索引结构优劣,哈希不适合范围查找,遇到冲突需要扫描链表;数组动态扩缩容维护成本高;二叉树树高过高,不适合内存+磁盘的存储结构
主键索引的叶子节点存储的是整行数据,辅助索引的叶节点存储的是主键,非主键索引的查询需要会表多扫描一棵索引树;
插入数据涉及页的分裂和合并,自增主键的好处,每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂,而且主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
覆盖索引 ~ 查询的是主键
最左前缀 ~ 考虑最左原则,实在不行考虑索引字段的长度,平衡时间和空间的收益
索引下推 ~ 在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数
全局锁(整个数据库实例加锁,Flush tables with read lock (FTWRL)。让整个库处于只读状态) ~ 主库无法更新,备库无法同步binlog
如果数据库支持一致性读,mysqldump 使用参数–single-transaction 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的
表级锁(lock tables … read/write / MDL(metadata lock)) ~ 当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁
可能出现,读锁 -> 写锁(Blocked) -> 读锁(Blocked),所有对表的增删改查操作都需要先申请 MDL 读锁,就都被锁住,等于这个表现在完全不可读写了,如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满
事务中的 MDL 锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放
避免 ~ information_schema 库的 innodb_trx 表中,你可以查到当前执行中的事务。如果你要做 DDL 变更的表刚好有长事务在执行,要考虑先暂停 DDL,或者 kill 掉这个长事务 / 或者alter table 语句里面设定等待时间
行锁 ~ 一批操作,都是在事务结束的时候释放锁,所以尽量将有冲突的放在后面减少锁定时间
begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作 InnoDB 表的语句,事务才真正启动
start transaction with consistent snapshot ~ 马上启动一个事务
视图:
用查询语句定义的虚拟表,在调用的时候执行查询语句并生成结果。创建视图的语法是 create view … ,而它的查询方法与表一样
InnoDB 在实现 MVCC 时用到的一致性读视图,即 consistent read view,用于支持 RC(Read Committed,读提交)和 RR(Repeatable Read,可重复读)隔离级别的实现。
InnoDB事务ID严格顺序递增,每行数据也有多个版本,数据表中的一行记录,其实可能有多个版本 (row),每个版本有自己的 row trx_id
三个虚线箭头,就是 undo log;而 V1、V2、V3 并不是物理上真实存在的,而是每次需要的时候根据当前版本和 undo log 计算出来的
InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID。“活跃”指的就是,启动了但还没提交。数组里面事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)
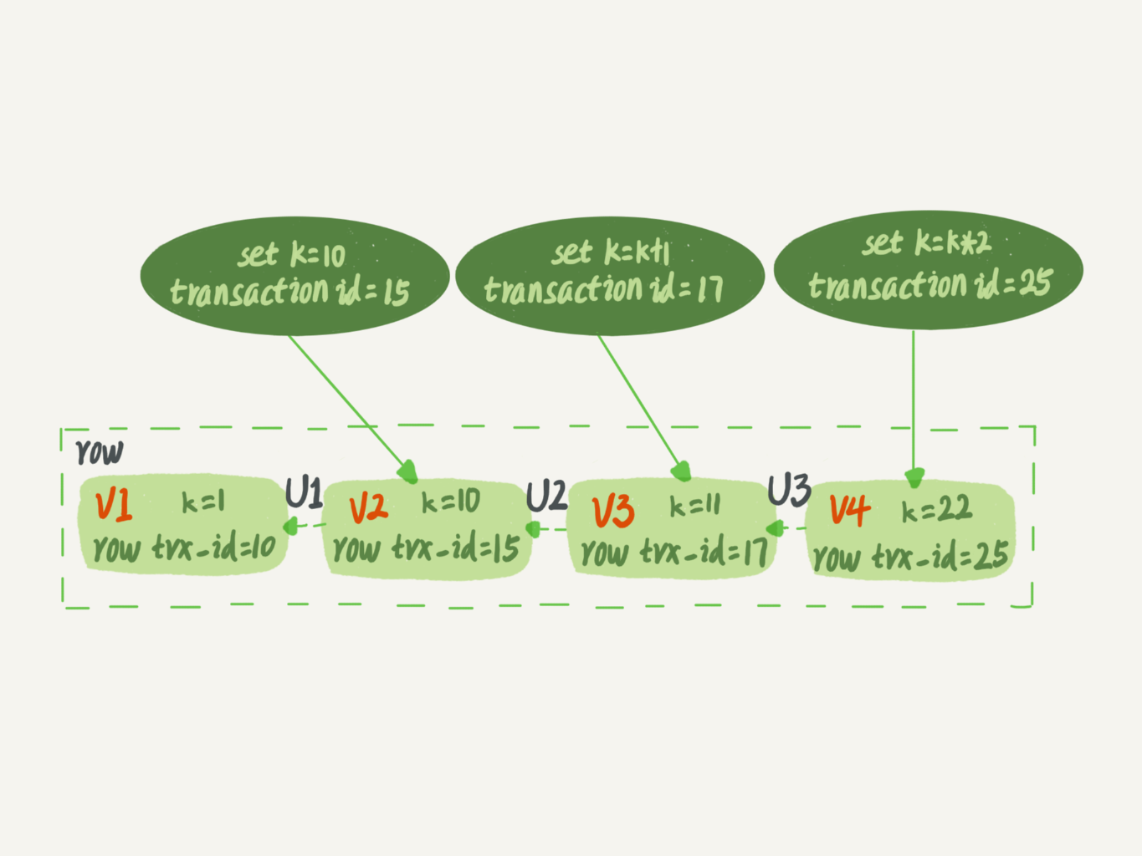
对于可重复读,查询只承认在事务启动前就已经提交完成的数据;
对于读提交,查询只承认在语句启动前就已经提交完成的数据;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号