

shell编程之函数与正则表达式
shell函数
shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数。给这段代码起个名字称为函数名,后续可以调用该段代码。
格式:shell函数很简单,函数名后跟双括号,在跟双大括号。通过函数名直接调用,不加小括号
func () { #指定函数名
command #函数体
}
实例:1
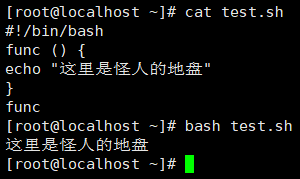
#!/bin/bash
func () {
echo "这里是怪人的地盘"
}
func
bash test.sh
这里是怪人的地盘
实例:2
函数返回值
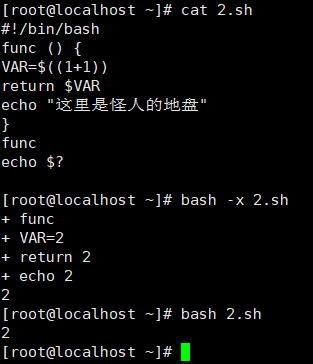
#!/bin/bash
func () {
VAR=$((1+1))
return $VAR
echo "这里是怪人的地盘"
}
func
echo $?
bash test.sh
2
return 在函数中定义状态返回值,返回并终止函数,单反毁的只能是0-255的数字,类似于exit
实例:3
函数传参
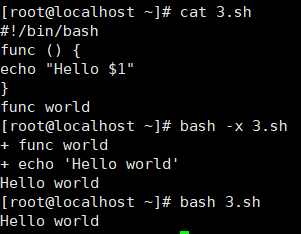
#!/bin/bash
func () {
echo "Hello $1"
}
func world
bash test.sh
Hello world
通过shell位置参数给函数传参
shell正则表达式
正则表达式在每种语言中都有,功能就是匹配符合你预期要求的字符串
shell正则分为两种:
基础正则表达式
扩展正则表达式:+ ? | ()
1.正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
2.通过定义的这些 特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串,linux正则表达式一般以行为单位处理
正则表达式和通配符的本质区别
1.不需要思考的判断方法,在三剑客awk,sed,grep中都是正则,其他的都是通配符
2.区别通配符和正则表达式最简单的方法
(1)匹配文件目录名====》通配符
(2)匹配文件内容====》正则表达式
以grep为例举例说明正则表达式
注意:在匹配模式中一定要加上引号
| 符号 | 描述 | 实例 |
| . | 匹配单个必须存在的字符 |
l..e 可以表示 love like leee 不可以表示的 labcde le lee |
| ^ | 匹配以“”开头的行 |
匹配以 abc 开头的行: echo -e "abc\nxyz" |grep ^abc |
| $ | 匹配以“”结尾的行 |
匹配以 xyz 结尾的行: echo -e "abc\nxyz" |grep xyz$ |
| * | 前面字符出现零到多次 |
a* 表示出现任意个a的情况 a*b 表示b前面有任意个a的情况(包括没有a的情况) |
| .* | 表示任意字符出现零到多次 |
过滤出一行中a在前,b在后的行 条件: 包含 a 和 b 字母 a 必须在 b前面 # grep --color "a.*b" b.txt |
| +(扩展正则) | 表示前面字符出现至少一次 |
匹配 abc 和 abcc: echo -e "abc\nabcc\nadd" |grep -E 'ab+' 匹配单个数字:echo "113" |grep -o '[0-9]' 连续匹配多个数字:echo "113" |grep -E -o '[0-9]+' |
| ?(扩展正则) | 表示前面字符最多出现一次 |
匹配 ac 或 abc: echo -e "ac\nabc\nadd" |grep -E 'a?c' |
| [] | 表示范围内的一个字符 |
例子:过滤出包含小写字母的行 grep [a-z] a.txt 例子:过滤出包含大写字母的行 grep [A-Z] a.txt 例子:过滤出包含数字的行 grep [0-9] a.txt 例子:过滤出包含数字和小写字母的行 grep [0-9a-z] a.txt 例子:过滤出包含字母asf的行 grep [asf] a.txt |
| [.-.] | 匹配括号中的任意一个字符 |
匹配所有字母 echo -e "a\nb\nc" |grep '[a-z]' |
| [^] | 匹配除了某字符的任意一个字符 |
匹配 a 或 b: echo -e "a\nb\nc" |grep '[^c-z]' 匹配末尾数字:echo "abc:cde;123" |grep -E '[^;]+$' |
| ^[^] | 匹配除了某字符开头的行 |
匹配不是#开头的行: grep '^[^#]' /etc/httpd/conf/httpd.conf |
| {n}或{n,} |
{n}:表示严格匹配n个字符 {n,}:表示花括号钱的字符至少存在n个 |
echo "aadadccc" | egrep "a{2}" echo "aadadccc" | egrep "a{1}" |
| {n,m} |
匹配字符至少出现n次,最多出现m次 |
"ac\{2,5\}b" 匹配a和b之间有最少2个c最多5个c的行 "ac\{,5\}b" 匹配a和b之间有最多5个c的行 "ac\{2,\}b" 匹配a和b之间有最少2个c的行 |
| \< | 锚定单词首部(匹配字符必须以锚定字符开头) | # echo "hi,root,iamroot" | grep "\<root" hi,root,iamroot |
| \> | 锚定单词尾部(匹配字符必须以锚定字符结尾) | # echo "hi,root,iamroot" | grep "root\>" hi,root,iamroot |
| () | \1 调用前面的第一个分组 |
例子:过滤出一行中有两个相同数字的行 # grep "\([0-9]\).*\1" inittab 例子:过滤出行首和行位字母相同的行 # grep "^\([a-z]\).*\1$" inittab |
| |(扩展正则) | 匹配 | 两边的任意一个 |
过滤出cat 或者Cat # grep "cat|Cat" a.txt # grep "(C|c)at" a.txt |
总结
正则表达式
一、字符匹配
.
[]
[^]
二、次数匹配
*
\{m,n\}
三、锚定
^
$
\<
\>
四、分组
\(\)
\1
扩展正则表达式
grep -E
egrep
一、字符匹配
.
[]
[^]
二、次数匹配
*
{m,n}
+ 表示其前面的字符出现最少一次的情况
?表示其前面的字符出现最多一次的情况
三、锚定
^
$
\<
\>
四、分组
()
\1
\2
五、或
|
一.、正则表达式中的{}以及()都需要加上\进行转义,而扩展正则表达式不需要
二 、|, ?,+是扩展正则独有的
三、 锚定单词首部和尾部在扩展正则以及正则中都需要加上\

