


以下文章来源于四猿外 ,作者四猿外

前言
当架构师大刘看到实习生小李提交的记账流水乱序的问题的时候,他知道没错了:这一次,大刘又要用一致性哈希这个老伙计来解决这个问题了。
嗯,一致性哈希,分布式架构师必备良药,让我们一起来尝尝它。
1. 满眼都是自己二十年前的样子,让我们从哈希开始
在 N 年前,互联网的分布式架构方兴未艾。大刘所在的公司由于业务需要,引入了一套由 IBM 团队设计的业务架构。
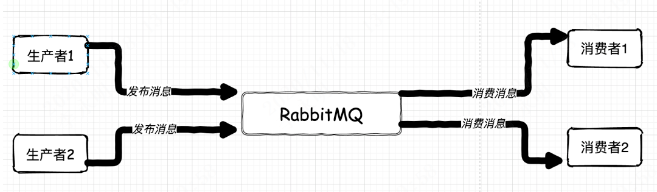
这套架构采用了分布式的思想,通过 RabbitMQ 的消息中间件来通信。这套架构,在当时的年代里,算是思想超前,技术少见的黑科技架构了。
但是,由于当年分布式技术落地并不广泛,有很多尚不成熟的地方。所以,这套架构在经年日久的使用中,一些问题逐渐突出。其中,最典型的问题有两个:
- RabbitMQ 是个单点,它一坏掉,整个系统就会全部瘫痪。
- 收、发消息的业务系统也是单点。任何一点出现问题,对应队列的消息要么无从消费,要么海量消息堆积。
无论哪种问题,最终是整套分布式系统都无法使用,后续处理非常麻烦。
对于 RabbitMQ 的单点问题,由于当时 RabbitMQ 的集群功能非常弱,普通模式有 queue 本身的单点问题,所以,最终使用了 Keepalived 配合了两台无关系的 RabbitMQ 搞出了高可用。
而对于业务系统单点问题,从一开始着手解决的时候就出现了波折。一般来说,我们要解决单点问题,方法就是堆机器,堆应用。收发是单点,我们直接多部署几个应用就可以了。如果仅仅从技术上看,无非就是多个收发消息的应用大家一起竞争往 MQ 中放消息拿消息而已。
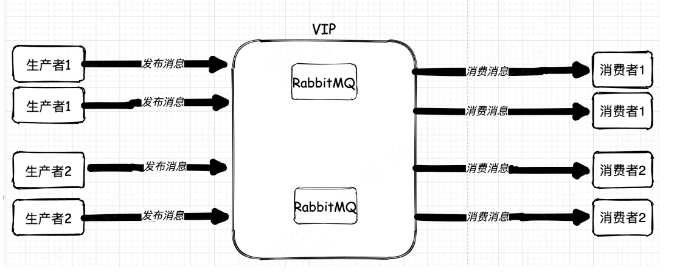
但是,恰恰就是在把收发消息的应用集群化后,系统出现了问题。
本身这套系统架构会被应用到公司的多类业务上,有些业务对消息的顺序有着苛刻的要求。
比如,公司内部的 IM 应用,不管是点对点的聊天还是群聊消息,都需要对话消息严格有序。而当我们把生产消息和消费消息的应用集群化后,问题出现了:
聊天记录出现了乱序
A 和 B 对话,会出现某些消息没有严格按照 A 发出的先后顺序被 B 接收,于是整个聊天顺序乱成了一锅粥。
经过排查,发现问题的根源就在于应用集群上。由于没有对应用集群收发消息做特殊的处理,当 A 发出一条聊天信息给B时,发送到 RabbitMQ 中的信息会被在 B 处的消费端所争抢。如果 A 在短时间内发出了几条信息,那么就可能会被集群中的不同应用抢走。
这时候,乱序的问题就出现了。虽然应用业务逻辑是相同的,但是这些集群中的应用依然可能在处理信息速度上出现差异,最终导致用户看到的聊天信息错乱。
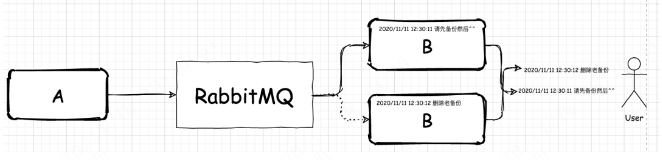
问题找到了,解决办法是什么?
上面我们说过了,消息顺序错乱是因为集群中不同应用抢消息然后处理速度不一样导致的。如果我们能保证 A 和 B 会话,从开始之后到会话结束之前,永远只会被 B 所在的消费消息集群应用中的同一个应用消费,那么我们就能保证消息有序。这样一来,我们就可以在消费消息的那个应用中,对抢到的消息进行排队,然后依次处理。
那么,这种保证怎么实现呢?
首先,我们在 RabbitMQ 中会建立有相同前缀的队列,后面跟着队列编号。然后,集群中的不同应用会分别监听这两个有着不同编号的队列。当在 A 发送信息时,我们会对信息做一次简单的哈希:
m = hash(id) mod n
这里,id 是用户的标识。n 是集群中 B 所在业务系统部署的数量。最终的 m 是我们需要发送到的目的队列编号。
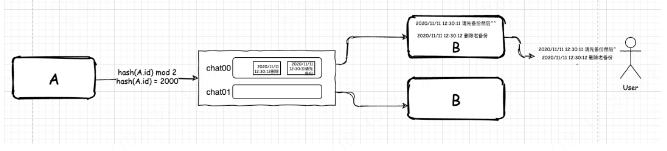
假设,hash(id) 的结果为 2000,n 为 2,经过计算 m = 0。此时,A 就会把他和 B 的对话信息都发送到 chat00 的队列里。B 收到消息后,就会依次显示给终端用户。这样,聊天乱序的问题就解决了。
那么,事情到此就结束了吗?这个解决方案是完美的吗?
2. 看来,我们需要增加应用数量了
随着公司的发展,公司的人数也急剧上升,公司内部的 IM 使用人数也跟着多了起来,新问题又随之出现了。
最主要的问题是,人们收到聊天信息的速度变慢了。原因也很简单,收取聊天信息的集群机器不够用了。解决办法可以简单直接点,再加台机器就好了。
不过,由于收消息的集群中新加入了一台机器,这时候,我们还需要额外多做一些事情:
-
我们需要为新加入的这台机器上的应用额外再多增加一个队列 chat02。

-
我们还需要修改下我们的分配消息的规则,把原来的 hash(id) mod 2 修改为 hash(id) mod 3。

-
重新启动发送消息的项目,以便修改的规则生效。
-
把收消息的应用部署到新机器上。
到这时,一切还都在可控范围。开发人员只需要在需要的时候,新增加个队列,然后把我们的分配规则小小的修改下即可。
但是,他们不知道的是,暴风雨就要来了。
3. 新的问题来了,也许这就是人生吧
由于公司内部很多人在使用这个 IM 工具。有些时候,为了方便,公司的客户还有一些合作方也用起了这个 IM。这让事情变得复杂了起来。起初,开发人员还是像往常一样,每当人们抱怨说收消息过慢的时候,他们就会加一台机器。
最糟糕的是,公司的客户也会抱怨,他们发现 IM 有时候彻底不可用。这可不是小事情。公司内部人员的问题还可以内部沟通解决。但是公司客户的问题,大意不得,因为这关系到公司产品的名誉。
那么,这到底是怎么一回事呢?
原来,根本原因还在于每次修改完配置规则后的重启服务。每次修改完配置规则,就需要规划好一个恰当的停机时间,去重新对项目做个上线。
但是,这种方法在公司的客户也使用这个 IM 后就行不通了。因为公司的客户有不少是在国外的。也就是说,不管白天还是深夜,很可能总是有人在使用这个 IM。
这就迫使开发人员们,在增加机器时,还需要去和多方协调沟通出一个上线时间,然后发布公告,再去上线。这种反复沟通,再上线,再反复沟通,再上线直接把开发人员们折腾了个半死。
往往沟通完,上线时间直接被放到了半个月以后。而在这半个月里,开发人员还要承受无数内部 IM 使用人的口水。费心竭力的沟通,声嘶力竭的解释,缺眠少觉的上线,这一切的一切推动着开发人员们必须对眼前这套技术方案作出改变了。
4. 思路转起来,队列环起来
新的技术方案的需求本质就是:
无论是分配消息规则变化还是集群机器添加都不能停机停服务
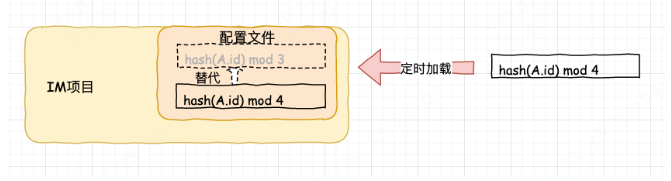
对于这种情况,一个很好的解决方案就是如果我们对项目配置文件进行动态的定时检测,当发现变动时,刷新配置规则即可。
一切看上去很美好,采用了动态的定时检测后,每当我们需要新增集群中的机器时,我们只需要如下三个步骤了:
- 增加一个队列
- 修改分配消息的规则
- 部署新的机器
客户毫无感知,开发人员们也不需要和用户们协调沟通出专门的上线安排。可是,这个方案也存在一些问题:
- 随着我们的系统部署越来越多,我们需要手工修改规则的系统也越来越多。
- 如果消费机器宕机了,我们需要删除队列,同时还需要去删除修改分配消息的规则,等到机器恢复了,我们还要再把分配消息的规则改回去。
这个分配消息的规则真讨厌啊,每次有变动,就要去关心这个分配消息的规则。有没有什么办法能把这个分配变得更自动化一些呢?
如果我们假设在 MQ 中有 100 个收发聊天信息的队列(100:这是对我们的IM不可能达到的一个数字),我们只需要在配置规则中配置成:
m = hash(id) mod 100
然后,我们的发送消息的应用启动后,去动态的探测出真实的所有收发聊天信息的队列信息。
当我们通过哈希算出的编号发现没有真实对应的队列存在时,就根据一定的规则,去找到一个真实存在的队列,这个队列,就是我们要发消息的队列。
如果我们做到这样,那么以后,每次队列有变化,无论增多还是减少,我们都不需要再去考虑分配规则的事情了,只需要移除有问题的队列或者增加有对应消费者的队列即可。
这个思想,就是一致性哈希的思想。
具体怎么做呢?
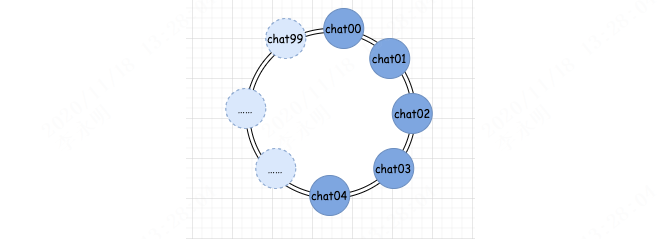
第一步,我们假设有个 100 个收发聊天信息的队列,并且这些队列处于一个环上。

第二步,我们获取到真实的收发聊天信息的队列数量,假设有 5 个。

第三步,我们把真实的队列映射到我们第一步假设的环中。
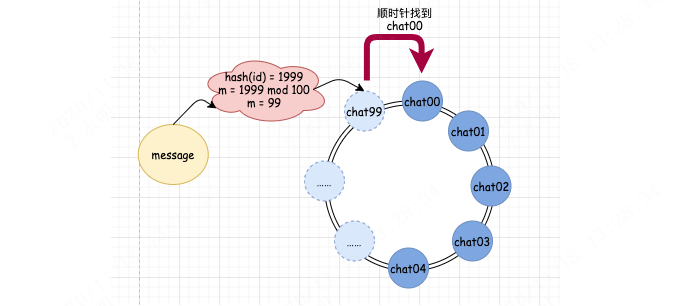
第四步,我们通过分配规则 hash(id) mod 100 计算出对应的队列编号。
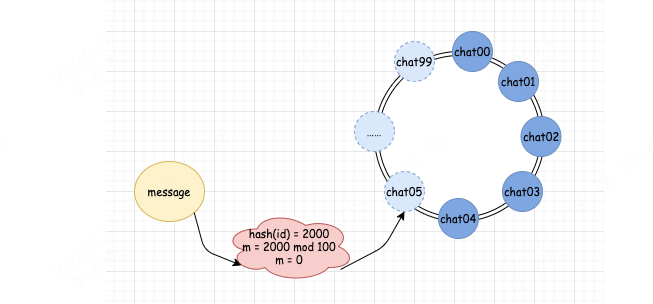
如果 hash(id) 的结果为 2000,那么算出的队列编号 m = 0。这时候,我们一查,发现对应编号 0 的 chat00 队列确实存在,那么就直接发送消息到 chat00 中。

如果我们的 hash(id) 的结果为 1999,那么算出的队列编号 m = 99。此时,我们去查队列映射关系,发现 99 编号并没有对应的真实队列。这时候怎么办?很简单,我们顺时针继续往下找,找到谁了呢?0 对应的 chat00 队列,这是真实存在的,这时候,我们就将消息发送到 chat00 队列中。
上面四步就是一个基本的一致性哈希算法了。
那么,这套一致性哈希算法满足我们不想总是更新消息分配规则的需求吗?让我们验证一下:
-
假设我们需要在消费信息端集群增加一台机器
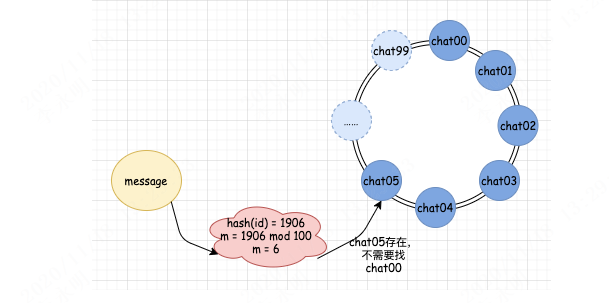
我们如果要增加一台机器,那么同时我们也需要在 MQ 中增加一个队列。这时候,我们的分配规则是 hash(id) mod 100,增加了队列后,真实的队列数假设为 6。此时,如果 hash(id) mod 100 的结果小于 6,那么分配的规则和没有增加机器的时候规则一样,以前分配到哪个队列,现在还是分配到哪个队列。但是对于结果等于 6 的情况,则发生了变化。信息会被自动分配给 chat05。当分配给 chat05 后,新的消费者就会自动开始进入正常工作了,我们不需要做任何人工干预,也不需要考虑分配规则的变化。增加机器以前:
-
增加机器之后:
-
假设消费信息端集群一台机器宕机了
模拟宕机,此时我们会去减少一个队列。减少后的真实队列数量为 5,则正好和增加队列相反,m = 5 时,那么行为不会有任何变化,以前分到哪个队列,还是分到哪个队列。如果 m = 6,由于已经不存在真实的队列了,就会做顺时针查找,结果找到 chat00,以前会分到 chat05 的就会被分到 chat00。而此时,chat00 由于正好有消费者,所以,系统的用户是毫无感知的,我们也专心修复我们机器即可。当机器恢复后,就会和新增机器一样,计算结果为 6 的信息会被重新分配回 chat05。
目前,我们可以看到,当我们引入一致性哈希后,我们不管新增机器还是集群机器宕机,我只需要跟随着机器的状态,做一个操作即可:增加或者减少 MQ 中的队列。一切简单化了。
那么,这个方案是否依然还有问题呢?
5. 失衡的圆环,压垮骆驼的可能只是一根稻草
假设我们目前有 5 个队列存在,我们的分配规则是 m = hash(id) mod 100。那么,此时,问题就出来了。
如果 m 的值大于 5,由于没有对应的真实队列存在,系统就会顺时针顺着我们构造出来的哈希环找,最终会找到 chat00 这个队列上。
然后,你会发现,只要是 m 值大于 5 的 id 对应用户发的信息,最终都会落入到 chat00 队列中。

在极端情况下,如果大量的信息涌入到 chat00 队列里,由于对应 chat00 的消费者处理不过来,很可能会导致这个消费者的崩溃。
然后,去除队列后,根据规则,又会有大量的信息涌入到 chat00 后续的队列 chat01 里,这些信息又会导致 chat01 对应应用的崩溃,最终引发整个集群的崩溃,这就是雪崩效应。
我们需要一种更巧妙的办法来解决这个问题。
6. 从实变虚,也许我们应该更敢想一些
经过上面的论述,我们发现,我们在分配队列时,之所以失衡,是因为我们的队列在圆环上的分配失衡。
我们所有的真实队列都是按照顺时针依次排布在圆环上的。在上面的场景里,我们只有 5 个队列。此时,我们假设会有 100 个队列。那么,m = hash(id) mod 100 这个公式里:
m 大于 5 的概率为 95%
由于我们的 5 个队列是按照编号顺序依次排列的。那就说明所有 m 大于 5 的信息就都会映射到一个不存在的队列上,最终,根据规则,顺时针滑到了 0 对应的 chat00 队列中。
如果,我们可以让真实存在的队列均匀分布到环上,那么,这种严重失衡的现象还会再出现吗?
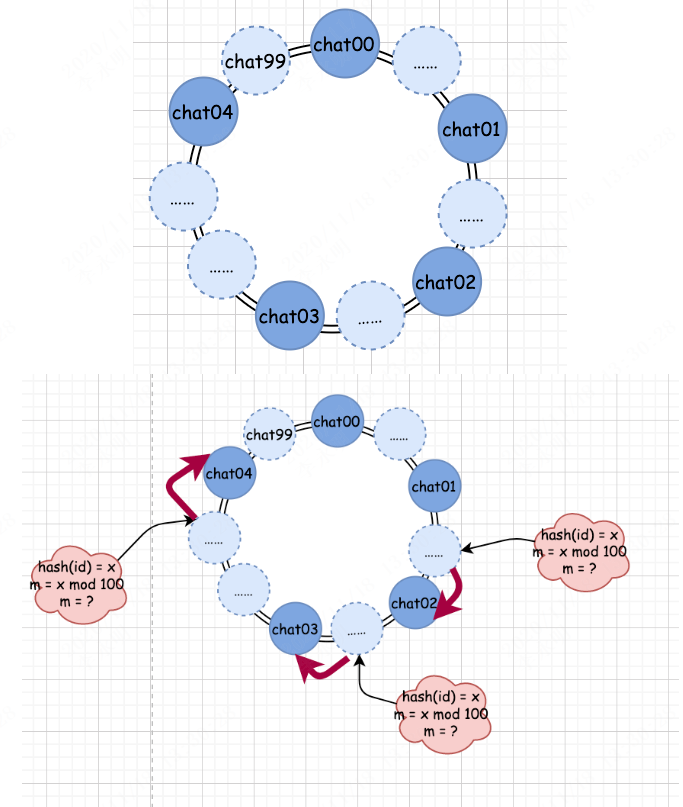
从上面的图我们可以看出,如果我们能让真实的队列均匀的在圆环上分布,那么这种严重失衡的现象就会得到极大的缓解。
那么如何让这些队列能均匀的分布在这个圆环中呢?还记得我们在苦恼分配信息规则的不断修改时,我们大胆的假设了一个我们的 IM 系统永远也不可能达到的队列数字吗?
我们假设了 MQ 中有 100 个队列,然后,我们去判断这些队列是否真实存在。不存在,我们就顺时针滑动一直找到真实存在的队列为止。
如果我们再大胆一点,偷偷的把我们的假设进一步优化,把一些本来需要判断为不存在的队列去映射到真正已经存在的队列上,那么我们是不是就等于把这些真正存在的队列均匀分布到这个圆环上了?
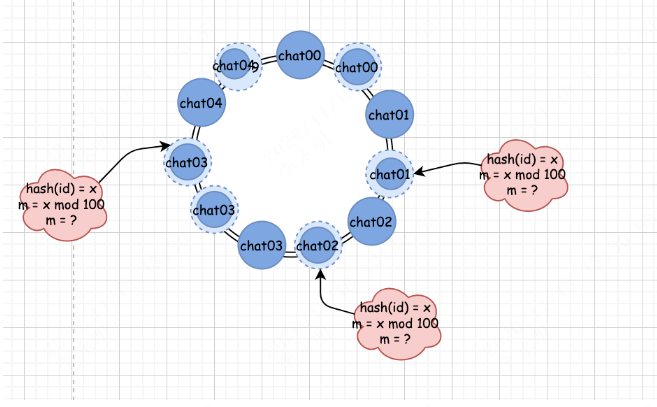
像上图这种,把已经存在的少量队列去映射到多个假设队列的方法,就是一致性哈希的虚拟节点办法。
而对于怎么让少量的队列映射到多个假设队列,是有多种实现算法存在的。
比如,我们可以把真实存在的队列名加上一些编号去分别哈希一下, 像hash(chat00) mod 100,hash(chat00#1) mod 100,然后根据得到的余数,去把 chat00 这个真实队列和对应余数的环中的位置映射上。
如果 hash(chat00) mod 100 = 31,那么 31 号的位置就对应于 chat00,以后所有 m = hash(id) mod 100 中 m = 31的所对应的消息就会直接被发送到 chat00 队列。
而 hash(00#1) mod 100 = 56,则 m = 56对应的消息同样也会直接发送到 chat00 队列。
这样,我们就间接的把 MQ 中的真实存在的队列做了均匀化分布,从而大大减少了信息失衡的现象。
7. 理解算法的思想胜于算法的实现
好了,通过实际场景来对于一致性哈希的思想就暂时剖析到这里了。
一致性哈希作为一种非常经典的算法思想,被广泛的用于各大分布式项目当中,用于解决各种分片问题,任务分发问题。
但是,在这里,我要纠正一个观点:很多人都在网上说 redis 使用了一致性哈希。这是错的,redis 只是使用了一致性哈希的思想。比如一致性哈希中的环分布,再比如虚拟节点对应真实节点的思想。
但是 redis 并没有使用任何哈希算法去计算分布,如果有兴趣的读者,可以仔细去看下有关内容。从 redis 的例子上来说,我们可以看到,只有理解了算法的思想,我们才能更容易更灵活地因地制宜的分解、修正、改进算法,让算法能更切合实际的融入到我们的项目之中。
通过这篇文章我们从哈希开始,一直到用到一致性哈希的虚拟节点分布,怎么样,您觉得一致性哈希这道良药味道如何呢?
第一次写图解的文章,大家包容一下直男的审美!
第一次写图解的文章,画图真是累吐血了!求大家看完点个在看。


