redis 面试知识
6.0之前都是单线程指的是网络io和键值对读写
6.0之后只网络io变成了多线程
为什么这么快
- 基于纯内存操作,一次操作几十纳秒
- 单线程操作,没有线程之间切换
- 基于io多路复用机制,提升复用效率
- 高效的数据存储结构,简单动态字符O(1)且二进制安全,跳表(有序链表改成的多层链表,场景:排序),压缩列表(压缩列表是 List 、hash、 sorted Set 三种数据c类型底层实现之一),hash字典(链式hash解决冲突),双向链表(场景:队列,特性:双端无环带头指针和尾指针带长度计数器)等
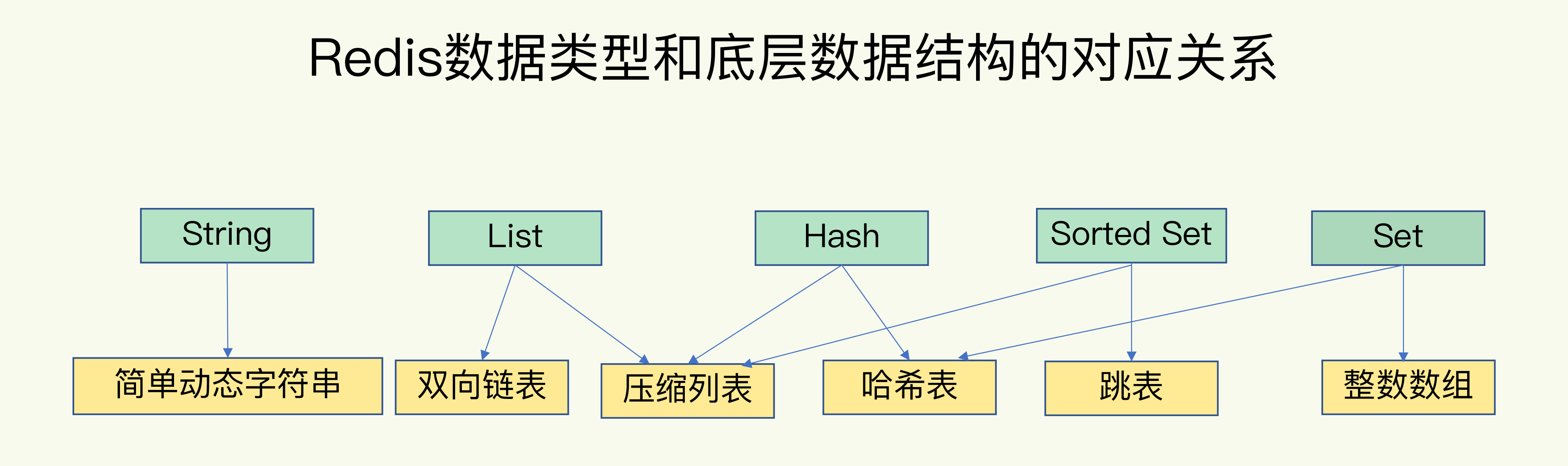
基本数据类型
- String: 缓存、计数器、分布式锁等(底层是简单动态字符串)。
- List: 链表、队列、微博关注人时间轴列表等。
- Hash: 用户信息、Hash 表等(数据结构是hashtable或者ziplist)。
- Set: 去重、赞、踩、共同好友等(数据结构是intset或hashtable)。
- Zset: 访问量排行榜、点击量排行榜等(数据结构是 ziplist或zkiplist)。
redis动态字符串高效的原因:
- 动态内存分配
- 自动扩容
- 避免内存复制
- 高效操作(可以截取插入等)
redis数据过期为什么内存没有释放
- 惰性删除(读写时才会删除)
- 定期删除(默认100ms,一次一部分,系统每隔一段时间就定期扫描一次,发现过期的键就进行删除)
- 定时删除:为每个键设置一个定时器,一旦过期时间到了,则将键删除。这种策略对内存很友好,但是对 CPU 不友好,因为每个定时器都会占用一定的 CPU 资源。
redis key没设置过期时间为什么被主动删除了
- 设置了过期的策略
- volatile-ttl,过期自动删除
- volatile-random 设置了过期时间进行随机删除
- volatile-lru LRU(最少使用,以访问时间为基准)算法进行删除
- volatile-lfu LFU(最少使用,以访问次数为基准,大量热点缓存数据时用)算法进行删除
- 针对所有的key处理
- allkeys-random 随机清除
- allkeys-LRU LRU清除
- allkeys-LFU LFU清除
- 不处理
不删除任何数据,拒绝写入并返回错误 OOM
删除key的命令会阻塞吗?
O(N) N为被删除的元素数量
删除字符串O(1)
删除列表,集合,有序集合或者hash表时间复杂度O(M),这时会阻塞
集群主节点进行分段如 0-5000 5000-10000 10000-16383
hash分片算法,将key定位到不同的主节点
CRC16 % 16384
randomKey 随机返回一个key,在slave中执行可能会导致redis死循环(主要是不停的命中了过期key),slave需要master删除后向slave发起一个DEL命令才会删除过期数据
主从切换导致的缓存雪崩
slave时钟比master快很多,导致slave判定已过期但master未过期,主从切换时slave会大批量的清理过期数据导致阻塞
RDB(将内存数据缓存到dump.rdb的磁盘文件,目录在配置文件的dir开头的目录,默认开启的是RDB)
vim redis.conf
save 60 100 (60s秒内修改了100条记录就触发),可配置多条记录
用save命令写rdb时会阻塞其他命令
可用bgsave命令,触发bgsave机制(fork的子进程),copy-on-write COW写时复制技术(允许写内存且同步写rdb文件)
AOF
APPEND ONLY FILE 写入默认 appendonly.aof后缀文件,只记录修改命令,会产生垃圾命令
vim redis.conf
appendonly yes
有三个策略
appendfsync always 每次更改写
appendfsync everysec 每秒执行一次,默认的
appendfsync no 不主动发起持久化,由操作系统调配
AOF重写(AOF数据恢复,如incre等命令多次执行之后进行重写为SET)
vim redis.conf
auto-aof-rewrite-percentage 100 //下一次aof到上一次的aof文件大小的一倍时再触发
auto-aof-rewrite-min-size 64mb //文件超过64M就重写
或者操作
bgrewriteaof 命令来执行一次aof重写
默认通过AOF来恢复数据
混合持久化
必须要开启AOF
aof-use-rdb-preamble yes //默认是关闭
这时可以关闭RDB,即注释掉save命令配置
实际操作是将之前的AOF按照RDB格式保存,后续的就用AOF命令保存
线上事故
master未持久化
slave宕机,supervisor让slave重启,同步master数据发现master为空,就会清空slave数据,造成缓存全部丢失
解决方案:不应该配置宕机立即重启策略,应该等哨兵把某个slave选择为主节点,让之前的master变为slave节点。
redis备份
crontab 每隔一段时间copy RDB或者AOF文件到另外一台机器或者目录中去,删除较老的数据
主从复制风暴
多个从节点同时从主节点去复制数据,造成主节点压力过大
解决方案
采用多层树形结构
网络抖动导致主从频繁切换
解决方案:
设置 cluster-node-timeout=5
redis集群为什么至少需要3个节点
至少需要半数以上的master选举
redis集群支持批量操作吗
mset mget
支持,但是缓存必须要落在同一个slot上,解决方案:添加相同前缀如用户ID
LUA脚本在REDIS集群里执行吗
可以,但是缓存必须要落在同一个slot上,解决方案:添加相同hashTag前缀
redis主从切换导致锁丢失
锁添加在某个节点上,宕机后后续请求到其他节点上。
冷热分离
设置有效期,查到缓存就延长有效期
缓存击穿
指的是高并发同时访问到了缓存里过期数据去读取到了数据库数据
场景:批量写缓存时,批量过期
解决方案:
1.预先设置热门数据
2.设置每个键过期时间时再加上一段随机时间,达到不同时过期
3.使用锁,一个请求去拿数据的时候其他请求等待
缓存穿透
指的是高并发访问到了数据库数据,导致数据库宕机
场景:访问到了不存在的数据比如不存在的商品
解决方案:
1.缓存空记录固定时间+随机超时时间
2使用布隆过滤器缓存有效数据,不在过滤器里的记录一律拒绝
3.使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问(类似于布隆过滤器)
4.空值缓存
5.实时监控,命中率开始急速降低,需要排查访问对象和访问的数据
缓存雪崩
由于缓存层承载着大量请求,有效保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求到达存储层,存储层的调用量会暴增,造成存储层级联宕机的情况。
1.构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
2.使用锁或队列
3.设置过期标志更新缓存(实际未过期,如提前几分钟就用其他线程去再预热)
4.将缓存失效时间分散开
缓存无底洞
缓存节点增加后链接效率下降(主要原因是hash存储的实例过多导致网络IO增加)
1.减少mget这种批量操作
2.集群以项目组做隔离
redis 查询性能
INFO 命令,能够随时监控服务器的状态,
在输出的信息里面有这几项和缓存的状态比较有关系:
keyspace_hits:14414110
keyspace_misses:3228654
used_memory:433264648
expired_keys:1333536
evicted_keys:1547380
通过计算hits和miss, 得到缓存的命中率:14414110 / (14414110 + 3228654) = 81%
IO的优化思路:
(1) 命令本身的效率:例如sql优化,命令优化。
(2) 网络次数:减少通信次数。
(3) 降低接入成本:长连/连接池,NIO等。
(4) IO访问合并:O(n)到O(1)过程:批量接口(mget)。
redis开启慢日志
redis-cli CONFIG SET slowlog-log-slower-than 6000
只需要查看最后 2 个慢命令,输入 slowlog get 2 即可
redislatency-monitor(延迟监控)工具。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms
CONFIG SET latency-monitor-threshold 9
redis变慢原因
- 网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。 - 慢指令导致的延迟
使用增量迭代的方式,避免一次查询大量数据,具体请查看SCAN、SSCAN、HSCAN和ZSCAN命令。
- Fork 生成 RDB 导致的延迟
- 内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
- swap:操作系统分页
所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id
process_id:13160
进入此进程的 /proc 文件系统目录:
$ cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)'
Size: 316 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB
Size: 40 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 720896 kB
Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
1.增加机器内存;
2.将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
3.增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存
- AOF 和磁盘 I/O 导致的延迟
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作
避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。
- expires 淘汰过期数据
大批量缓存过期导致,大批量写入缓存时添加额外随机时间
- bigkey
Redis 内存不断变大引发 OOM,或者达到 maxmemory 设 置值引发写阻塞或重要 Key 被逐出;
Redis Cluster 中的某个 node 内存远超其余 node,但因 Redis Cluster 的数据迁移最小粒度为 Key 而无法将 node 上的内存均衡化;
bigkey 的读请求占用过大带宽,自身变慢的同时影响到该服务器上的其它服务;
删除一个 bigkey 造成主库较长时间的阻塞并引发同步中
查找 bigkey
1.redis-cli -h 127.0.0.1 -p 6379 -a "password" --bigkeys //以 scan 延迟计算的方式扫描所有 key
2. MEMORY USAGE keyname1 //查看某个键的内存使用情况
3.Rdbtools
使用 redis-rdb-tools 工具以定制化方式找出大 Key。
4.go-redis-bigkv //开源工具
解决方案
1.对大 key 拆分
2.异步清理大 key : UNLINK 命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的 Key,通过 UNLINK,你可以安全的删除大 Key 甚至特大 Key。
redis 和数据库数据不一致解决方案
双删机制
1.写库之前删缓存
2.写库之后再删,防止被其他请求写入过期数据
redisSearch
- redis创建的搜索 但不使用redis的内置数据结构sorted list
redis 脑裂
集群脑裂就是,由于redis master节点和redis salve节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到master,所以通过选举的方式提升了一个salve为master,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在old master那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将old master降为salve,这时再从新master同步数据,这会导致大量数据丢失。
解决方案:
(旧版本)
min-slaves-to-write 3
min-slaves-max-lag 10
(新版本)
min-replicas-to-write 3
min-replicas-max-lag 10
第一个参数表示最少的salve节点为3个,第二个参数表示数据复制和同步的延迟不能超过10秒
配置了这两个参数:如果发生脑裂:原master会在客户端写入操作的时候拒绝请求。这样可以避免大量数据丢失。
单机,主从,哨兵,集群区别
单机:
部署简单,0成本。
成本低,没有备用节点,不需要其他的开支。
高性能,单机不需要同步数据,数据天然一致性。
缺点:
可靠性保证不是很好,单节点有宕机的风险。
单机高性能受限于CPU的处理能力,redis是单线程的。
主从:
优点
一旦 主节点宕机,从节点 作为 主节点 的 备份 可以随时顶上来。
扩展 主节点 的 读能力,分担主节点读压力。
高可用基石:除了上述作用以外,主从复制还是哨兵模式和集群模式能够实施的基础,因此说主从复制是Redis高可用的基石。
缺点
一旦 主节点宕机,从节点 晋升成 主节点,同时需要修改 应用方 的 主节点地址,还需要命令所有 从节点 去 复制 新的主节点,整个过程需要 人工干预。
主节点 的 写能力 受到 单机的限制。
主节点 的 存储能力 受到 单机的限制。
哨兵:(哨兵不存储数据,监控和投票选出主节点)
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
Sentinel 会不断的检查 主服务器 和 从服务器 是否正常运行。当被监控的某个 Redis 服务器出现问题,Sentinel 通过API脚本向管理员或者其他的应用程序发送通知。
它的缺点:
Redis较难支持在线扩容,对于集群,容量达到上限时在线扩容会变得很复杂。
集群:(数据分片的方式来进行数据共享问题,提供数据复制和故障转移功能)
CRC16 循环校验算法
为什么不建议选择非0数据库?
1.集群状态下不支持数据库选择
2.数据不能完全隔离,安全性不够
redis 底层模型
阻塞IO
非阻塞IO
多路复用IO
异步IO
碎片整理
查看内存使用 info memory
推倒重来:重启
空间置换:
专门的参数设置用来进行自动清理内存碎片:activedefrag yes
active-defrag-ignore-bytes 100mb:碎片达到100MB时,开启清理。
active-defrag-threshold-lower 10:当碎片超过 10% 时,开启清理。
active-defrag-threshold-upper 100:内存碎片超过 100%,尽最大清理。
active-defrag-cycle-min 5:清理内存碎片占用 CPU 时间的比例不低于此值,保证清理能正常开展。
active-defrag-cycle-max 75:清理内存碎片占用 CPU 时间的比例不高于此值。一旦超过则停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致其它请求延迟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号