实验记录 | ChatGLM-6B 部署/微调
ChatGLM-6B 部署/微调
Experimental Setup
参考 [1] [2] [3] [4] 进行实验。加速卡为海光 DCU。
- nproc = 8
- Core(s) per socket = 32
- CPU: 海光 7285
- GPU: DCU@16GB
- DTK Version = v24.04.1
- Python 3.10
Run
终端运行
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:33<00:00, 4.13s/it]
欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户:百年孤独的作者是谁
ChatGLM-6B:《百年孤独》的作者是哥伦比亚作家加夫列尔·加西亚·马尔克斯(Gabriel García Márquez)。
用户:介绍其生平
ChatGLM-6B:加夫列尔·加西亚·马尔克斯(Gabriel García Márquez)出生于1924年,成长于哥伦比亚的一个小镇。他的家庭是当地的医生和律师,他的祖父曾在哥伦比亚的政治舞台上活跃过。
马尔克斯在年轻时就开始写作,他的第一本小说《伊豆的舞女》出版于1948年。他的作品一直受到读者的欢迎,包括《百年孤独》、《霍乱时期的爱情》和《百年孤独》的续集《马尔克斯与百年孤独》。
马尔克斯于1985年去世,但他的作品仍然被广泛阅读和翻译。他的作品风格独特,充满了魔幻现实主义和神秘的色彩,被认为是20世纪最伟大的作家之一。
用户:stop
root@worker-0:~/proj/ChatGLM-6B/ChatGLM-6B-main#
Web GUI
安装 Streamlit/Streamlit_Chat 后运行 Web GUI
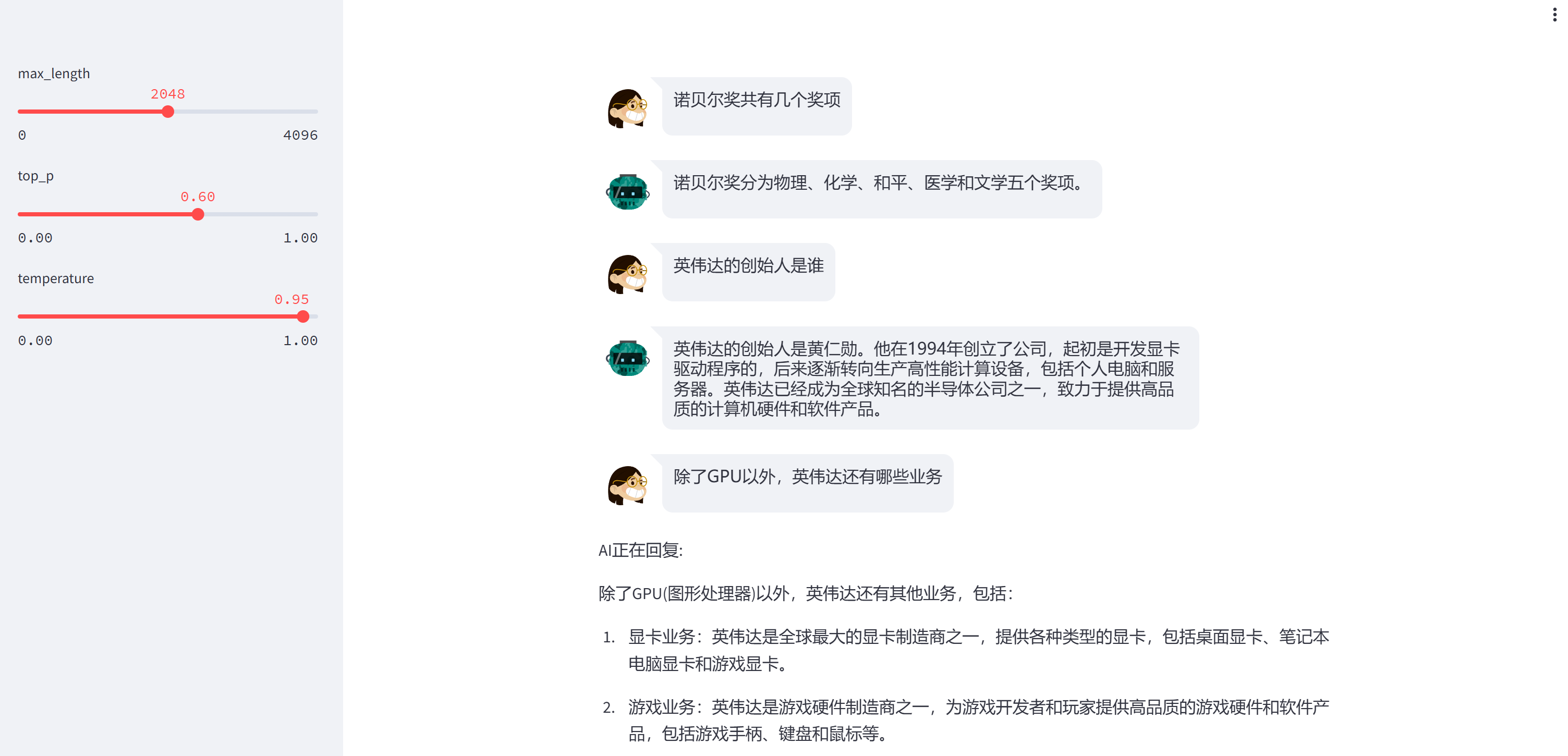
Tuning
使用 ADGEN (广告生成) 数据集微调。
Debug
执行 bash train.sh 后报错
TypeError: JsonConfig.__init__() got an unexpected keyword argument 'use_auth_token'
查阅知,这是 datasets 版本问题,当前安装了v 3.1.0,降级到 v2.19.0 后能够运行 (实际上应该降到 <= v2.14)
RuntimeError: Library cudart is not initialized
启用 INT4 量化后报此错误,一般建议重装 CUDA 或 cudatoolkit,DTK 环境下暂时无解,只能关闭量化。和工程师协商后在 FP16 下监控了训练,显存未超限。
Traceback (most recent call last): File "/root/proj/ChatGLM-6B/ChatGLM-6B-main/ptuning/web_demo.py", line 99, in <module> user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style( AttributeError: 'Textbox' object has no attribute 'style'. Did you mean: 'scale'?
找到了关于该问题的一个 Issue,同样是版本问题,将 gradio v5.6 降到 v3.39 便可以了。
Train

Evaluate
运行推理耗时约 2h,同样不能开启量化。
Building prefix dict from the default dictionary ...
11/28/2024 16:40:55 - DEBUG - jieba - Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
11/28/2024 16:40:56 - DEBUG - jieba - Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.995 seconds.
11/28/2024 16:40:56 - DEBUG - jieba - Loading model cost 0.995 seconds.
Prefix dict has been built successfully.
11/28/2024 16:40:56 - DEBUG - jieba - Prefix dict has been built successfully.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1070/1070 [2:13:59<00:00, 7.51s/it]
***** predict metrics *****
predict_bleu-4 = 8.0302
predict_rouge-1 = 31.6065
predict_rouge-2 = 7.1658
predict_rouge-l = 24.9446
predict_runtime = 2:14:15.43
predict_samples = 1070
predict_samples_per_second = 0.133
predict_steps_per_second = 0.133
root@worker-0:~/proj/ChatGLM-6B/ChatGLM-6B-main/ptuning#
Web GUI
修改 web_demo.py line 161
- demo.queue().launch(share=False, inbrowser=True)
+ demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=28888)
任何通过反向代理的 Web 请求都有可能面临 url 构造错误的问题,在此,Streamlit 做得要比 Gradio 更完善。
运行 Demo 时 css 未能正常加载,按钮也不能工作,检查发现有两个请求 404 了。尝试修复该问题,见 [5]。最后虽未能完整运行,但 evaluate.sh 的推理输出已经说明项目基本跑通了,便告一段落吧。
Summary
小卡玩起来捉襟见肘,以后还是往 RAG 方向使劲吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号