
java 四舍五入new BigDecimal(double)及BigDecimal valueOf(double)的区别
最近在研究java的四舍五入,其中有一个方法如下
new BigDecimal(val).setScale(newScale, BigDecimal.ROUND_HALF_DOWN));
其中val是要处理的浮点数
newScale表示要保留小数点后几位
BigDecimal.ROUND_HALF_DOWN表示若舍弃的部分>0.5则进位,否则直接舍弃,说白了就是五舍六入
比如说1.234,保留两位小数处理结果为1.23
比如说1.235,保留两位小数处理结果为1.23
比如说1.236,保留两位小数处理结果为1.24
为了验证我的猜测,马上写几行代码验证下
System.out.println(new BigDecimal(1.234).setScale(2, BigDecimal.ROUND_HALF_DOWN)); System.out.println(new BigDecimal(1.235).setScale(2, BigDecimal.ROUND_HALF_DOWN)); System.out.println(new BigDecimal(1.236).setScale(2, BigDecimal.ROUND_HALF_DOWN));
发现第二条结果与我的猜测不一致,感觉有点受伤
1.23 1.24 1.24
1.235小数点后三位为5,明明是要舍弃的,为何进位了,难道网上的教程都是骗人
折腾了好久,最后发现原来我的写法跟网上别人的还是有细微差别
我的是:new BigDecimal(1.235).setScale(2, BigDecimal.ROUND_HALF_DOWN)
别人家的是:new BigDecimal("1.235").setScale(2, BigDecimal.ROUND_HALF_DOWN),这样的写法结果确实是1.23
可是为何同样的数值,传double类型不行,传String就可以?难道这两种方法初始化的BigDecimal大小不一样?打印出来发现确实不一样
// 打印结果为1.2350000000000000976996261670137755572795867919921875 System.out.println(new BigDecimal(1.235).toString()); // 打印结果为1.235 System.out.println(new BigDecimal("1.235").toString());
new BigDecimal(1.235)的真实值为1.2350000000000000976996261670137755572795867919921875这一长串数字,舍弃的部分是大于0.5的,所以才进位的。
所以为了避免得到错误的结果还是建议传String类型的值,如果是double类型就用如下方法先转成String再处理
new BigDecimal(String.valueOf(1.235)).setScale(2, BigDecimal.ROUND_HALF_DOWN); new BigDecimal(Double.toString(1.235)).setScale(2, BigDecimal.ROUND_HALF_DOWN);
还有另一种方法是直接传double类型的
BigDecimal.valueOf(1.235).setScale(2, BigDecimal.ROUND_HALF_DOWN);
查看BigDecimal.valueOf源码,其内部实现其实也是先转成String
/** * Translates a {@code double} into a {@code BigDecimal}, using * the {@code double}'s canonical string representation provided * by the {@link Double#toString(double)} method. * * <p><b>Note:</b> This is generally the preferred way to convert * a {@code double} (or {@code float}) into a * {@code BigDecimal}, as the value returned is equal to that * resulting from constructing a {@code BigDecimal} from the * result of using {@link Double#toString(double)}. * * @param val {@code double} to convert to a {@code BigDecimal}. * @return a {@code BigDecimal} whose value is equal to or approximately * equal to the value of {@code val}. * @throws NumberFormatException if {@code val} is infinite or NaN. * @since 1.5 */ public static BigDecimal valueOf(double val) { // Reminder: a zero double returns '0.0', so we cannot fastpath // to use the constant ZERO. This might be important enough to // justify a factory approach, a cache, or a few private // constants, later. return new BigDecimal(Double.toString(val)); }
总结
用BigDecimal处理浮点数时BigDecimal的初始化最好采用如下方法
double d = 1.235; BigDecimal bd = BigDecimal.valueOf(d);
简单理解BigDecimal.valueof(Double t)与BigDecimal.valueof(String t)的区别
我也是简单的了解一下
先用简单的代码展示一下
Java代码:
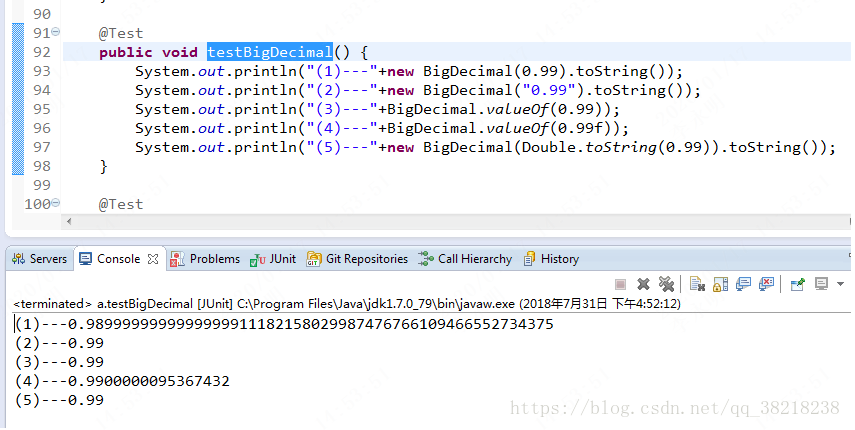
上面的代码主要的区别在于
初始化BigDecimal时形参是double、String和float的区别
从上面可以看到,当double 和 float 时,实际保存的值并不是是准确的0.99,这是为什么呢
大致的原因是:
BigDecimal(double val)将会把double型二进制浮点型值精确的转换成十进制的BigDecimal。
你可能认为java中用new BigDecimal(0.1)创建的BigDecimal应该等于0.1(一个是1的无精度的值,一个是有精度的值),但实际上精确的是等于0.1000000000000000055511151231257827021181583404541015625。这是因为0.1不能被double精确的表示(下面大概描述一下原理)。因此,传入构造函数的值不是精确的等于0.1。
对与float也是同样的道理。首先此函数会自动进行精度扩展,将float类型的0.99转成double类型的,因为0.99本身就是无法用二进制表示的,也就说无论你的精度是多少位,都无法用二进制来精确表示0.99,或者你用二乘来判断(0.99*2=1.98 0.98*2=1.960.96*2=1.92 。。。永远无法得到一个整数)。这就是二进制计算机的缺点,就如同十进制也也无法表示1/3,1/6一样。
所以在0.99f转成double时,进行了精度扩展,变成了0.9900000095367432,而接着转成字符串,最后转成BigDecimal.
总结:
所以在当遇到需要涉及到精确计算的时候,如上面代码所示,要注意该构造函数是一个精确的转换,它无法得到与先调用Double.toString(double)方法将double转换成String,再使用BigDecimal(String)构造函数一样的结果。如果要达到这种结果,应该使用new BigDecimal(Stringvalue) 或 BigDecimal.valueof( double value)
原文地址:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号