在jemalloc中建议为4MB,Netty默认使用16MB。为了进一步提高内存利用率并减少内部碎片,需要继续将Chunk切分为小的块Page。一个典型的切分将Chunk切分为2048块,Netty正是如此,可知Page的大小为:16MB/2048=8KB。一个好的内存分配算法,应使得已分配内存块尽可能保持连续,这将大大减少内部碎片,由此jemalloc使用伙伴分配算法尽可能提高连续性。伙伴分配算法的示意图如下:
-
8KB--需要一个Page,第11层满足要求,故分配2048节点即Page0;
-
16KB--需要两个Page,故需要在第10层进行分配,而1024的子节点2048已分配,从左到右找到满足要求的1025节点,故分配节点1025即Page2和Page3;
-
8KB--需要一个Page,第11层满足要求,2048已分配,从左到右找到2049节点即Page1进行分配。
分配结束后,已分配连续的Page0-Page3,这样的连续内存块,大大减少内部碎片并提高内存使用率。
Netty中每个Page的默认大小为8KB,在实际使用中,很多业务需要分配更小的内存块比如16B、32B、64B等。为了应对这种需求,需要进一步切分Page成更小的SubPage。SubPage是jemalloc中内存分配的最小单位,不能再进行切分。SubPage切分的单位并不固定,以第一次请求分配的大小为单位(最小切分单位为16B)。比如,第一次请求分配32B,则Page按照32B均等切分为256块;第一次请求16B,则Page按照16B均等切分为512块。为了便于内存分配和管理,根据SubPage的切分单位进行分组,每组使用双向链表组合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号