1.nifi集群主节点的产生。
nifi集群都会选举某个节点成为主节点,主节点的作用在于单独运行某个处理器,主要是数据获取处理器,防止数据重复消费。主节点由zookeeper选举产生,无法人工修改,使用负载均衡将主节点获取的数据分发到其他节点上。主节点获取数据时主要是获取远端的数据,而非本地的数据,当主节点产生变动时不影响数据的获取。
2.nifi集群COORDINATOR角色产生。
nifi集群会使用zookeeper通过投票选举产生coordinator,coordinator是集群的协调器,负责接收集群其他节点的心跳,监测集群状态,进行数据分发。协调器产生是通过投票产生的,集群最少3个节点组成,依据启动顺序的先后和节点id的大小决定投票结果,如节点id为1、2、3,依次启动节点,则id为3的节点会获得半数以上的投票,称为协调器。协调器无法人工选择。
3.nifi集群如何实现数据负载分发。
四种方式实现,一种是通过DistributeLoad处理器实现负载均衡,一种是通过处理器自身实现数据负载,如getkafka使用相同的ID实现数据的获取。
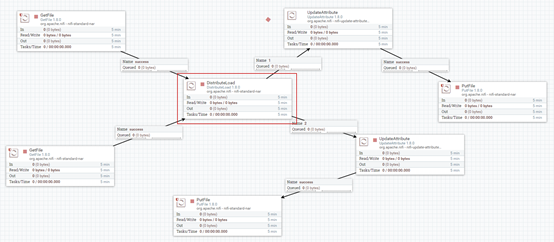
Nifi集群主要通过processor->rpg->input port->processor的方式实现。在集群节点添加inputport,然后将获取数据处理器获取的数据通过remote progress group传到inputport上,rpg需要填写协调器所在节点的ip。所有的数据获取处理器可以通过一个rpg将数据发送到不同的inputport上,当协调器节点发生变化时,需要重新配置rpg的地址。
Nifi1.8提供了最新的数据负载均衡的方法,在connection连接上即可直接配置负载均衡,可选策略有按照属性,均分和单节点分发三种。这种数据负载均衡的方法是最佳的。
4.nifi单机版与集群版处理数据效率对比。
实验方法
抽取oracle数据库数据,然后进行记录清洗转换,对比处理时间。
实验环境
软件:oracle11g,nifi1.8
硬件:3个节点,linux 2.6.32-573.el6.x86_64,nifi运行内存最大8G
数据:6700W条数据,每个批次100W条
耗时:集群14分30秒,单机24分钟30秒
总结:集群比单机效率高70%左右,大约1天60亿左右数据抽取
5.nifi集群节点加入与卸载,数据处理及分发情况。
Nifi节点如果成功加入集群,则依据负载均衡策略进行分发,若是选择round bin策略,则直接均分数据到该节点,若单节点分发策略,则不会给新节点分配数据。
Nifi集群在处理数据时,集群节点disconnect,则该节点上的数据会继续自动处理,但是不会再给该节点分发数据。
6.nifi处理器可以查看数据的处理情况。
Nifi的每一个处理器可以查看经过这个处理器处理的数据的详细信息,可以查看处理时间,处理过程,详细信息等。数据没有老化时,还可以浏览数据和下载数据,还可以将数据处理的某个环节重新走一遍。
Nifi数据下载及情况查看都有其有效期,数据默认存储12个小时,当超过这个时间后,默认数据删除,则无法下载数据和进行replay操作,值得注意的是content repository还有个属性配置为max.usage.percentage,该属性指定内容仓库磁盘利用的最大百分比,默认为50%,实际使用时要按照实际情况进行修改,当磁盘利用超过该比例时,数据落盘存储会受到影响,可能出现刚处理的数据也无法进行查看下载的情况。
7.nifi用户认证模式下,权限控制有哪些。
全局权限如下:
l 是否能访问nifi界面
l 是否能看或者修改控制器,包括报告、控制器服务以及集群中的节点
l 是否能查询文件处理的历史
l 是否能访问限制的处理器:能访问所有限制处理器、能访问需要访问密钥的限制处理器、能访问需要执行代码的限制处理器、能访问需要输出nifi详情的限制处理器、能访问需要读取文件系统的限制处理器、能访问需要写文件的限制处理器
l 是否允许看或者修改所有组件的权限
l 是否允许看或者修改用户/用户组
l 是否允许其他nifi实例查看到此nifi的site-to-site的详细信息
l 是否允许查看系统诊断
l 是否允许代理机器代替其他人发送请求
l 允许用户看或者修改计数器
处理组内的权限控制如下
l 允许用户访问组件
l 允许用户配置使用组件
l 允许用户操作组件,修改组件状态(启停控制等)
l 允许用户查看组件产出的出处事件
l 允许用户查看队列中数据的详情
l 允许用户清空队列或提交某个事件的replay请求
l 允许用户查看能查看或修改组件的人员列表
l 允许用户修改能查看或修改组件的人员列表
8.nifi处理器的Run Schedule的作用
Run schedule为任务执行的间隔时间,这个属性的作用要根据具体的处理器去区分,如获取处理器与其他处理器意义不同,获取处理器表示多长时间执行一次该处理器,等同于多长时间执行一次任务,而其他处理器也表示多长时间执行一次该处理器,但是不等于任务的间隔,因为其他处理器的任务调度是当有flowfile传过来时才触发,此时这个时间就相当于监听的间隔,当没有flowfile时不会触发任务,否则触发一次任务。
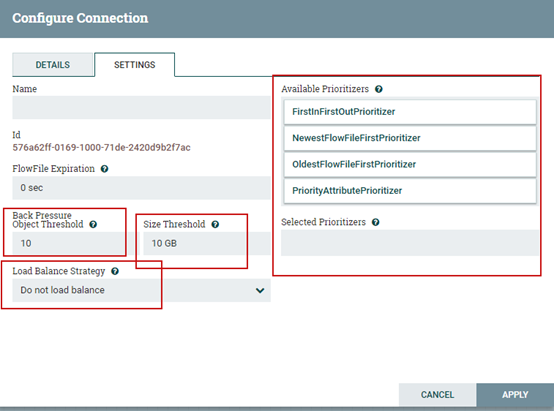
9.nifi背压设置与连接设置
Nifi处理器之间通过connection进行连接,连接也是数据流暂存的队列,当数据从A处理器往B处理器流转时,根据选定的关系,流向不同的连接,然后被不同的处理器处理,当B处理器处理能力受限(未启动或处理不及时)时,数据暂存在连接中,但是连接也不是可以无限存储数据的,我们可以通过连接的配置来设置连接的背压值,包括能存放的对象最大数量,能存放的对象最大值等,可以选择不同的策略来设置队列中的数据被处理的顺序,如果在集群中设置,则还可以选择负载均衡策略。
一般处理器都包含成功和失败两种关系,成功关系一般路由到下一个处理器,而失败处理器一般设置路由到自身,这样队列会每隔一段时间就会尝试将失败队列中的数据进行重新处理,直到数据处理成功。