https://segmentfault.com/a/1190000010237714
http://jm.taobao.org/2018/01/22/post20180122/
对系统的访问速率,资源占用,消费者并发连接数,并行访问数 进行限制,在请求量超过阈值时,通过拒绝等方式,防止服务接口的雪崩和挂掉
同步RPC类调用,针对服务提供者的并发全局流控,或针对服务消费者的并发局部流控
异步MQ类调用,在订阅端限流,针对消息订阅者的并发流控,或针对消息订阅者的消费延时流控。
单机流控 -> 全局流控 -> 动态流控
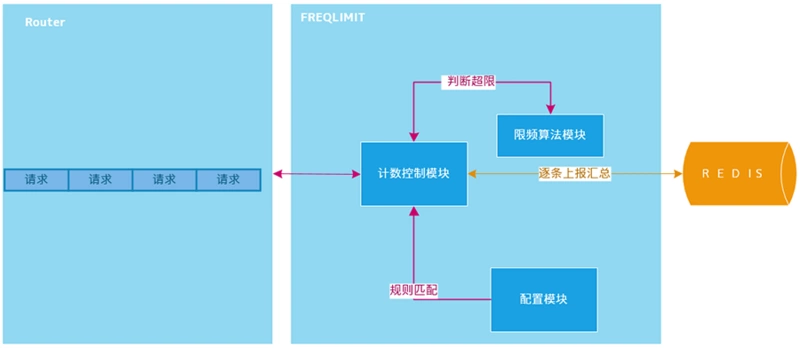
1. 全局计数器的存储 redis
记录两个信息,计数和记间, 因为限制一般是多少请求每秒之类的,过期重置
2. 如何上报请求
全量、定时批量上报
一般还需要每台机器部署agent来完成上报和流控判断,业务模块和agent之间也要通讯
1)将流控服务做成原子化,目前无论使用redis还是ckv,加锁方式并发下无法保证性能,原生的incr方式要解决过期时间的问题,需要的技术门槛和开发成本都比较高;
2)从上报统计方式看,全量上报对请求量巨大的业务部门来说不大可行,定时批量上报又无法保证实时流控;
3)接入全局流控每台机器都需要部署agent,agent能否正常工作影响全局流控的使用,同时部署及运维的成本不低;
令牌桶控制的是一个时间窗口内的通过的数据量,在 API 层面我们常说的 QPS、TPS,正好是一个时间窗口内的请求量或者事务量,只不过时间窗口限定在 1s 罢了。
RateLimiter 对简单的令牌桶算法做了一些工程上的优化,具体的实现是 SmoothBursty。需要注意的是,RateLimiter 的另一个实现 SmoothWarmingUp,就不是令牌桶了,而是漏桶算法。也许是出于简单起见,RateLimiter 中的时间窗口能且仅能为 1s,如果想搞其他时间单位的限流,只能另外造轮子。
http://www.liuhaihua.cn/archives/529035.html
配额拉取的概念,替换一般统计上报的方式,取而代之的是每个key初始化时写入流控阈值,每个业务机器并非上报请求量,而是访问ckv拉取配额到本地保存,本地配额消耗完毕再次拉取,类似余库存扣减。
agent要完成的功能比较简单,主要功能托管到业务流控api。比如拉取配额设置10,即正常10个请求要拉取一次配额,这时流控api会请求一次ckv拉取配额,这个业务请求耗时增加约1ms。
方案对容灾做了充分的考虑,主要解决方式是全局及单机流控同时启用,即基于ckv的全局流控和基于单机共享内存的单机流控都同时工作。
全局流控失效(ckv挂掉或连续超时导致拉取配额失败),流控api判断出这种情况后,暂时停止使用全局流控,而单机流控依然可以正常工作,流控api定期去探查(比如30s)全局流控是否恢复可用,再启动全局流控。
由于使用ckv的incr以及配额拉取的实现方式,全局流控接入服务请求的能力得到成本增长。
目前方案单独申请了一块ckv,容量为6G,使用incr的方式,压测性能达到9w+/s。
对业务空接口(Appplatform框架)做流控压测,使用30台v6虚拟机,单机50进程,压测性能达到50w+/s。
单接口50w/s的请求的服务接入,同样也能满足多接口总体服务请求量50w+/s的全局流控需求。
上述的压测瓶颈主要是Appplatform框架的性能原因,由于拉取配额值是根据流控阈值设定(一般>10),50w+的请求量只有不到5w的ckv访问量,ckv没到瓶颈。
支持平行扩展流控能力,一套全局流控部署能满足流控的服务请求量是达百万/s,更大的服务请求量需要部署多套全局流控。
支持升级到动态流控能力,ckv写入的流控阈值是通过定时管理器完成,目前业务已经做了健康度上报,定时管理器只需要对接健康度数据,分析接口当前请求情况,动态调整流控阈值即可达到动态流控能力。
1、管理定时器:
根据配置,将频率限制任务的配额值,写入多个带时间信息的key。比如频率限制任务1配了阈值为5000/s的全局流控,那么就以每一秒生成一个kv为例:
key为task1_20170617000000、task1_20170617000001、task1_20170617000002等
value为5000
2、共享内存:
保存每一个任务流控相关的本机信息,包括流控状态、本地配额、配额锁等。
3、流控API:
业务通过流控api,请求先扣减本地配额(原子操作),如果配额<=0,就从ckv拉取配额到共享内存中,如果没配额拉取,就做说明流控生效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号