

(五)Java集合
Java集合
1、Java集合(容器)
Java 容器分为 Collection 和 Map 两大类,各自都有很多子类。
Collections是一个包装类,包含有关集合的各种静态方法,不能被实例化,Collections集合框架的工具类。
java.util.concurrent包下的所有集合类都是线程安全。
List和Set继承自Collection<E>接口,Map<K,V>是一个接口可以被其他接口继承。
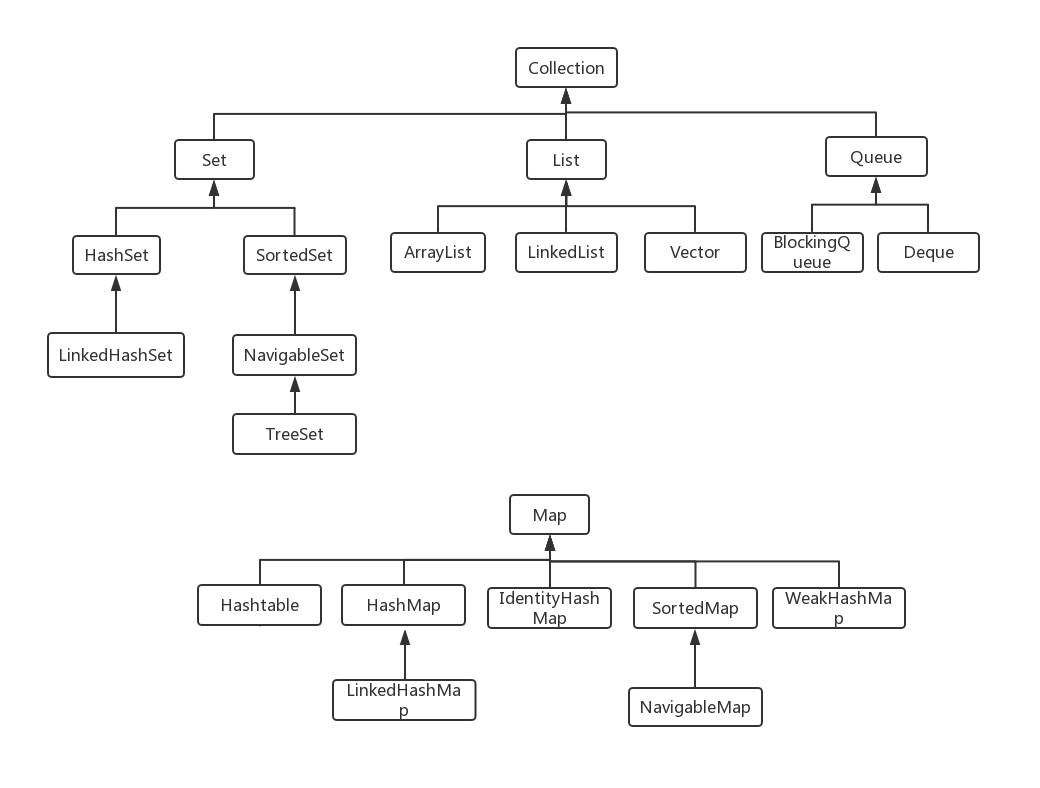
Collection接口(集合层次结构的最根本的接口,定义了集合基本方法)
| ├AbstractCollection 对Collection接口的最小化抽象实现
| │
| ├List 有序可重复集合
| │-├AbstractList 有序集合的最小化抽象实现
| │-├ArrayList 基于数组实现的有序集合(无参构造初始长度为10,长度可变,每次扩容0.5倍,底层是动态数组,非线程安全,允许存储null,不适用泛型的时候,可以添加不同类型的元素)
| │-├LinkedList 基于链表实现的有序集合(底层是双向链表,非线程安全,允许存储null)
| │-└Vector 矢量队列(长度可变,每次扩容1倍,底层是数组,线程安全)
| │ └Stack 栈,先进后出(线程安全)
| │
| ├Set 不重复集合(1、数组转List:asList()方法2、List转数组:toArray() 方法,返回Object数组)
| │├AbstractSet 不重复集合的最小化抽象实现
| │├HashSet 基于hash实现的不重复集合,无序,支持null(线程不安全)
| │├LinkedHashSet 基于hash实现的不重复集合,有序(按照插入排序,遍历效率高 于HashSet)
| │└SortedSet 可排序不重复集合
| │ └NavigableSet 可导航搜索的不重复集合
| │ └TreeSet 基于红黑树实现的可排序不重复集合(添加数据的时候必须实现Comparable接口或创建TreeSet对象的时候传入Comparator对象)
| │
| ├Queue 队列
(Queue队列的添加元素方法:add()方法和offer()方法
在容量已满的情况下,add()方法会抛出
IllegalStateException异常,offer()方 法只会返回false。
Queue的从头部删除一个元素方法:remove()方法和 poll()方法,在队列元素 为空的情况下,remove()方 法会抛出NoSuchElementException异常,poll() 方 法只会返回null。
Queue的返回队列的头元素方法,不删除:element()方 法和peek()方法,在 队列元素为空的情况下, element()方法会抛出NoSuchElementException异 常,peek()方法只会返回null。)
| │├AbstractQueue 队列的核心实现
| │├BlockingQueue 阻塞队列
| │└Deque 可两端操作线性集合
|
Map 键值映射集合(key无序唯一,value不要求有序可重复)
| ├AbstractMap 键值映射集合最小化抽象实现
| ├Hashtable 基于哈希表实现的键值映射集合,key、value均不可为null (线程安全,效率低)
| └Properties 用来处理配置文件,key和value都是String类型
| ├HashMap 类似Hashtable,但方法不同步,key、value可为null(不支持排序,基于散列桶,即底层是数组和链表,非线程安全)
| └LinkedHashMap 根据插入顺序实现的键值映射集合(有序)
| ├IdentityHashMap 基于哈希表实现的键值映射集合,两个key引用相等==,认为是同一个key
| ├SortedMap 可排序键值映射集合
| └NavigableMap 可导航搜索的键值映射集合
| └WeakHashMap 弱引用建,不阻塞被垃圾回收器回收,key回收后自动移除键值对
| ├TreeMap (本身就具备了保持元素唯一的特点)可以排序的Map集合,可以定制排序和自然排序(当元素实现了Comparable接口,重写compareTo方法之后,当进行排序会自动调用compareTo方法,就会有一个返回0的情况,一旦compareTo等待返回了0 ,就认为是同一个元素)
可以比较的点:
-
有序、无序
-
可重复、不可重复
-
键、值是否可为null
-
底层实现的数据结构(数组、链表、哈希...)
-
线程安全性
2、迭代器Iterator
-
首先说一下迭代器模式,它是 Java 中常用的设计模式之一。用于顺序访问集合对象的元素,无需知道集合对象的底层实现。
-
Iterator 是可以遍历集合的对象,为各种容器提供了公共的操作接口,隔离对容器的遍历操作和底层实现,从而解耦。
-
缺点是增加新的集合类需要对应增加新的迭代器类,迭代器类与集合类成对增加。
Iterator 接口源码中的方法
-
java.lang.Iterable 接口被 java.util.Collection 接口继承,java.util.Collection 接口的 iterator() 方法返回一个 Iterator 对象
-
next() 方法获得集合中的下一个元素
-
hasNext() 检查集合中是否还有元素
-
remove() 方法将迭代器新返回的元素删除
-
forEachRemaining(Consumer<? super E> action) 方法,遍历所有元素
Iterator和ListIterator的区别
-
ListIterator 继承 Iterator
-
ListIterator 比 Iterator多方法
1) add(E e) 将指定的元素插入列表,插入位置为迭代器当前位置之前 2) set(E e) 迭代器返回的最后一个元素替换参数e 3) hasPrevious() 迭代器当前位置,反向遍历集合是否含有元素 4) previous() 迭代器当前位置,反向遍历集合,下一个元素 5) previousIndex() 迭代器当前位置,反向遍历集合,返回下一个元素的下 标 6) nextIndex() 迭代器当前位置,返回下一个元素的下标
-
使用范围不同,Iterator可以迭代所有集合;ListIterator 只能用于List及其子类
-
ListIterator 有 add 方法,可以向 List 中添加对象;Iterator 不能
-
ListIterator 有 hasPrevious() 和 previous() 方法,可以实现逆向遍历;Iterator不可以
-
ListIterator 有 nextIndex() 和previousIndex() 方法,可定位当前索引的位置;Iterator不可以
-
ListIterator 有 set()方法,可以实现对 List 的修改;Iterator 仅能遍历,不能修改
3、TreeSet原理
TreeSet 基于 TreeMap 实现,TreeMap 基于红黑树实现
特点:
-
有序
-
无重复
-
添加、删除元素、判断元素是否存在,效率比较高,时间复杂度为 O(log(N))
使用方式:
-
TreeSet 默认构造方法,调用 add() 方法时会调用对象类实现的 Comparable 接口的 compareTo() 方法和集合中的对象比较,根据方法返回的结果有序存储
-
TreeSet 默认构造方法,存入对象的类未实现 Comparable 接口,抛出 ClassCastException
-
TreeSet 支持构造方法指定 Comparator 接口,按照 Comparator 实现类的比较逻辑进行有序存储
4、HashSet和HashMap区别
JDK8
HashMap
-
实现 Map 接口
-
键值对的方式存储
-
新增元素使用 put(K key, V value) 方法
-
底层通过对 key 进行 hash,使用数组 + 链表或红黑树对 key、value 存储
HashSet
-
实现 Set 接口
-
存储元素对象
-
新增元素使用 add(E e) 方法
-
底层是采用 HashMap 实现,大部分方法都是通过调用 HashMap 的方法来实现
5、TreeMap和TreeSet排序时如何比较元素
-
TreeMap 会对 key 进行比较,有两种比较方式,第一种是构造方法指定 Comparator,使用 Comparator#compare() 方法进行比较;第二种是构造方法未指定 Comparator 接口,需要 key 对象的类实现 Comparable 接口,用 Comparable #compareTo() 方法进行比较
-
TreeSet 底层是使用 TreeMap 实现
6、Collections工具类中的sort方法如何比较元素
Collections 工具类的 sort() 方法有两种方式
-
第一种要求传入的待排序容器中存放的对象比较实现 Comparable 接口以实现元素的比较
-
第二种不强制性的要求容器中的元素必须可比较,但要求传入参数 Comparator 接口的子类,需要重写 compare() 方法实现元素的比较规则,其实就是通过接口注入比较元素大小的算法,这就是回调模式的应用
7、去除List的相同元素
1 public class TestRemoveListSameElement { 2 3 public static void main(String[] args) { 4 List<String> l = Arrays.asList("1", "2", "3", "1"); 5 Set<String> s = new HashSet<String>(l); 6 System.out.println(s); 7 } 8 9 }
8、Vector、ArrayList、LinkedList 的存储性能和特性
-
ArrayList 和 Vector 都是使用数组存储数据
-
允许直接按序号索引元素
-
插入元素涉及数组扩容、元素移动等内存操作
-
根据下标找元素快,存在扩容的情况下插入慢
-
Vector 对元素的操作,使用了 synchronized 方法,性能比 ArrayList 差
-
Vector 属于遗留容器,早期的 JDK 中使用的容器
-
LinkedList 使用双向链表存储元素
-
LinkedList 按序号查找元素,需要进行前向或后向遍历,所以按下标查找元素,效率较低
-
LinkedList 非线程安全
-
LinkedList 使用的链式存储方式与数组的连续存储方式相比,对内存的利用率更高
-
LinkedList 插入数据时只需要移动指针即可,所以插入速度较快
9、Map的遍历方式
-
Map 的 keySet() 方法,单纯拿到所有 Key 的 Set
-
Map 的 values() 方法,单纯拿到所有值的 Collection
-
keySet() 获取到 key 的 Set,遍历 Set 根据 key 找值(不推荐使用,效率比下面的方式低,原因是多出了根据 key 找值的消耗)
-
获取所有的键值对集合,迭代器遍历
-
获取所有的键值对集合,for 循环遍历
10、List、Set、Map接口的特点与常用实现类
List 和 Set 实现了 Collection 接口。
List:
-
允许重复的对象
-
可以插入多个 null 元素
-
是有序容器,保持了每个元素的插入顺序
-
常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList,它提供了使用索引的随意访问,LinkedList 更合适经常添加或删除元素的场景
Set:
-
不允许重复对象
-
只允许一个 null 元素
-
Set 接口最常用的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。HashSet 基于 HashMap 实现;LinkedHashSet 按照插入排序;TreeSet 通过 Comparator 或 Comparable 接口实现排序
Map:
-
是单独的顶级接口,不是 Collection 的子接口
-
Map 的 每个 Entry 都持有两个对象,key 和 value,key 唯一,value 可为 null 或重复
-
Map 接口常用的实现类有 HashMap、LinkedHashMap、Hashtable 和 TreeMap
-
Hashtable 和 未指定 Comparator 的 TreeMap 不可为 null;HashMap、LinkedHashMap、指定 Comparator 的 TreeMap 的 key 可以为 null
11、HashMap的实现原理(JDK8)
-
HashMap 基于 Hash 算法实现,通过 put(key,value) 存储,get(key) 来获取 value
-
当传入 key 时,HashMap 会根据 key,调用 hash(Object key) 方法,计算出 hash 值,根据 hash 值将 value 保存在 Node 对象里,Node 对象保存在数组里
-
当计算出的 hash 值相同时,称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value
-
当 hash 冲突的个数:小于等于 8 使用链表;大于 8 且 tab length 大于等于 64 时,使用红黑树解决链表查询慢的问题
12、ConcurrentHashMap原理
HashMap 是线程不安全的,效率高;HashTable 是线程安全的,效率低。
ConcurrentHashMap 可以做到既是线程安全的,同时也可以有很高的效率,得益于使用了分段锁。
13、Vector、ArrayList、LinkedList的异同
相同:都实现了List接口,存储的特点相同
不同:
ArrayList:线程不安全,效率高,底层是数组,查询方便,插入删除不合适
LinkedList:线程不安全,底层是双向链表,对于频繁的插入、删除操作,使用此类比ArrayList效率高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号