

目录
flume
快速开始
概述
Apache Flume 是一个分布式、可靠且可用的系统,用于有效地收集、聚合来自许多不同来源的大量日志数据并将其移动到集中式数据存储。
Apache Flume 的使用不仅限于日志数据聚合。由于数据源是可定制的,Flume 可用于传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息和几乎任何可能的数据源。
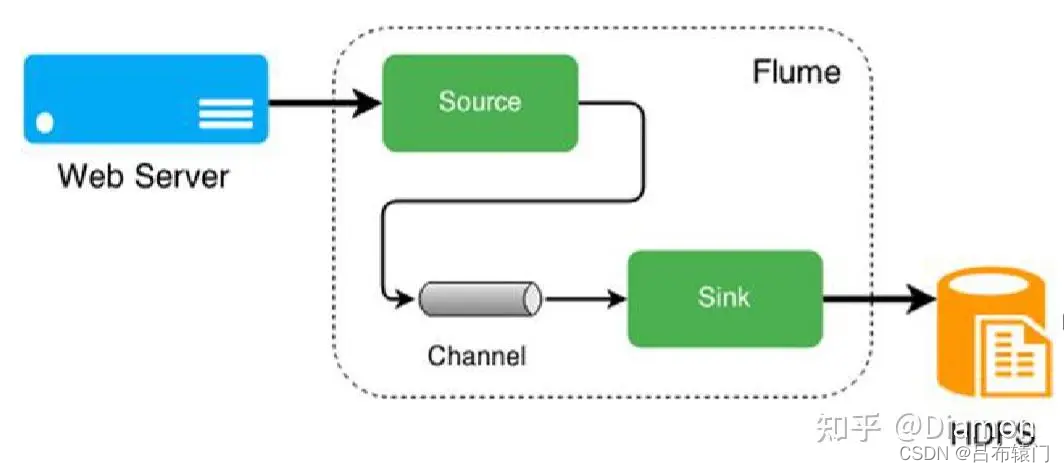
通常将Web服务器收集日志文件,然后传递到HDFS进一步处理。
系统要求
- Java 运行时环境 - Java 1.8 或更高版本
数据流模型
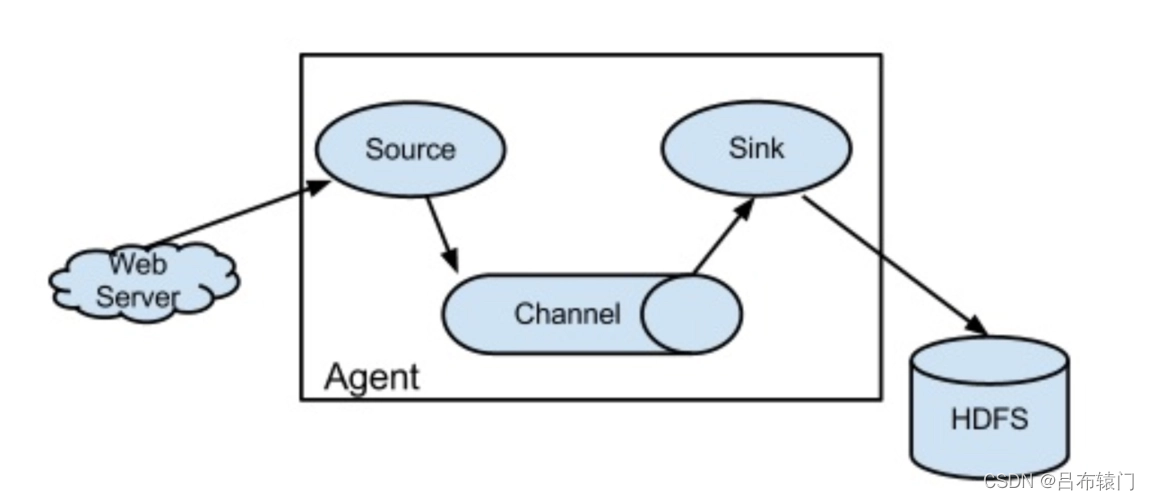
Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。
flume传输的数据的基本单位是 event
flume代理是agent,agent是一个java进程,运行在日志收集节点。
每一个 agent 相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据;
- Sink:目的地,采集数据的传送目的,用于往下一级 agent 传递数据或者往最终存储系统传递数据;
- Channel:通道,agent 内部的数据传输通道,用于从 source 将数据传递到 sink;
Flume由一组分布式互相连接的代理构成,系统边缘(与web服务器共存一台)的代理负责收集日志,并把数据转发给负责汇总的代理。使用Flume主要工作就是把各个代理连接在一起。
安装
$ wget https://archive.apache.org/dist/flume/stable/apache-flume-1.9.0-bin.tar.gz
$ tar -zxvf apache-flume-1.9.0-bin.tar.gz
# 验证
$ bin/flume-ng version
Flume 1.9.0
一个简单的例子
接收telnet 终端消息到控制台。
我们给出一个示例配置文件,描述单节点 Flume 部署。此配置允许用户生成事件并随后将它们记录到控制台。
# example.conf:单节点 Flume 配置
# 命名此代理上的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述配置源
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述接收器
a1.sinks.k1.type = logger
# 使用在内存中缓冲事件的通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
此配置定义了一个名为 a1 的代理。a1 有一个在端口 44444 上侦听数据的源,一个在内存中缓冲事件数据的通道,以及一个将事件数据记录到控制台的接收器。配置文件命名各种组件,然后描述它们的类型和配置参数。一个给定的配置文件可能定义了几个命名代理;当启动给定的 Flume 进程时,会传递一个标志,告诉它要显示哪个命名代理。
有了这个配置文件,我们可以按如下方式启动 Flume:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
#后台启动
$ nohup bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console &
请注意,在完整部署中,我们通常会多包含一个选项:--conf=<conf-dir>。< conf-dir>目录将包含一个 shell 脚本flume-env.sh和一个可能的 log4j 属性文件。在这个例子中,我们传递了一个 Java 选项来强制 Flume 登录到控制台,并且我们没有自定义环境脚本。
从一个单独的终端,我们可以 telnet 端口 44444 并向 Flume 发送一个事件:
#安装telnet
$ yum install -y telnet
$ telnet localhost 44444
然后输入一些字符串回车,最后原始 Flume 终端将在日志消息中输出事件。
采集源
目录源
此源允许您通过将要摄取的文件放入磁盘上的目录来摄取数据。此源将监视指定目录中的新文件,并在新文件出现时从新文件中解析事件。事件解析逻辑是可插拔的。给定文件完全读入通道后,默认情况下通过重命名文件来指示完成,或者可以将其删除,或者使用 trackerDir 跟踪处理过的文件。
Flume 尝试检测这些问题条件:
- 如果一个文件在放入 spooling 目录后被写入,Flume 将在其日志文件中打印一个错误并停止处理。
- 所监视的目录中重复出现相同文件名的文件,Flume 将在其日志文件中打印错误并停止处理。
为避免上述问题,在将文件名移动到监视目录时,将唯一标识符(例如时间戳)添加到日志文件名可能很有用。
a1.channels = c1
a1.sources = source1
a1.sources.source1.type = spooldir
a1.sources.source1.channels = c1
a1.sources.source1.spoolDir = /opt/logs
a1.sources.source1.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a1.sources.source1.ignorePattern = ([^ ]*\.tmp)
执行源
Exec source 在启动时运行给定的 Unix 命令,并期望该进程在标准输出上连续生成数据。如果进程因任何原因退出,源也会退出并且不会产生更多数据。这意味着诸如cat [named pipe] 或tail -F [file]之类的配置将产生所需的结果。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
Kafka源
Kafka Source 是一个 Apache Kafka 消费者,它从 Kafka 主题中读取消息。如果您有多个 Kafka 源在运行,您可以使用相同的 Consumer Group 配置它们,以便每个都读取一组唯一的主题分区。这目前支持 Kafka 服务器版本 0.10.1.0 或更高版本。测试一直到 2.0.1,这是发布时可用的最高版本。
以逗号分隔的主题列表订阅主题的示例。
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.id = custom.g.id
通过正则表达式订阅主题的示例
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka .topics.regex = ^topic[0-9]$
# 默认使用 kafka.consumer.group.id=flume
NetCat TCP 源
一个类似 netcat 的源,它侦听给定端口并将每一行文本转换为一个事件。类似于nc -k -l [host] [port]。换句话说,它打开一个指定的端口并监听数据。期望提供的数据是换行符分隔的文本。每一行文本都会变成一个 Flume 事件并通过连接的通道发送。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.channels = c1
avro source
avro可以监听和收集指定端口的日志,使用avro的source需要说明被监听的主机ip和端口号
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
接收器
logger sink
就是将收集到的日志写到flume的log中,是个十分简单但非常实用的sink
简单实用,但是在实际项目中没有太大用处。
agent1.sinks.sink1.type = logger
avro sink
avro可以将接受到的日志发送到指定端口,供级联agent的下一跳收集和接受日志,使用时需要指定目的ip和端口
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 0.1.1.1
a1.sinks.k1.port = 4545
HDFS 接收器
此接收器将事件写入 Hadoop 分布式文件系统 (HDFS)。它目前支持创建文本和序列文件。它支持两种文件类型的压缩。可以根据经过的时间或数据大小或事件数定期滚动文件(关闭当前文件并创建新文件)。它还按时间戳或事件起源的机器等属性对数据进行存储/分区。HDFS 目录路径可能包含格式转义序列,这些转义序列将被 HDFS 接收器替换以生成目录/文件名来存储事件。使用此接收器需要安装 hadoop,以便 Flume 可以使用 Hadoop jar 与 HDFS 集群进行通信。
注意:使用前需提供hadoop的库,参考问题1
需修改 flume-env.sh 配置,增添 hdfs 依赖库:
FLUME_CLASSPATH=“/opt/hadoop/:/opt/hadoop/hadoop-hdfs/:/opt/hadoop/lib/*”
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://cluster-master:9000/flume/logs/%y-%m-%d/%H%M/%S
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
hdfs创建新文件的周期可以是时间,也可以是文件的大小,还可以是采集日志的条数。
filePrefix = log_%Y%m%d_%H hdfs 文件名前缀
fileSuffix = .lzo 文件名后缀
inUsePrefix 临时文件名前缀
inUseSuffix 临时文件的文件名后缀 默认值:.tmp
rollSize = 0 默认值:1024
当临时文件达到该大小(单位:bytes)时,滚动成目标文件;
如果设置成0,则表示不根据临时文件大小来滚动文件
rollInterval = 600 默认值:10
当events数据达到该数量时候,将临时文件滚动成目标文件;
如果设置成0,则表示不根据events数据来滚动文件;
batchSize = 100 默认值:100
每个批次刷新到HDFS上的events数量;
导入jar包
为了让我们的flume和hadoop交互,所以我们进入/hadoop/share/hadoop/common和/hadoop/share/hadoop/hdfs两个文件夹找到下图的六个jar包导入到flume/lib/中即可。
问题:
1、Flume 报出异常org/apache/hadoop/io/SequenceFile$CompressionType
原理:缺少hadoop类库,其他报类库问题同理。
commons-configuration-*.jar
hadoop-auth-*.jar
hadoop-common-*.jar
hadoop-hdfs-*.jar
commons-io-*.jar
woodstox-core
stax2-api
guava-2.8.9.jar 删除flume老的
hadoop-shaded-guava-1.1.1.jar
hadoop-hdfs-client-3.3.2.jar
hadoop-shaded-protobuf_3_7-1.1.1.jar
$ cp ${HADOOP_HOME}/share/hadoop/common/hadoop-common-3.3.2.jar /opt/apache-flume-1.9.0-bin/lib
2、Expected timestamp in the Flume event headers, but it was null
a1.sinks.k1.hdfs.useLocalTimeStamp = true
3、org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme “hdfs”
hadoop-hdfs-client-3.3.2.jar
4、java.lang.NoClassDefFoundError: org/apache/hadoop/thirdparty/protobuf/Message
hadoop-shaded-protobuf_3_7-1.1.1.jar
弹性搜索接收器
此接收器将数据写入弹性搜索集群。默认情况下,将写入事件以便Kibana图形界面可以显示它们 - 就像logstash编写它们一样。
您的环境所需的 elasticsearch 和 lucene-core jar 必须放在 Apache Flume 安装的 lib 目录中。Elasticsearch 要求客户端 JAR 的主要版本与服务器的主要版本匹配,并且两者都运行相同的 JVM 次要版本。如果这不正确,将会出现 SerializationExceptions。要选择所需的版本,首先确定elasticsearch的版本和目标集群正在运行的JVM版本。然后选择与主版本匹配的 elasticsearch 客户端库。0.19.x 客户端可以与 0.19.x 集群通信;0.20.x 可以与 0.20.x 对话,0.90.x 可以与 0.90.x 对话。一旦确定了 elasticsearch 版本,然后读取 pom.xml 文件以确定要使用的正确 lucene-core JAR 版本。
每天都会将事件写入新索引。该名称将为 -yyyy-MM-dd 其中 是 indexName 参数。接收器将在 UTC 午夜开始写入新索引。
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = elasticsearch
a1.sinks.k1.hostNames = 127.0.0.1:9200,127.0.0.2:9300
a1.sinks.k1.indexName = foo_index
a1.sinks.k1.indexType = bar_type
a1.sinks.k1.clusterName = foobar_cluster
a1.sinks.k1.batchSize = 500
a1.sinks.k1.ttl = 5d
a1.sinks.k1.serializer = org.apache.flume.sink.elasticsearch.ElasticSearchDynamicSerializer
a1.sinks.k1.channel = c1
多层代理
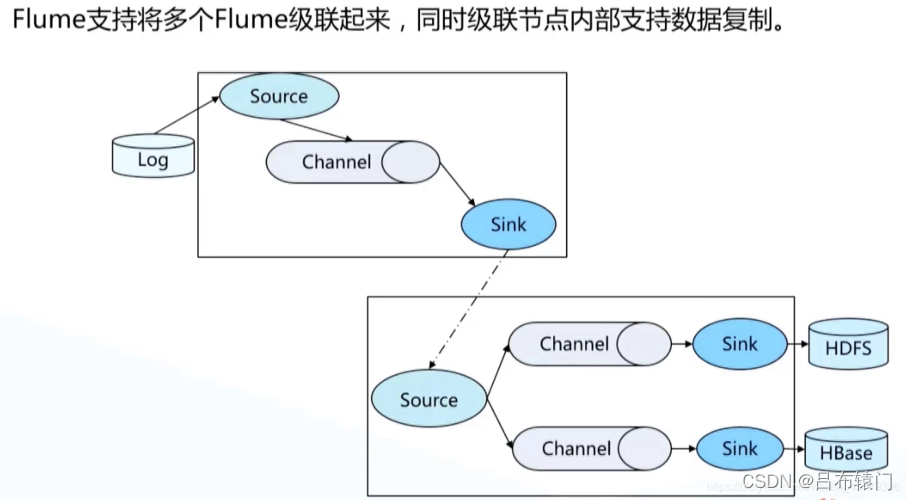
当我们用Flume采集日志时,由于数据源的多样性,则往往需要配置多个Flume进行采集,如果只是使用单层Flume的话,那么往往会产生很多个文件夹,单个文件夹也只是来自同一个节点的数据组成的。因此,为了减少文件的数据,增加文件的大小(减少HDFS的压力,同时提高MapReduce的处理效率)。往往会将同一组多个节点的数据汇聚到同一个文件中,这样同时也较少了数据从生产到分析的时间。
第一层agent负责采集原始数据,第二层agent负责对第一层数据进行汇聚,并把数据写入HDFS中。如果source节点数据量庞大的时候,最好采用多层代理。
从tail命令获取数据发送到avro端口(mini1机器)
另一个节点可配置一个avro源来中继数据,发送外部存储
tail-avro.conf:
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = mini02
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
从avro端口接收数据,下沉到logger(mini02机器)
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
命令的执行
mini02上执行
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
mini01上执行
bin/flume-ng agent -c conf -f conf/tail-avro.conf -n a1
同时模拟mini01数据的写入:
i=1;
while(( $i<=500000 ));
do echo $i >> /home/hadoop/log/test.log;
sleep 0.5;
let ‘i++’;
done
实战
采集目录文件到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
-
数据源组件,即source ——监控文件目录 : spooldir
-
下沉组件,即sink——HDFS文件系统
-
通道组件,即channel——可用file channel 也可以用内存channel
配置文件
a1.channels = c1
a1.sources = source1
a1.sinks = k1
# 描述配置源
a1.sources.source1.type = spooldir
a1.sources.source1.channels = c1
a1.sources.source1.spoolDir = /opt/logs
a1.sources.source1.fileHeader = true
a1.sources.source1.ignorePattern = ([^ ]*\.tmp)
# 描述接收器
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://cluster-master:9000/flume/logs/%y-%m-%d
a1.sinks.k1.hdfs.filePrefix=logs-%H-%M
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = TEXT
# 使用在内存中缓冲事件的通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel
a1.sources.source1.channels = c1
a1.sinks.k1.channel = c1
启动
$ bin/flume-ng agent --conf conf --conf-file conf/example1.conf --name a1 -Dflume.root.logger=INFO,console

 浙公网安备 33010602011771号
浙公网安备 33010602011771号