存储高可用方案的本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用,其复杂性主要体现在如何应对复制延迟和中断导致的数据不一致问题
主备:读写主机,“备机”主要还是起到一个备份作用,并不承担实际的业务读写操作
主从:主机读写,从机读
双机切换:状态判断/切换决策
- 互联式:主备机直接建立状态传递的渠道,虚ip或者客户端存主备两个地址自行切换;
- 中介式:主机和备机不再通过互联通道传递状态信息,而是都将状态上报给中介这一角色,MongoDB(M) 表示主节点,MongoDB(S) 表示备节点,MongoDB(A) 表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。开源方案已经有比较成熟的中介式解决方案,例如 ZooKeeper 和 Keepalived。ZooKeeper 本身已经实现了高可用集群架构,因此已经帮我们解决了中介本身的可靠性问题,在工程实践中推荐基于 ZooKeeper 搭建中介式切换架构
- 模拟式:模拟式指主备机之间并不传递任何状态数据,而是备机模拟成一个客户端,向主机发起模拟的读写操作,根据读写操作的响应情况来判断主机的状态,对比一下互连式切换架构,我们可以看到,主备机之间只有数据复制通道,而没有状态传递通道,备机通过模拟的读写操作来探测主机的状态,然后根据读写操作的响应情况来进行状态决策
主主复制:主主复制指的是两台机器都是主机,互相将数据复制给对方,客户端可以任意挑选其中一台机器进行读写操作,必须保证数据能够双向复制,因此对数据的设计有严格的要求,一般适合于那些临时性、可丢失、可覆盖的数据场景
数据集群:多台机器组合在一起形成一个统一的系统
- 数据集中集群,数据集中集群与主备、主从这类架构相似,我们也可以称数据集中集群为 1 主多备或者 1 主多从,因为备机变为多台,所以需要考虑的是主机如何将数据复制给备机、备机如何检测主机状态、主机故障后,如何决定新的主机
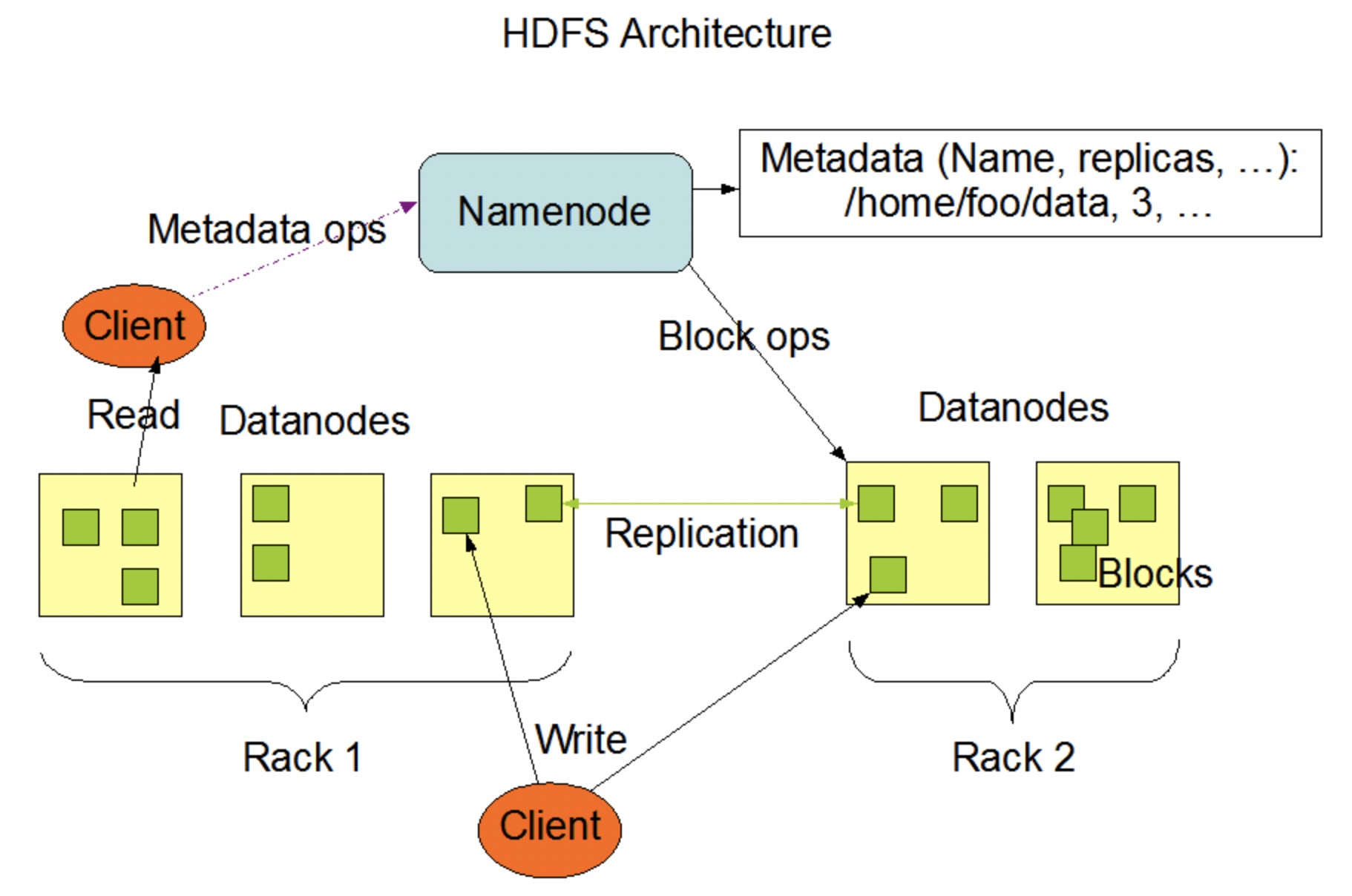
- 数据分散集群,数据分散集群指多个服务器组成一个集群,每台服务器都会负责存储一部分数据;同时,为了提升硬件利用率,每台服务器又会备份一部分数据,此时需要考虑均衡、容错、可伸缩;数据分散集群中的每台服务器都可以处理读写请求,因此不存在数据集中集群中负责写的主机那样的角色,集群服务器选举出来一台机器承担数据分区分配的职责,比如下图Hadoop的namenode独立的服务器负责数据分区的分配,而Elasticsearch 集群通过选举一台服务器来做数据分区的分配
分区:数据分区指将数据按照一定的规则进行分区,不同分区分布在不同的地理位置上,每个分区存储一部分数据,通过这种方式来规避地理级别的故障所造成的巨大影响
- 集中式备份:所有的分区都将数据备份到备份中心
- 互备式
- 独立式
计算高可用的主要设计目标是当出现部分硬件损坏时,计算任务能够继续正常运行。因此计算高可用的本质是通过冗余来规避部分故障的风险
难点:任务管理方面,即当任务在某台服务器上执行失败后,如何将任务重新分配到新的服务器进行执行
- 哪些服务器可以执行任务? 对等、集中式主节点
- 如果重新执行?不管、通过任务管理器管理;任务分配器可以是单独的服务也可以是集群中某个节点,比如zk的Follower收到请求转发给leader
- 主备:没复制,只主能相应请求;冷备就是放着不启动,温备就是启动不提供服务
- 主从:主从都执行任务,由任务调度器确定任务发送对象
- 集群:
- 一类是对称集群,即集群中每个服务器的角色都是一样的,都可以执行所有任务;
- 另一类是非对称集群,集群中的服务器分为多个不同的角色,不同的角色执行不同的任务,例如最常见的 Master-Slave 角色,集群会通过某种方式来区分不同服务器的角色。例如,通过 ZAB 算法选举,或者简单地取当前存活服务器中节点 ID 最小的服务器作为 Master 服务器
zookeeper例子:
任务分配器:ZooKeeper 中不存在独立的任务分配器节点,每个 Server 都是任务分配器,Follower 收到请求后会进行判断,如果是写请求就转发给 Leader,如果是读请求就自己处理。角色指定:ZooKeeper 通过 ZAB 算法来选举 Leader,当 Leader 故障后,所有的 Follower 节点会暂停读写操作,开始进行选举,直到新的 Leader 选举出来后才继续对 Client 提供服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号