
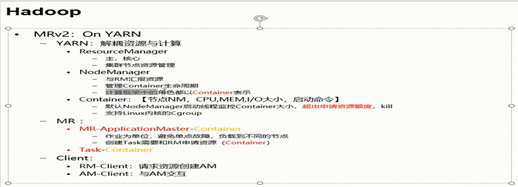
yarn的诞生:hadoop1.x版本JobTracker的作用是资源管理和任务的调度,当存在多个计算框架时,比如说spark,如果两个计算框架都有着自己的资源管理模块,就会存在资源竞争,不便于管理。此时就需要一个公共的资源管理模块,这就产生了YARN.
hadoop2.x上的mapreduce是基于YARN 的,YARN支持多个计算框架,就比如说刚才说的SPARk.
YARN的工作原理图:
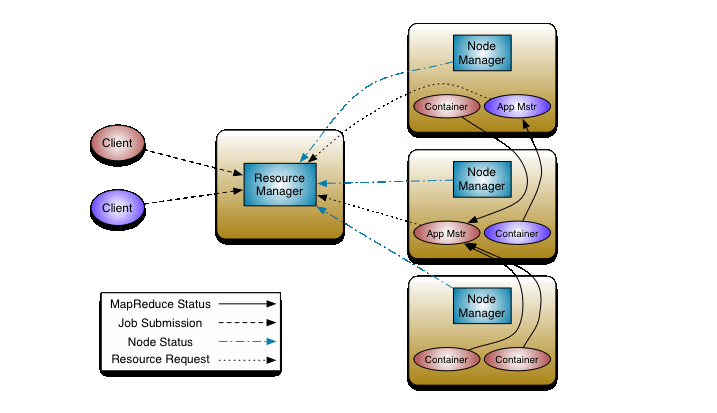
Yarn上可以支持多个计算框架(MapReduce,spark)
Yarn上的每一个Node Manager 都与每一个dataNode与之对应
Yarn原理过程:
一个客户端A向resource manager 提交请求,resource manager就会会产生一个application master(相当于mapreduce1.x中的jobTracker中的调度模块),resource manager会在hdfs中获取split的信息(被切成了多少块),然后向resource manager申请有多少个mapTask,然后resource manager 会产生多个Container分布在多个节点上(分布在哪个节点上由resource manager控制)
一个客户端B向resource manager 提交请求,resource manager又会会产生一个application master(相当于mapreduce1.x中的jobTracker中的调度模块),resource manager会在hdfs中获取split的信息(被切成了多少块),然后向resource manager申请有多少个mapTask,然后resource manager 会产生多个Container(默认占用空间1个G)分布在多个节点上(分布在哪个节点上由resource manager控制)
Resource manager 又会存在单点故障,此时又需要用到ha来实现高可用性。
mapTask 和 reduceTask都是在节点上的container上运行的。

将yarn配置好后,执行hadoop上的mapreduce例子,进行简单的测试。
Hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /usr/root/text.txt /data/wc/output
注意:/data/wc/output目录必须是空的,或者不存在的。否则的话,hadoop会报错。
下面是yarn-site.xml的配置:
<configuration> <!-- Site specific YARN configuration properties --> <!—配置此项,则nodemanager会自动拉取hdfs中的数据,否则无法mapTask无法获取到数据进行计算--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!—resource manager 开启ha开关实现高可用--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!—resource manager ha集群服务名--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarnhacluster</value> </property> <!—resource manager ha虚拟到物理的映射--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node3</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node4</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node3:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node4:8088</value> </property> <!—resource mangager故障转移切换与zookeeper相结合 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>node2:2181,node3:2181,node4:2181</value> </property> </configuration>
Mapred-site.xml文件中的配置:
<configuration> <!—mapreduce 基于yarn来实现离线计算的,基础开关 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
转载于:https://www.cnblogs.com/yehuili/p/9946010.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号