
一般线上遇到比较头疼的就是OOM内存溢出问题,我们都会先看错误日志,如果错误日志能够定位出哪个类对象导致内存溢出,那么我们只需要针对问题修改bug就好。但是很多时候我们单凭日志无法定位出内存溢出问题,那么我们这时候就需要以下操作来定位问题。
1、top下对当前服务器内存有个大致了解
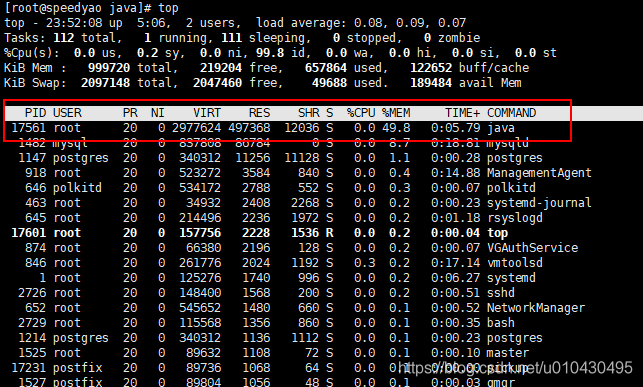
top后 shift+M俺内存占用由大到小排序,RES是此进程实际占用内存,%MEM是占服务器总内存的49.8。
2、利用ps命令查看服务pid
[root@speedyao java]# ps -aux|grep java3、利用jstat查看虚拟机gc情况
jstat -gc:util <vmid> [<interval> [<count>]
vmid:虚拟机进程号
interval:采样时间,默认单位是ms
count:采样条数
[root@speedyao java]# jstat -gcutil 17561 1000 10以上命令代表1秒钟采样1次,总共采样10次。

FULL GC明显大于YOUNG GC次数,并且FULL GC次数很频繁,说明程序有大内存对象,并且一直无法释放。
4、生成dump文件,有两种方式。 一种是利用jmap直接生成dump文件;另一种是利用gcore先生成core文件,再根据core文件利用jmap生成dump文件。
(1)先说第一种,这种比较简单,使用这种方案的时候请注意:JVM会将整个heap的信息dump写入到一个文件,heap如果比较大的话,就会导致这个过程比较耗时,并且执行的过程中为了保证dump的信息是可靠的,所以会暂停应用。
[root@speedyao java]# jmap -dump:format=b,file=heap.prof 17561
format=b:表示生成二进制类型的dump文件
file=:后面写的是输出的dump文件路径
17561:jvm进程id
(2)接下来是第二种。这一种在jmap转换core文件的时候比较耗时,并且生成的dump文件用mat打开的时候分析结果不太正确,不太好定位问题。所以我建议使用第一种,虽然会造成服务挂起吧,但是结果总归是正确的。
利用gcore保存服务的内存信息,因为gcore比jmap的dump会快很多,也不对线上服务有大的影响
[root@speedyao java]# gdb -q --pid=17561
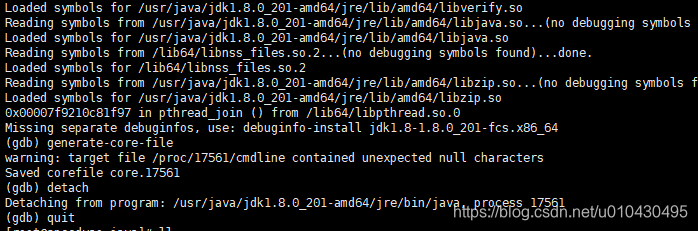
generate-core-file:生成内存对象,生成的文件存储在当前位置,文件格式pid.core
detach:断开与进程的连接
quit:退出
利用jmap将gcore文件转换为java的dump文件,这一步执行的比较慢,可以用nohup执行,以防止误点Ctrl+C导致退出。
[root@speedyao java]# jmap -dump:format=b,file=heap.prof /usr/bin/java core.17561
format=b:表示生成二进制类型的dump文件
file=:后面写的是输出的dump文件路径
/usr/bin/java:java命令路径,可以通过命令which java 获取这个路径
core.17561:表示core文件路径
6、利用MAT(eclipse开发的可以下载eclipse插件,idea开发的可以下载单独的MAT压缩包)分析dump文件。当然也可以用jdk自带的jvisualvm.exe来分析dump文件
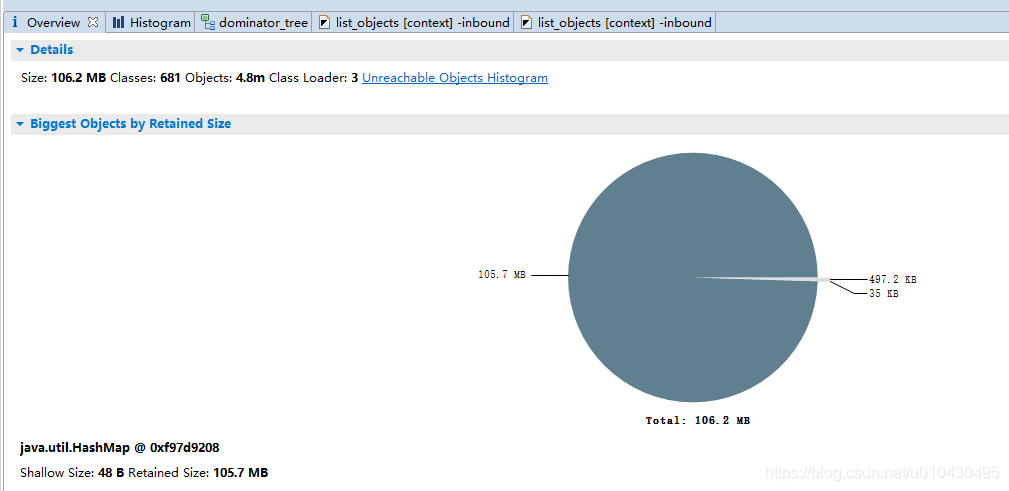
上图是概要,阴影部分就是大内存对象类,点击选择 “list Object”、“with incoming references”,就出现下图。下图就是这个对象的信息,RunMian 就是map对象所在的类,这样就能快速定位出哪个类中的哪个对象出现了内存异常。
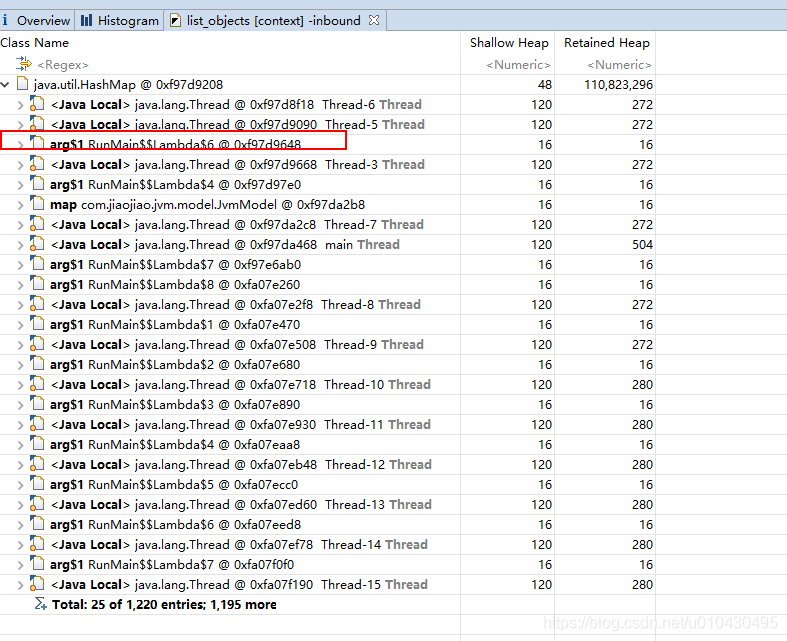
下图Histogram这个tab是堆内存占比从大到小排序。
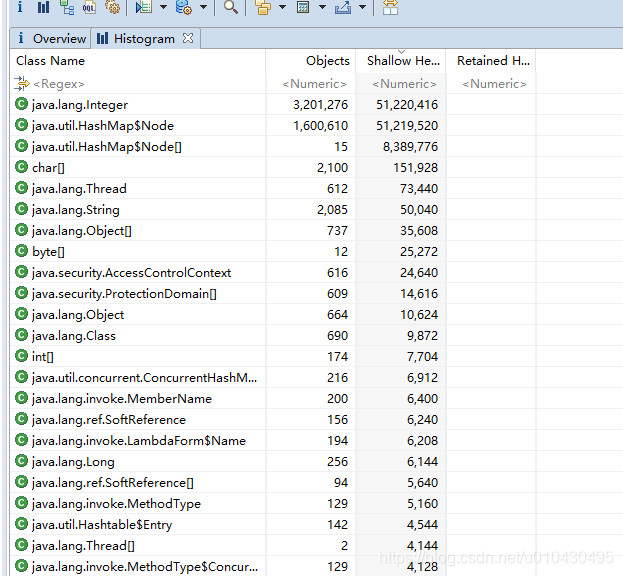
以上就是内存问题排查的大致步骤。
转载于:https://blog.csdn.net/u010430495/article/details/87283064?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.control

 浙公网安备 33010602011771号
浙公网安备 33010602011771号