
Hadoop 1.0存在的问题:单点故障和内存受限
(1)NameNode单点故障(NameNode只有一个,一旦宕机了,则数据就会丢失,虽然有配置SecondaryNameNode,但是SecondardyNameNode
合并元数据和日志文件需要时间的,所有还是会有部分数据会丢失)
(2)NameNode压力大(单节点只有一个NameNode,所有的请求都访问一个NameNode)
Hadoop 2.0解决方案:
单点故障:HA(通过主备NameNode解决,如果主NameNode发生故障,则切换到备NameNode上)
内存受限问题:F(HDFS Federation 联邦)
水平扩展,支持多个NameNode,每一个NameNode分管一部分目录,并且所有NameNode共享DateNode存储资源
现在只讨论HA的实现:
HA:客户端只有和一个NameNode(主)进行通信,而元数据部分是如何和NameNode(备)进行共享的?(首先dataNode 的信息是共享的,主NameNode和备NameNode这部分信息是一致的,而元数据不一样,不是实时的)
想法一:主Namenode和备Namenode之间建立一个socket通信(阻塞型通信),这样两个NameNode和DataNode的元数据就是一致的了(同时会引发一个问题,IO网络通信的问题,如果之间网络一旦出现问题,则客户端会认为主Namenode出现了问题,因为整个流程是这样的,客户端发送一个请求给主NameNode,然后主Namenode再发送给备Namenode,而此时网络发生波动的话,请求就会一直阻塞在那里直到备NameNode返回成功的状态,所以客户端会认为是主Namenode有问题),所以这个想法不可行。
想法二:主NameNode和备NameNode之间建立一个非阻塞的通信(就是客户端发送请求给主Namenode,然后主NameNode再发送给备NameNode,不需要等待备NameNode的返回状态,这样的话如果备NameNode发生问题,就会导致两个NameNode之间元数据不一致)所以这个想法也不可行。
想法三:当客户端发送请求给主NameNode时,元数据写到一个共享的磁盘中(两个Namenode都可以访问),这样元数据就可以保持一致了。这种技术就叫做NFS技术。
NFS:
但是NFS运维成本太高,所以Hadoop本身开发了一种技术,JNN(JournalNode)还是集群部署的,(保证了NameNode的高可用性)
ZookeeperFailOverController :Hadoop 配置ZKFC来实现自动故障转移,这两个都是在namenode上的JVM进程,用来监测主NameNode是否发生宕机的,如果发送宕机则向zookeeper汇报,zookeeper将原先注册的锁事件进行删除,然后zookeeper在锁事件删除后会回调备用NameNode发送的锁请求,将自动将备用NameNode变成主Namenode,并且备Namenode的状态由standby变成了Active
Zookeeper在HDFS-HA中起着什么样的角色?
Zookeeper:在HDFS-HA搭建的过程中起着分布式协调作用
1、 zookeeper提供目录结构树机制,两个ZKFC进行资源抢夺,谁抢夺上了,谁就可以在zookeeper上建立一个节点目录,并且创建一把锁,与此同时将与自身关联的Namenode的状态置为Active活跃状态(主Namenode),另一个置为standBy(静态的也叫备NameNode)。
2、 事件回调和监控,zkfc一旦监测到主NameNode发生宕机则,主Namenode节点上的zkfc会将zookeeper上创建的节点目录进行删除,此时zookeeper会回调之前备zkfc在zookeeper上注册的事件,将备zkfc从standBy变成Active的状态。
3、 Session机制:如果zkfc的进程挂了,那么tcp连接就会断开,tcp断开有个会话超时时间范围,一旦超过这个范围,zookeeper就会将主zkfc之前注册的节点进行删除事件的操作,此时zookeeper就会回调备zkfc注册的节点事件,将备zkfc下的Namenode进行状态转换为Active,并且同时将主Namenode的状态变成standBy,这样的话就不会同时存在两个Active的NameNode。
Zkfc(zookeeper Failover Controller)和namenode是在同一个节点上。
HDFS Fedration联邦方式解决高可用问题:
两个NameNode的状态都是活跃的,但是两个NameNode的元数据是不一样的,也就是说存储的目录机构是不一样的。但是接受客户端访问的请求量上去了,但与此同时NameNode还是有单点故障的,所以还是要加上HA,就可以解决单点故障的问题。至于客户端访问那个NameNode这就交给代理来处理就可以了,就比如说Ngix,搭建一个ngix来负载均衡。
这里邦联不细究了。
现在来搭建一下HDFS-HA来实现HDFS的高可用。(解决单点故障问题),下面是结构图:
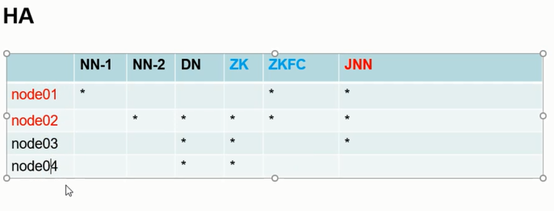
因为资源有限所以这么搭建:
本来zookeeper集群搭建就应该放三台服务器
JNN应该放三台服务器上
NameNode放在两台服务器上
Node1节点上有NameNode 和一个zkfc(JVM进程负责监测NameNode并且和zookeeper进行通信的)和JNN(主NameNode 和从Namenode元数据同步的技术,一般都是集群搭建,至少3个)
Node2节点上有NameNode 和一个secondaryNameNode(在搭建HA之前是有SecondaryNamenodede,但是搭建HA时,是不需要SecondaryNameNode的,这是冲突的,hdfs-site.xml中需要取消这个配置) 和一个DataNode 和一个zookeeper
和一个zkfc 和一个JNN
HDFS中免秘钥应用场景有哪些?
(1) 启动脚本控制节点起停,就是node1(Namenode)启动时顺便把node2,node3,node4上的dataNode启动
(2) 对方Zkfc(A对象的zkfc)控制对方namenode(B对象的namenode)状态时需要通信,需要免秘钥,当其中一个zkfc(A对象的zkfc)挂掉时,对方的zkfc(B对象的zkfc)将会把对方的namenode(A对象的namenode)的状态变成standby,然后将自身的namenode(B对象的Namenode)的状态置为Active。
HA配置文件:
(1) 逻辑位置到物理位置的映射(因为有两个Namenode,客户端无法直接同时访问两个Namenode,所以要配置一个逻辑位置,然后逻辑位置映射到实际的物理位置)
(2) JouaryNode的配置,写入到磁盘文件的路径(就是两个Namenode共享的元数据的信息Edits.Log中的信息。)还有journalNode的位置信息
(3) 免秘钥配置,failover zkfc发生故障时,需要通信将对方的namenode状态修改
同一个zookeepr集群可以为多个hdfs集群服务(只要hdfs集群取不同的名称就可以具体的在hdfs-site.xml文件中配置)
同一个JouaryNode集群可以为多个hdfs集群服务(只要hdfs集群取不同的名称就可以具体的在hdfs-site.xml文件中配置)
关于HDFS-HA方式部署大概有哪些步骤?
(1)配置好HA的配置文件(看文章最后面有贴出配置)
(3) 启动JNN(jouaryNode集群)(hadoop-daemon.sh start journalnode)hadoop-daemon.sh start journalnode
(4) Hdfs namenode –format(格式化namenode前启动jouaryNode是因为namenode格式化fsimage和edits.log文件,如果两个namenode都格式化,会造成fsimage中的数据不一致,所以要先启动jounaryNode,然后再格式化Namenode,然后将fsimage共享给另一个namenode)hdfs namenode -format
(5) 启动第一个namenode(hadoop-daemon.sh start namenode)
(6) 然后以-bootstrapStandby启动第二个namenode (将这个namenode设置为备用namenode) hdfs namenode -bootstrapStandby 如果这步报错了,看下面注意部分
(7) 启动zookeeper集群,每个zookeeper节点上执行: zkServer.sh start
(8) 格式化zkfc:hdfs zkfc -formatZK(因为zkfc依赖于zookeeper,因为格式化后会加一把锁在zookeeper上,会在zookeeper集群上创建一个节点,如果此时zookeeper未启动的话,会报错)
(9) 启动zookeeper客户端查看zkfc是否生成对应的目录结构 zkCli.sh 回车
(10) 启动hadoop集群 start-dfs.sh
(11) 在zookeeper客户端可以查看到生成了锁,使用get获取锁的信息:锁是node1的
特别要注意的是(我已经踩了这个坑):/etc/hosts文件 127.0.0.1 localhost node1 localhost4 localhost4.localdomain4一定要写成192.168.234.11 localhost node1 localhost4 localhost4.localdomain4,因为在主namenode格式化然后启动之后,将第二个namenode置为standby状态时,会报错(FATAL ha.BootstrapStandby: Unable to fetch namespace information from active NN at node1/192.168.234.11:8020: Call From node2/127.0.0.1 to node1:8020 failed on connection exception: java.net.ConnectException: Connection refused;),其实报错的时候可以看下主namenode下监听8020端口时的ip地址(命令:netstat -antp | fgrep 8020),这时你会发现是127.0.0.1所以备namenode在置为standby时会报错,主namenode拒接链接备namenode.
如果发生了做如下操作:(1)修改/etc/hosts文件将127.0.0.1修改成实际的ip (2)重启sshd服务 service sshd restart (3)重启网络 service network restart
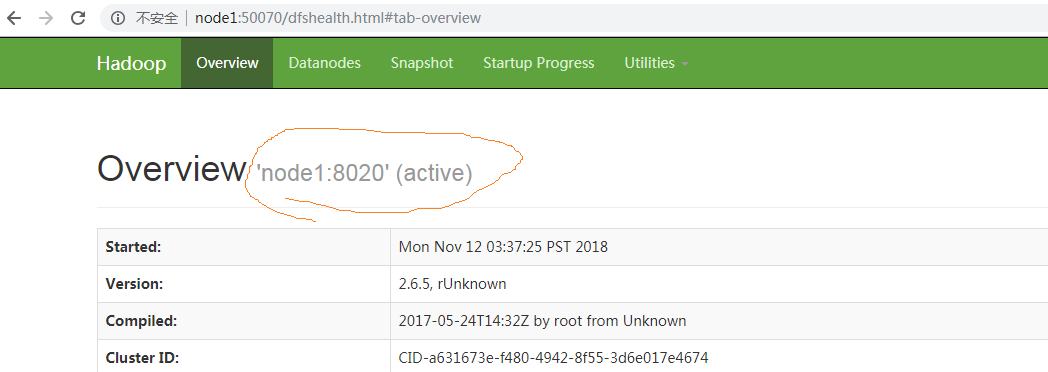
现在进页面看下效果
看下在zookeeper 那里注册的锁信息:
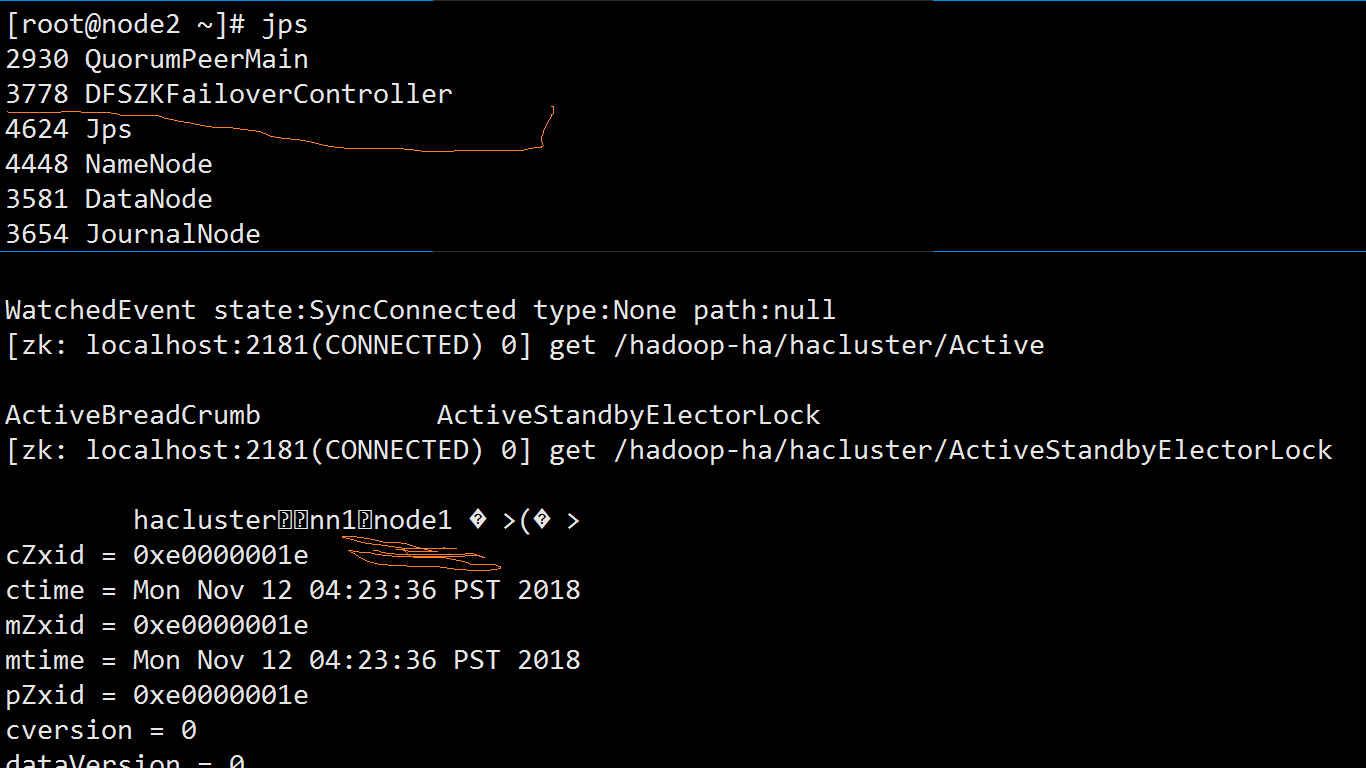
Node1为active
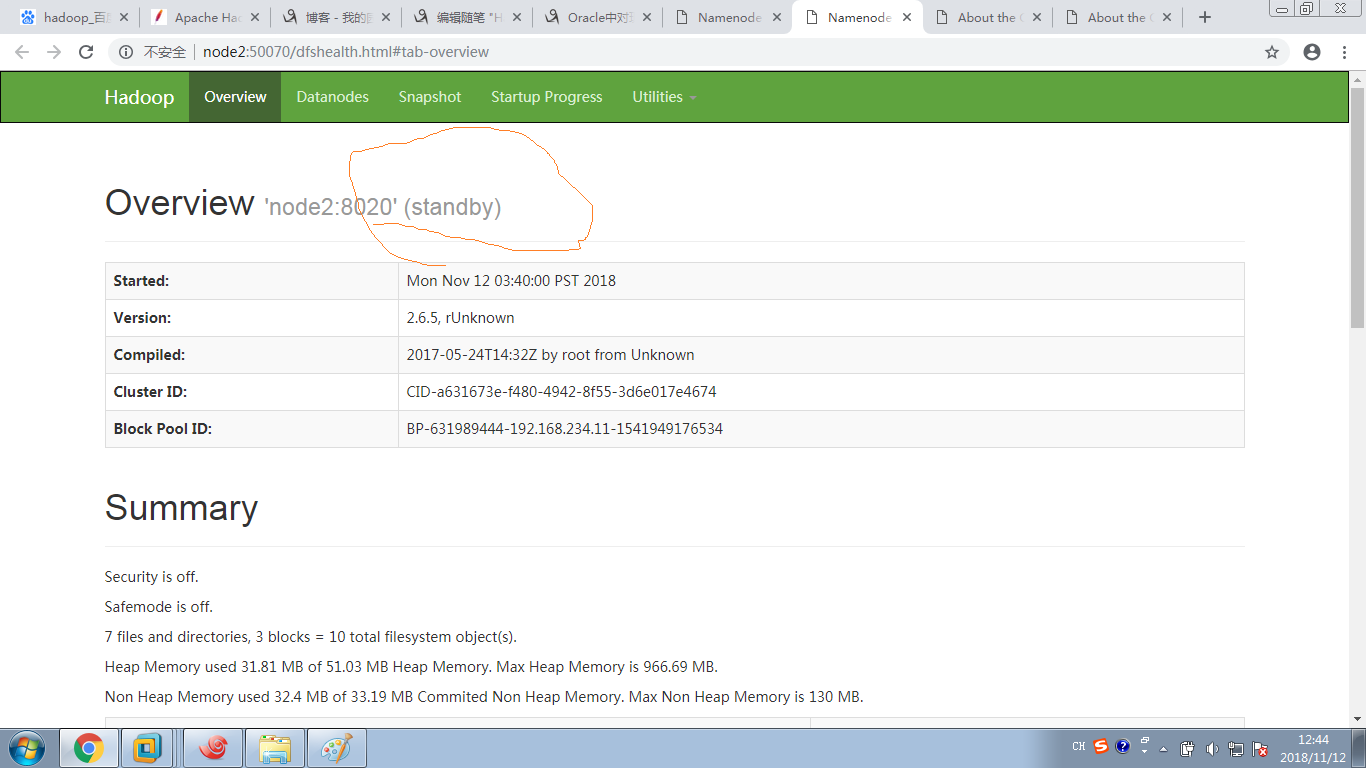
Node2为standby
模拟HA的高可用性(zookeeper实现故障自动转移)
(1)下面模拟active的namenode发生故障 kill -9 ,看看效果
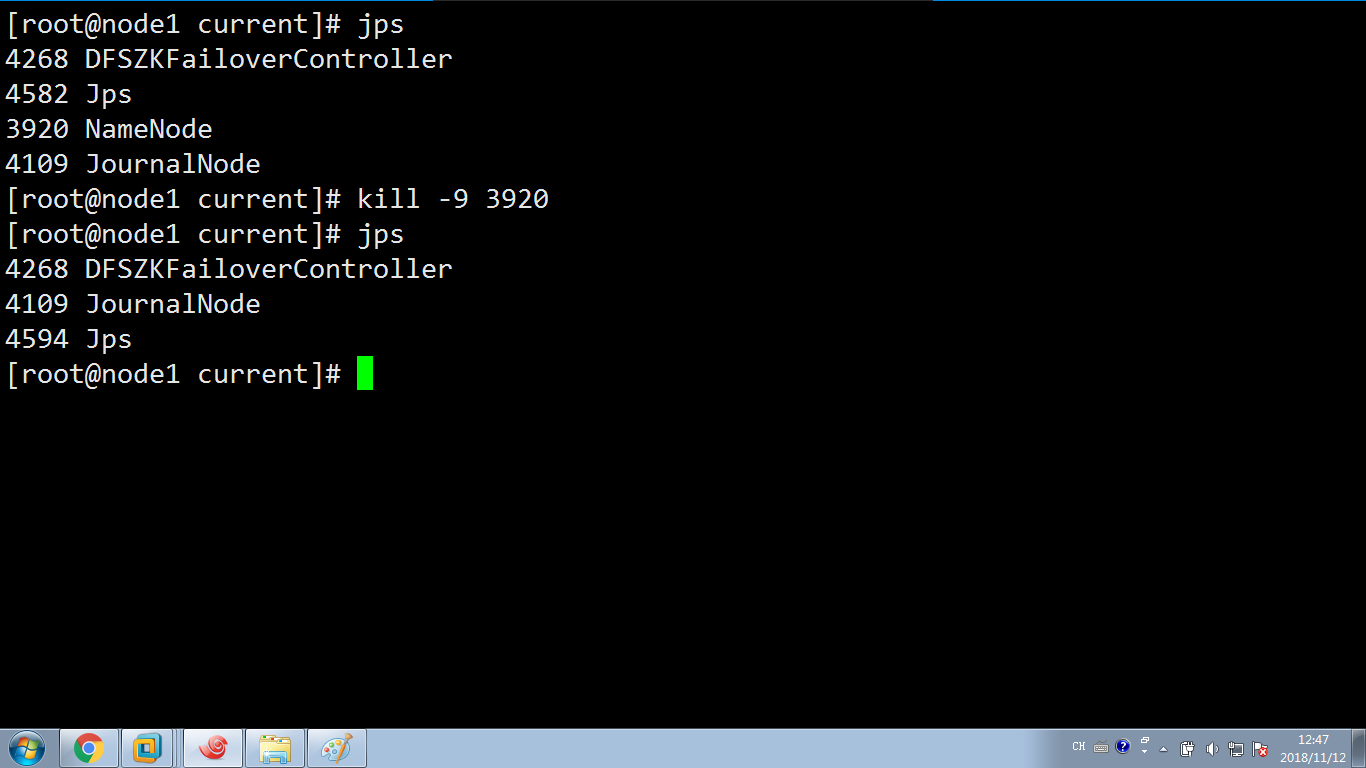
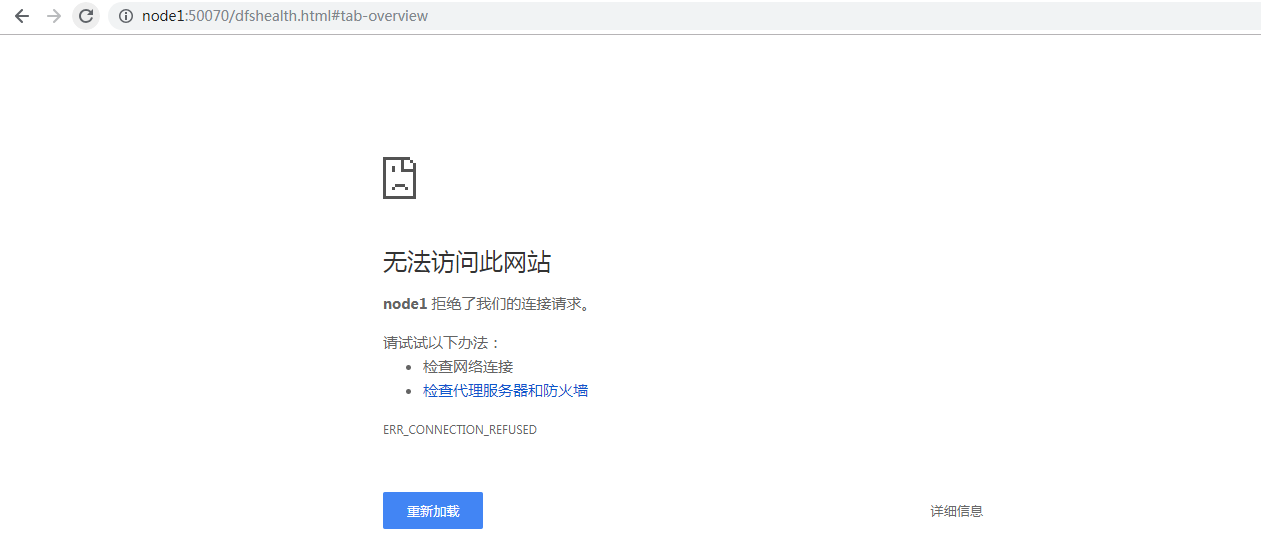
看下页面,好像无法刷新了
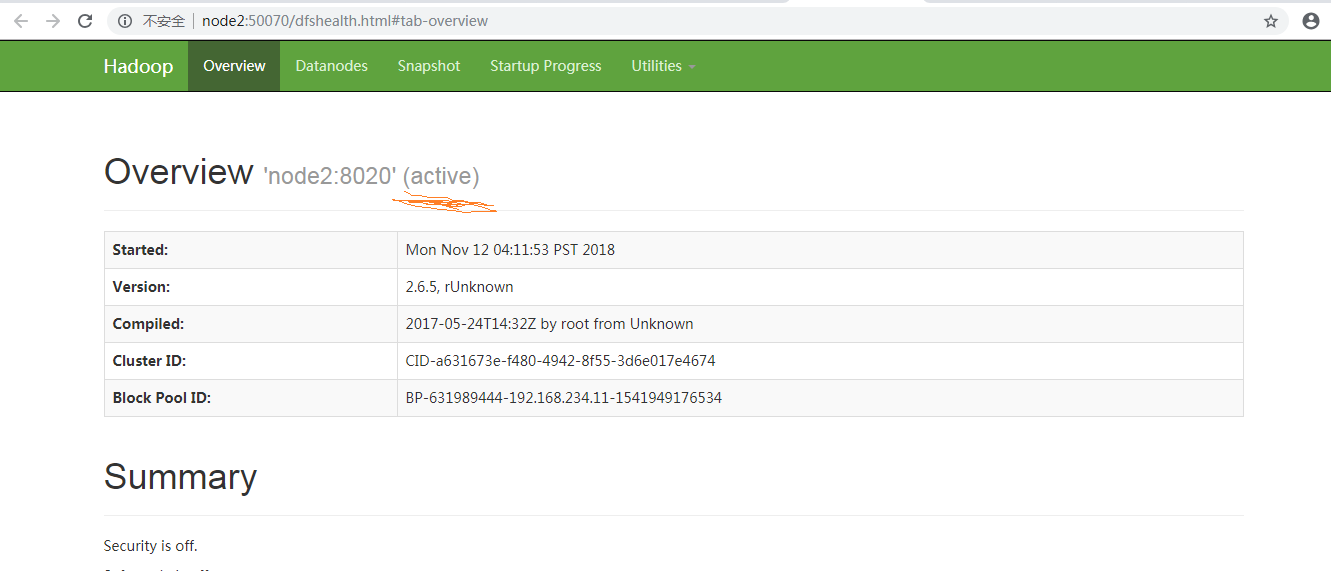
再看下Namenode2,由standby变成了Active
好的,现在再看下zookeeper锁的信息:变成了node2了
现在恢复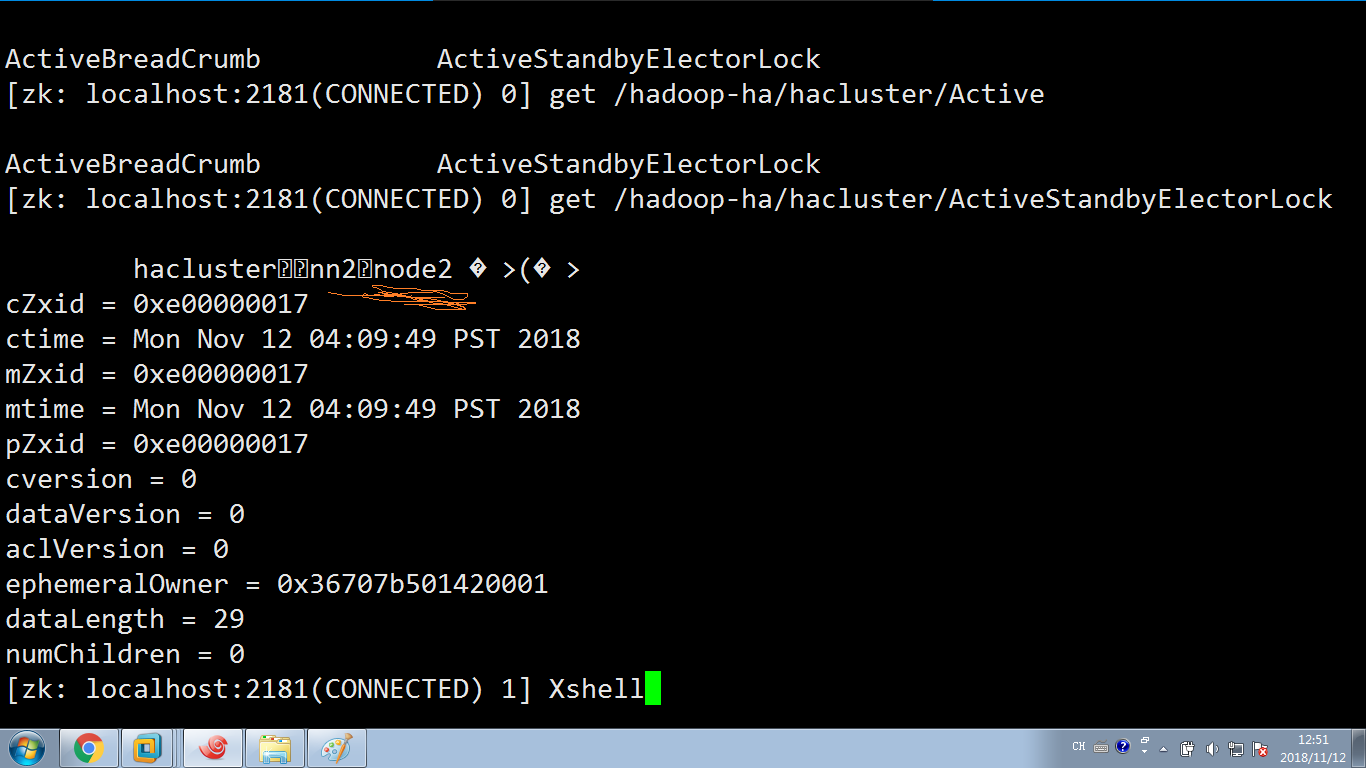 namenode
namenode
现在启动恢复下node1上的namenode的看下node2状态有没有被修改:
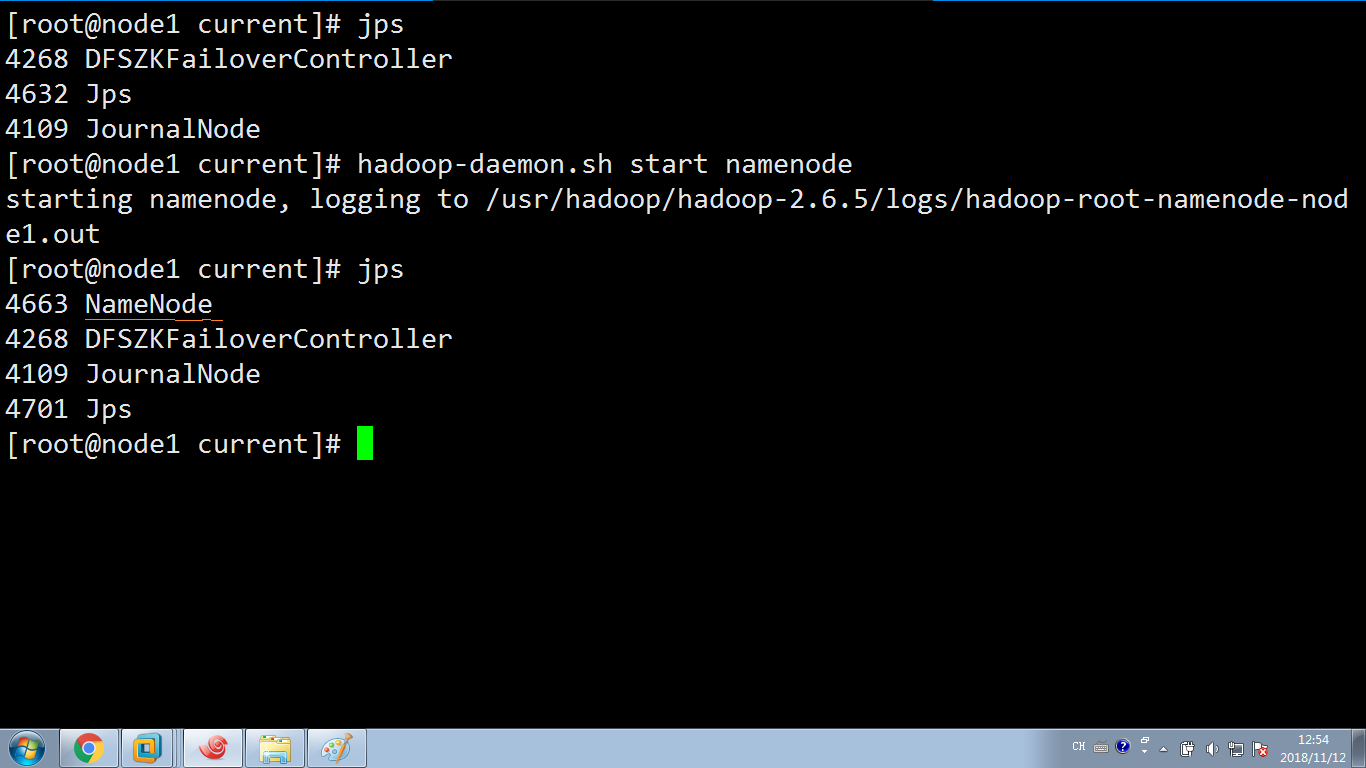
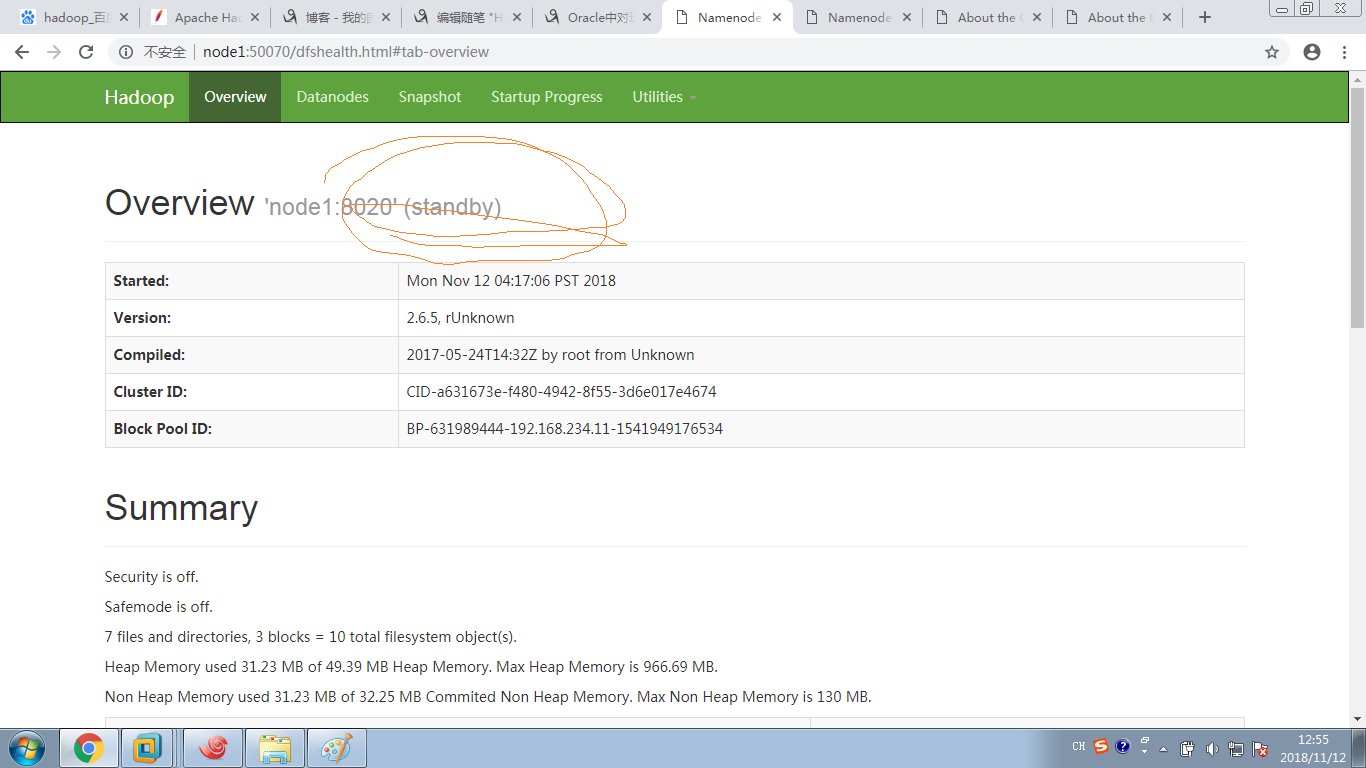
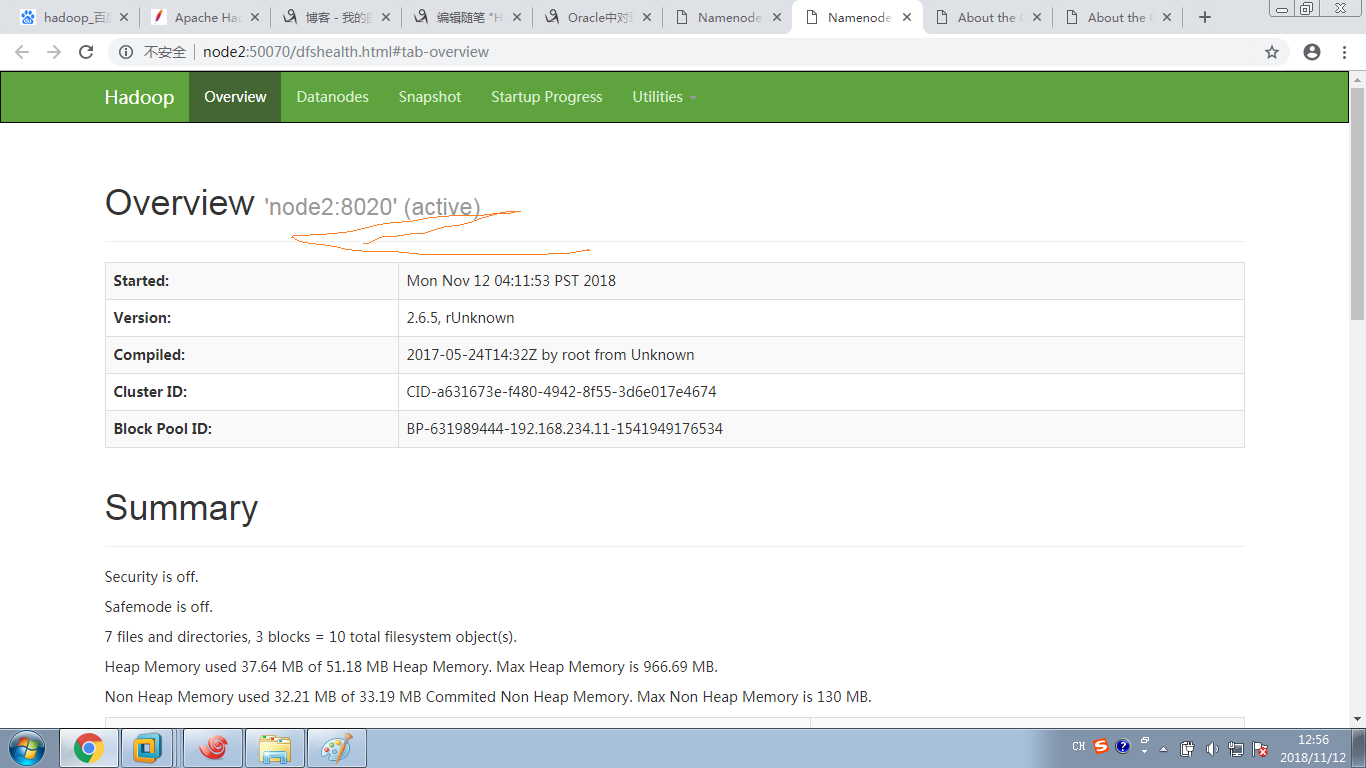 从上面看知道node2还是active ,node1就变成,standby
从上面看知道node2还是active ,node1就变成,standby
(2)现在来模拟zkfc挂了(在node2上模拟kill -9 zkfc的进程):
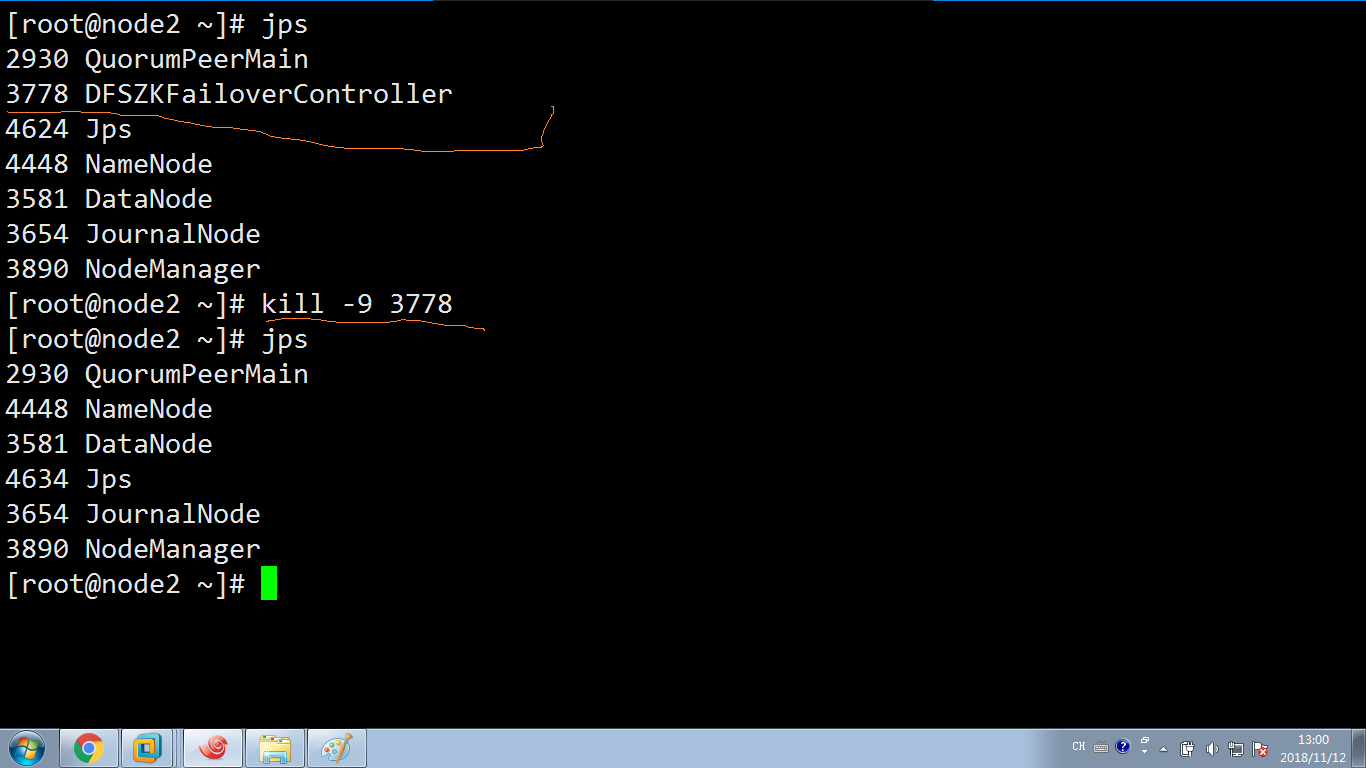
现在看看node2的状态:变成了standby
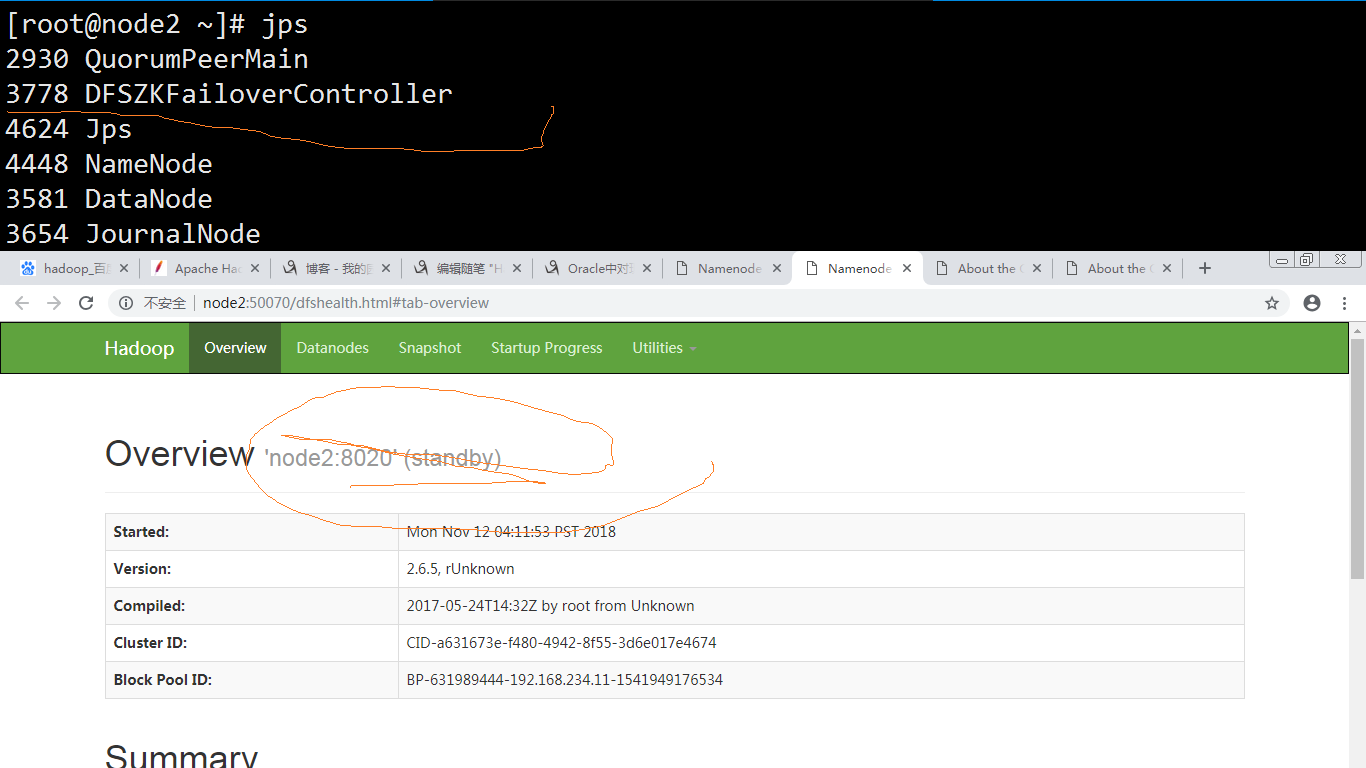
看看node1:变成了active
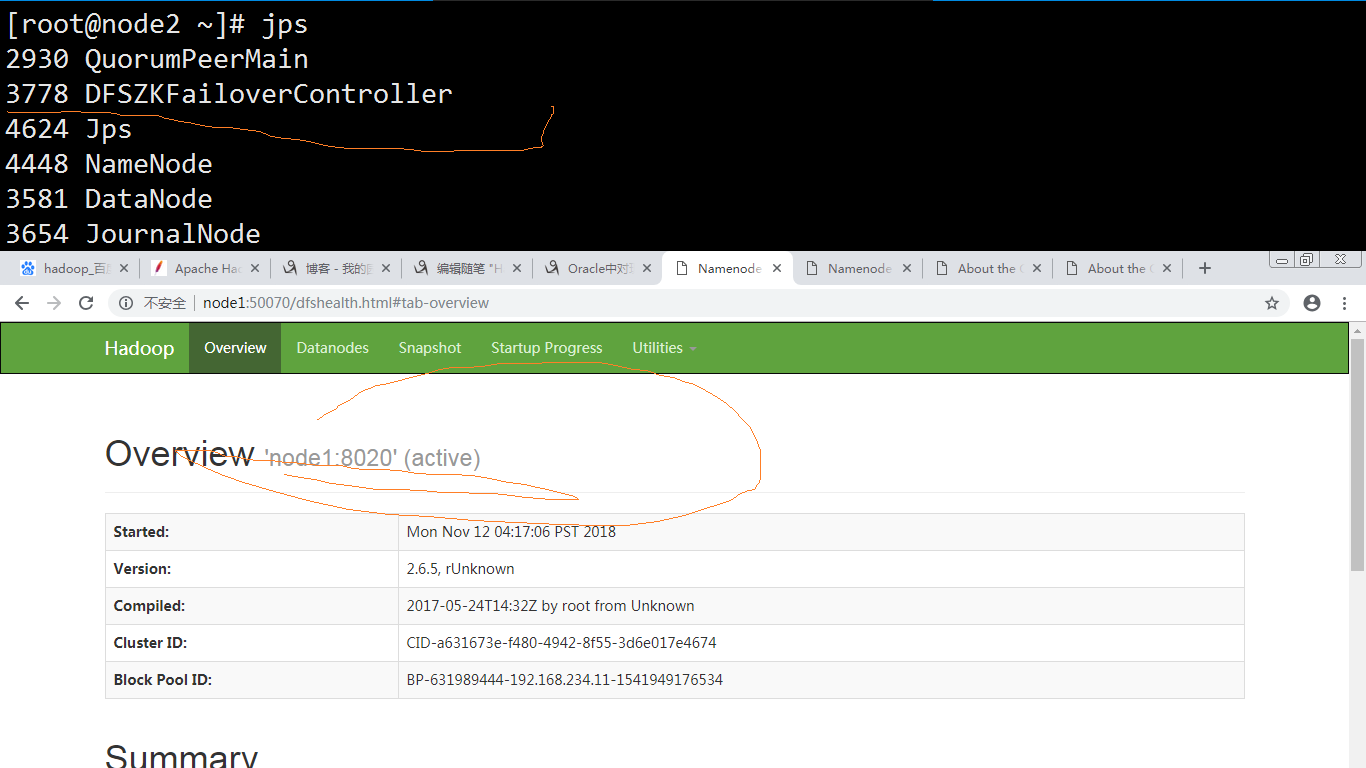
从zookeeper客户端看下是否是现在的锁是node1的:
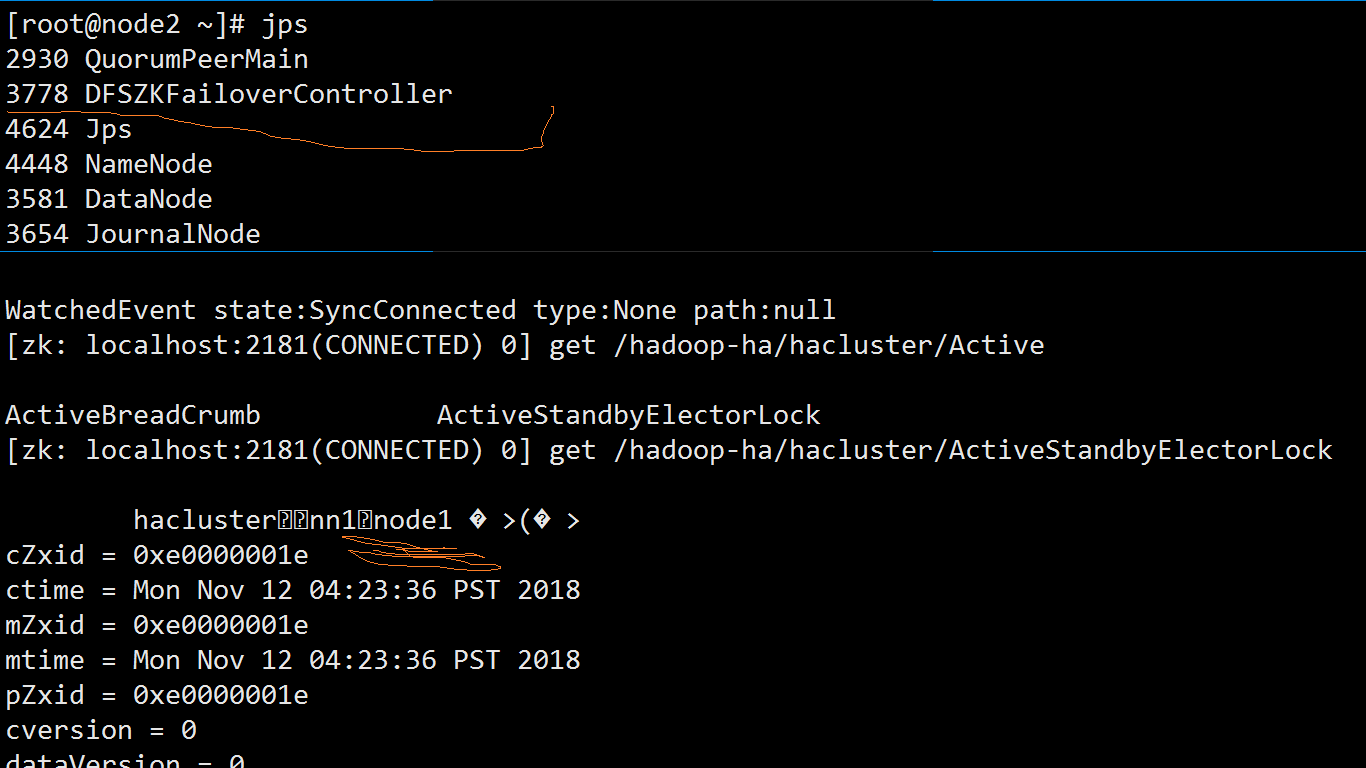
这就是zkfc的自动故障转移功能,利用zookeeper来分布式协调。
搭建zookeeper集群:
(1) /usr/zookeeper/zookeeper-3.4.6/conf : cp zoo_samp.conf zoo.conf
(2) 修改data.dir zookeeper数据文件的目录: dataDir=/usr/zookeeper/tmp/data
(3) 添加3个节点的地址(
server.1=192.168.234.12:2888:3888
server.2=192.168.234.13:2888:3888
server.3=192.168.234.14:2888:3888
)
(4) 手动创建数据文件的目录
(5) Echo 1 >> 数据文件目录/myid 注:然后分发到各个节点,修改myid 如果(zoo.conf文件中)当前节点的ip地址对应server.2 那么myid就修改为2
(6) 修改各个节点的profile文件,要保持一致
(7) . /etc/profile (使得修改后的profile文件生效)
(8) 启动zookeeper zkService.sh start (只要超过一半的zookeeper就可以认为zookeeper启动,否则认为未启动,可以启动一个zookeeper时查看状态)
下面附上配置文件内容:
zookeeper配置文件: /usr/zookeeper/zookeeper-3.4.6/confzoo.cfg文件的最低端加上如下的内容
server.1=192.168.234.12:2888:3888
server.2=192.168.234.13:2888:3888
server.3=192.168.234.14:2888:3888
hdts-site.xml
<configuration>
<!-- namenode HA集群的别名 -->
<property>
<name>dfs.nameservices</name>
<value>hacluster</value>
</property>
<!-- HA集群下的两个namenode的别名nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.hacluster</name>
<value>nn1,nn2</value>
</property>
<!-- namenode1监听的地址 -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn1</name>
<value>node1:8020</value>
</property>
<!-- namenode2监听的地址 -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn2</name>
<value>node2:8020</value>
</property>
<!-- namenode1客户端访问的物理地址以及端口 -->
<property>
<name>dfs.namenode.http-address.hacluster.nn1</name>
<value>node1:50070</value>
</property>
<!-- namenode2客户端访问的物理地址以及端口 -->
<property>
<name>dfs.namenode.http-address.hacluster.nn2</name>
<value>node2:50070</value>
</property>
<!-- journalNode的地址和端口:jnncluster 别名可以随便取 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/hacluster</value>
</property>
<!-- journalNode 存放edit.log文件的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/journal/node/local/data</value>
</property>
<!-- namenode故障监测 -->
<property>
<name>dfs.client.failover.proxy.provider.hacluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- zkfc进程进行回调需要免秘钥 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- zkfc进程进行回调需要免秘钥,私钥路径 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启zookeeper的自动故障转移功能 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- the secondary namenode address -->
<!-- <property> -->
<!-- <name>dfs.namenode.secondary.http-address</name> -->
<!-- <value>node2:9001</value> -->
<!-- </property> -->
<!-- the directory of namenode data -->
<property>
<name>dfs.namenode.name.dir</name>
<value>${hadoop.tmp.dir}/name</value>
</property>
<!-- the directory of datanode data -->
<property>
<name>dfs.datanode.data.dir</name>
<value>${hadoop.tmp.dir}/data</value>
</property>
<!-- the number of replication of datanode data -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
core-site.xml文件里面的内容:
<configuration>
<!-- namenode address-->
<!-- <property> -->
<!-- <name>fs.defaultFS</name> -->
<!-- <value>hdfs://node1:9000</value> -->
<!-- </property> -->
<!-- namenode集群入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hacluster</value>
</property>
<!-- zookeeper集群信息 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<!-- the hadoop temporary directory -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
<!-- upload file IO cache size -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
转载于:https://www.cnblogs.com/yehuili/p/9942453.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号