
转载于:https://www.cnblogs.com/xuziyu/p/10901284.html
1.Azkaban 简介
- azkaban是一个开源的任务调度系统,用于负责的调度运行(如数据仓库调度),用以替代Linux中的crontab。
- Azkaban是一套简单的任务调度服务,整体包括三个部分webserver、dbserver、executorserver
- Azkaban是linux的开源项目,开发语言为Java。
- Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程
- Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流
1.1使用场景
当有一个大job,由4个小job构成,这4个job分别为jobA,jobB,jobC,jobD。其中jobB和jobC依赖于jobA,jobD依赖于jobB和jobC的结果如下图所示

2.常用工作流对比
Oozie:重量级的,不推荐使用,开发需要写一堆XML配置,非常麻烦
Azkzban:轻量级的,推荐使用,具有很好的WEBBUI交互设计,但是也是比较难用的,部分功能需要自定义开发,如无短信通知功能。
3.安装Azkabab
安装以3.57.0版本的Azkaban需要有jdk1.8、gradle、git环境,gradle是类似于maven的jar依赖的管理工具。
3.1下载
- 进入官网 官网地址:https://azkaban.github.io/ 按照下图的箭头指示下载



- 这两个你下载那一个都可以
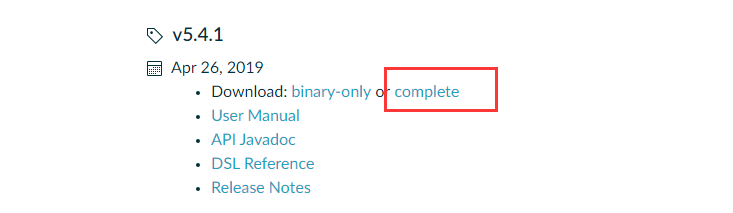
3.2下载gradle: 官网地址
- 选择你想用的版本,并点击complete下载
3.3把Azkaba的安装包和gradle的安装包上传到你的linux,并且解压

[root@hadoop001 software]# pwd /root/software [root@hadoop001 software]# ll -rw-r--r-- 1 root root 132768903 May 14 10:08 gradle-5.4.1-all.zip [root@hadoop001 software]# unzip gradle-5.4.1-all.zip [root@hadoop001 software]# ll drwxr-xr-x 9 root root 4096 Feb 1 1980 gradle-5.4.1 ##解压目录没有太多要求 解压Azkaban tar -zxvf /home/hadoop/sourcecode/azkaban-3.57.0.tar.gz -C /home/hadoop/app/
3.4安装git
yunm install -y git
3.5编译Azkaban
./gradlew build installDist -x test ##-test是跳过测试 降低编译时间 [hadoop@hadoop001 azkaban-3.57.0]# ./gradlew build installDist -x test
如果按照以上步骤来,基本上编译不会报错,所有的包都要保证是从官网下载的
如果有报错可以参考一下这个博客:https://blog.csdn.net/qq_32641659/article/details/90217430#1WorkFlow_1
3.6编译成功以后,查看部署包
azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz为单机部署的包 [hadoop@hadoop001 azkaban-3.57.0]$ cd azkaban-solo-server/build/distributions/ [hadoop@hadoop001 distributions]$ ll total 46752 -rw-rw-r--. 1 hadoop hadoop 23870855 May 2 20:10 azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -rw-rw-r--. 1 hadoop hadoop 24001502 May 2 20:10 azkaban-solo-server-0.1.0-SNAPSHOT.zip [hadoop@hadoop001 distributions]$ mv azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz /home/hadoop/app/ [hadoop@hadoop001 distributions]$ cd /home/hadoop/app/ [hadoop@hadoop001 app]$ tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C ~/app/
4启动
4.1注意要在安装目录启动,踩坑
[hadoop@hadoop001 azkaban-solo-server-0.1.0-SNAPSHOT]$ bin/start-solo.sh [hadoop@hadoop001 azkaban-solo-server-0.1.0-SNAPSHOT]$ jps 19345 AzkabanSingleServer 19362 Jps
4.2关闭命令
[hadoop@hadoop001 azkaban-solo-server-0.1.0-SNAPSHOT]$ bin/shutdown-solo.sh
4.3编辑配置文件
[root@hadoop001 conf]# pwd
/home/hadoop/app/azkaban-solo-server-0.1.0-SNAPSHOT/conf
total 8
-rw-rw-r-- 1 root root 2001 May 16 10:11 azkaban.properties
-rw-rw-r-- 1 root root 361 May 16 09:02 azkaban-users.xml
-rw-rw-r-- 1 root root 0 Sep 5 2018 global.properties
[root@hadoop001 conf]# vim azkaban-users.xml
# 添加用于登录的admin用户
<user password="123456" roles="admin" username="itocean"/>
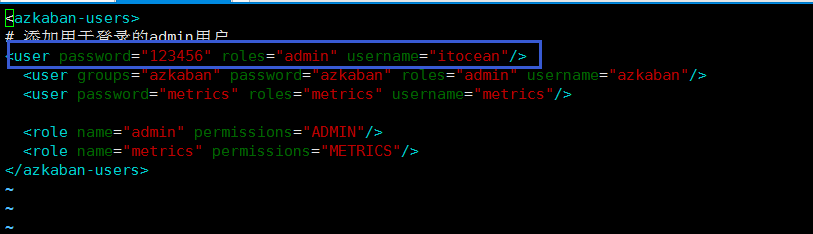
[root@hadoop001 conf]#vim azkaban.properties
# 修改
azkaban.name
azkaban.label

看你心情想修改成啥就修改成啥
5启动
# 不要进入bin目录执行,否则会找找不到相应的配置
./bin/start-solo.sh
6查看日志
tail -f local/azkaban-webserver.log
![]()
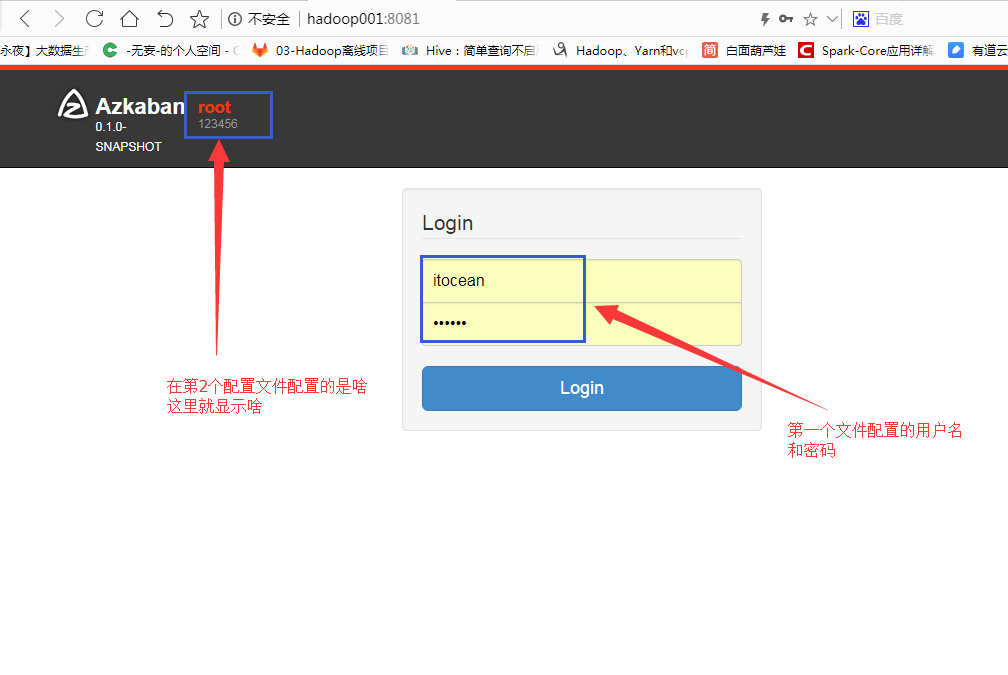
7查看Web界面
http://hadoop001:8081/
##8081是默认端口号
![]()
8.创建项目

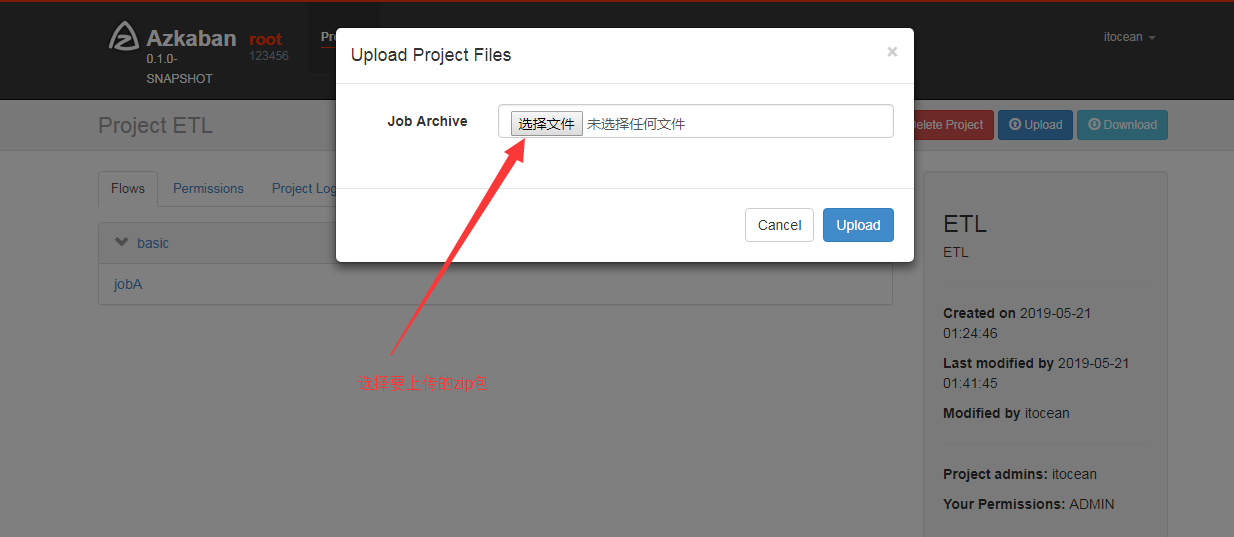
9.创建一个简单flow
一个flow是由.project以及.flow两个文件构成
- 编辑flow20.project文件
azkaban-flow-version: 2.0
- 编辑basic.flow,basic则是flow的名称配置具体作业信息,作业名jobA,作业的类型命令,作业配置,执行的命令
nodes:
- name: jobA
type: command
config:
command: touch /tmp/job1.txt

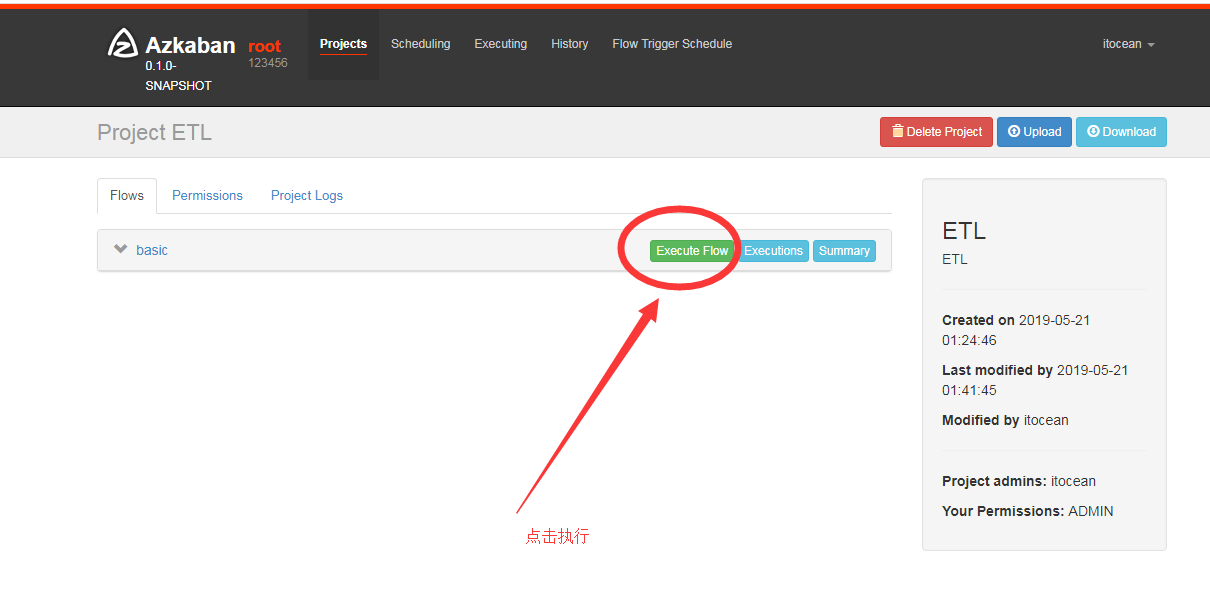

10.查看执行结果

可以看到已经创建了job1.txt文件
11.依赖作业的模式
创建basic.flow,写入以下内容
nodes:
- name: jobC
type: noop
# jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB
- name: jobA
type: command
config:
command: echo "This is an echoed text."
- name: jobB
type: command
config:
command: pwd
同上一样把flow20.project和basic.flow一起打zip包并创建新的项目上传zip包
执行后得到,从图中可以看到jobC依赖于jobA和jobB

参考博客:https://www.cnblogs.com/shujuxiong/p/9116394.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号