04_spark_RDD深入
任务执行流程
宏观执行流程
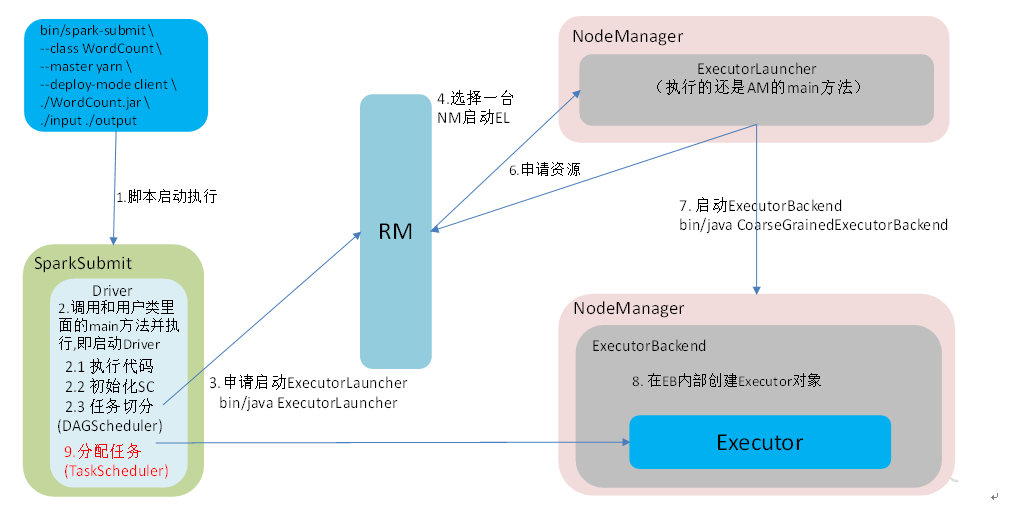
- 通过
bin/spark-submit -class [主类] --master [启动模式] --deploy-mode client WordCounter.jar ./input ./output脚本启动任务; - 启动 Driver,执行用户类的 main 方法,完成 SparkContext 初始化、任务切分;
- Driver 向 RM 申请启动
ExecutorLauncher,RM 选择一台 NM 并启动ExecutorLauncher,ExecutorLauncher 执行的是ApplicationManager的相关方法; - NM 向 RM 申请运行资源,RM 分配 NM 资源,NM 启动
ExecutorBackend并在 NM 内部创建Executor对象; - Driver 向 NM 分配任务,Executor 执行任务并响应结果。
细致到任务
RDD 将任务切分为:Application、Job、Stage、Task 几个部分。
- Application:初始化一个 SparkContext 即对应生成一个 Application;
- Job:每个 Action 算子生成一个 Job;
- Stage:Stage 等于宽依赖个数+1;
- Task:一个 Stage阶段中,最后一个 RDD 中分区个数就是 Task 的个数;
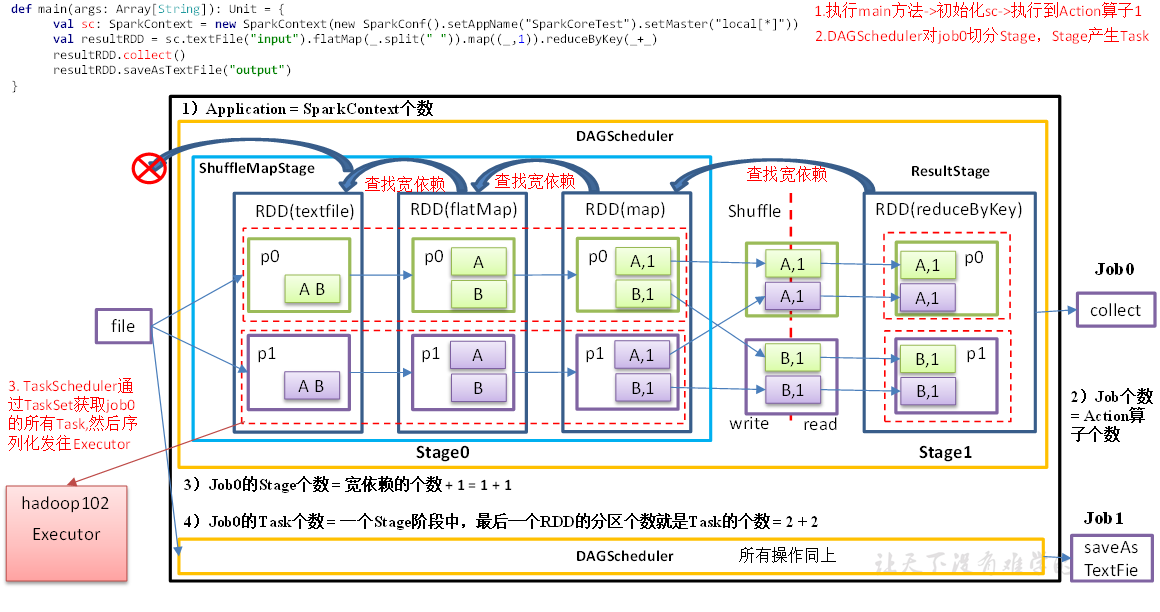
示例
如下任务执行过程代码,运行时打开 localhost:4040 即可查看任务执行情况:
object stage_test {
def main(args: Array[String]): Unit = {
lineAge()
}
def lineAge(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val lineRdd = sc.textFile("input/agent.log")
// 窄依赖,不会增加 Stage阶段
val flatMapRdd = lineRdd.flatMap(_.split(" "))
val mapRdd = flatMapRdd.map((_, 1))
// 宽依赖,增加 Stage阶段
val reduceRdd = mapRdd.reduceByKey(_ + _)
// 每个 Action 算子生成一个 Job,总共2个Job
reduceRdd.collect().foreach(println)
reduceRdd.saveAsTextFile("output")
Thread.sleep(Long.MaxValue)
sc.stop()
}
}
- Job 总个数
两个 Action 算子,产生两个 Job

- Stage 个数
Job0 因为存在
reduceByKey宽依赖,所以2个 Stage;
Job1 因为缓存了 Shuffle 阶段,所以跳过1个 Stage;
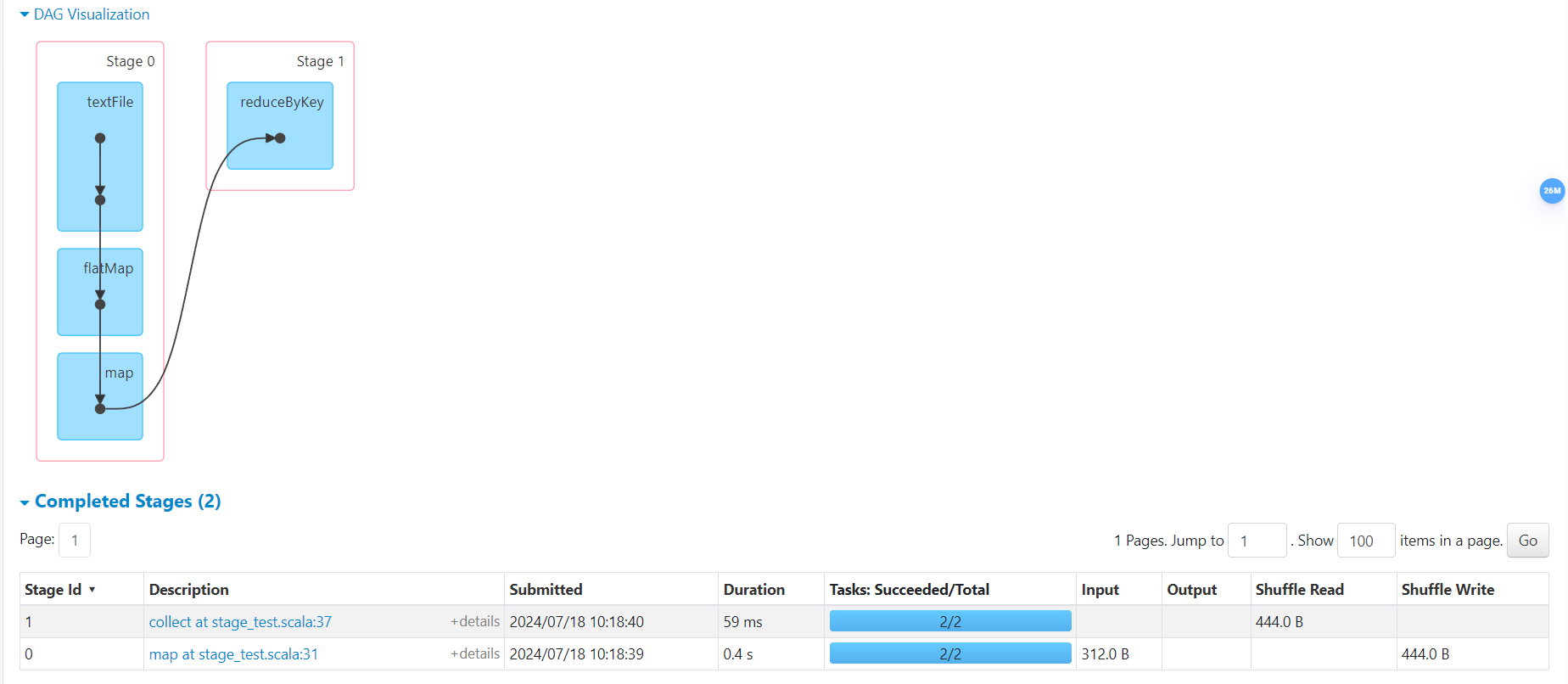
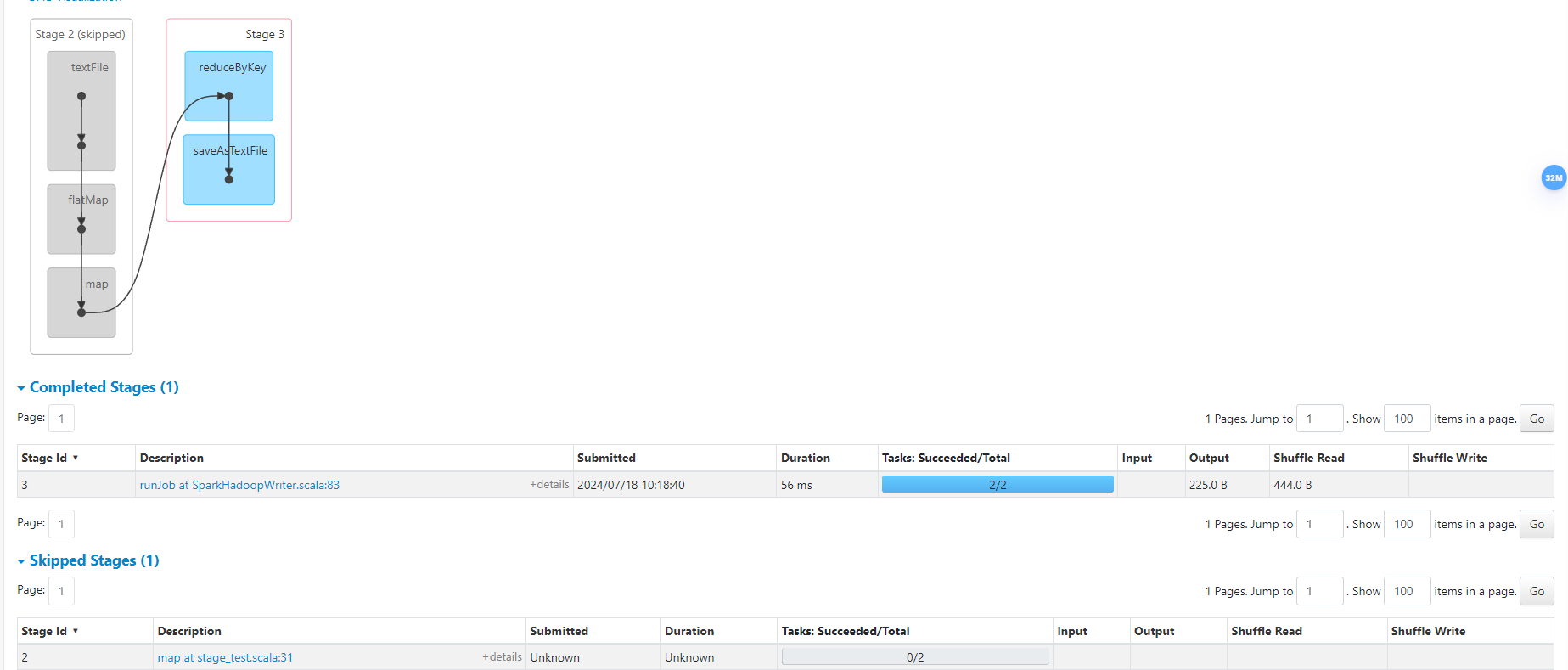
- Task 个数
![img]()

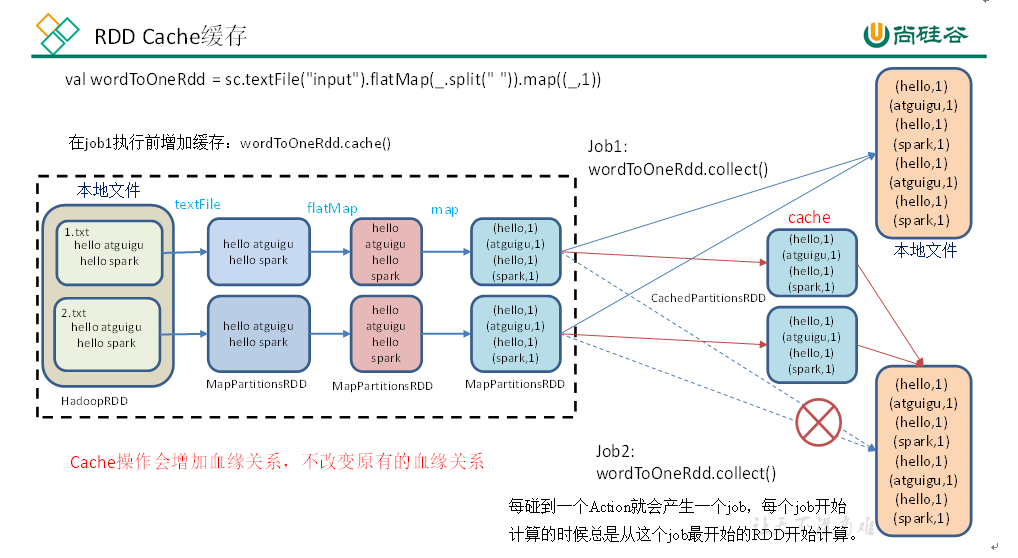
RDD 缓存及持久化
RDD 通过 Cache 或者 Persist 方法将前面计算的结果缓存,默认情况下会把数据以序列化的形式缓存在 JVM 堆内存中,但并不是调用时立刻触发,而是等待 Action 算子触发时执行。
Cache 缓存
def cacheTest(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[2]")
val sc = new SparkContext(conf)
val lineRdd = sc.textFile("input/agent.log")
// RDD分组
val flatMapRdd = lineRdd.flatMap(_.split(" "))
val wordToOneRdd = flatMapRdd.map({
word=> {
println("*******")
(word, 1)
}
})
// 数据缓存
wordToOneRdd.cache()
// 计算一
val wordByKeyRdd = wordToOneRdd.reduceByKey(_ + _)
wordByKeyRdd.collect()
println("计算1完毕")
println(wordByKeyRdd.toDebugString)
println("#########################")
// 计算二
val groupRdd = wordToOneRdd.groupByKey()
groupRdd.collect()
println("计算2完毕")
Thread.sleep(1000000000)
sc.stop()
}
关闭 Cache 时执行结果,可以发现两个 Job 重复执行了前面的窄依赖操作:
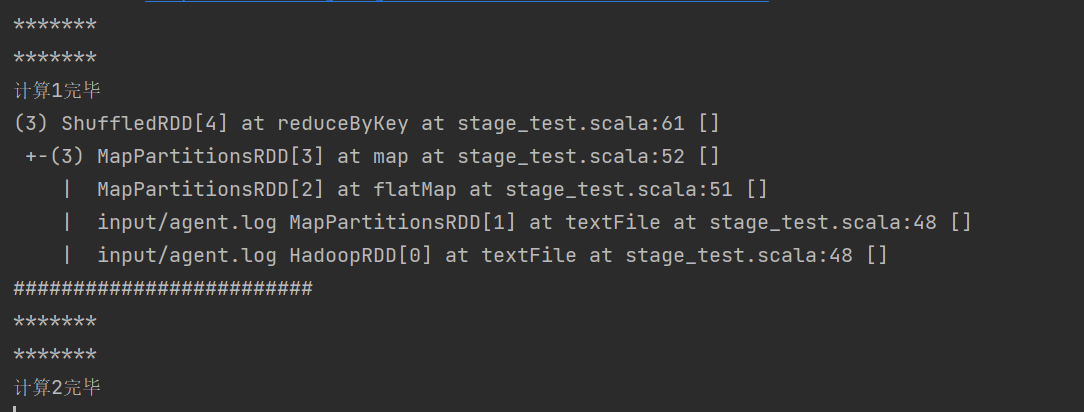
开启 Cache 时,可以发现 Job2 直接利用了 Job1 前半部分窄依赖的执行结果:
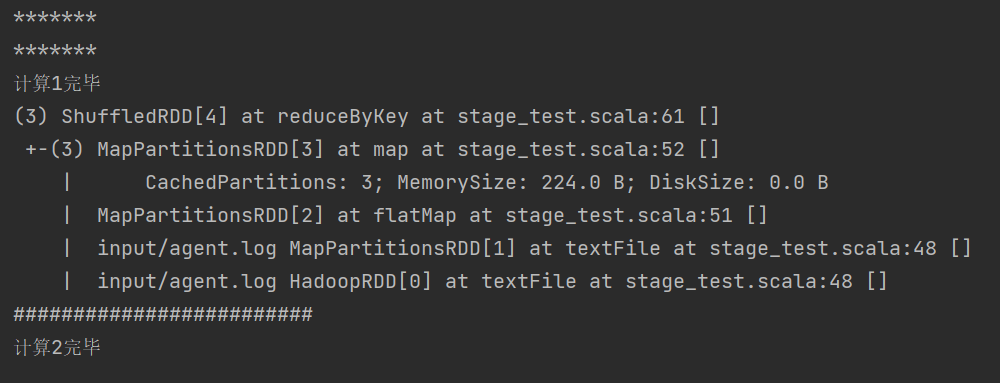
使用 Cache 时可以指定缓存等级:
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
// 数据在内存放不下则溢出写磁盘
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
// 数据在内存放不下,溢出写磁盘。内存中存放序列化后的数据
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
}
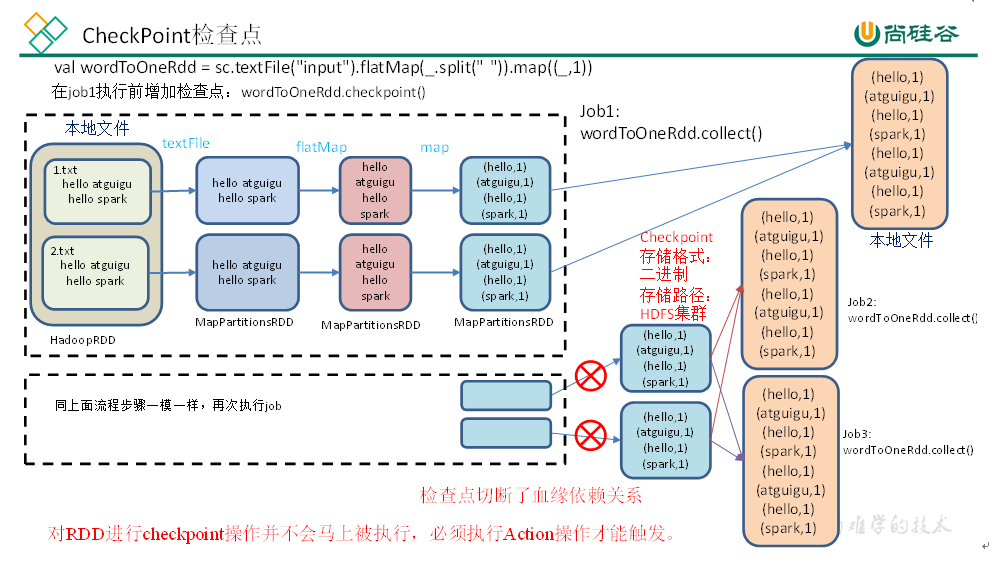
CheckPoint 检查点
Cahce 适用于同一个进程中多个任务间数据共享,如果是多个不同进程,就无法使用 Cache 中的数据,涉及到进程间通信。因此可以通过将数据写入到 HDFS 等分布式文件存储系统,实现多个进程共享 RDD 数据。
检查点为了确保数据安全,会从血缘关系最开始的地方重新执行所有算子操作,因此为了提高效率,在执行检查点操作前往往会执行一次缓存。
def checkpointTest(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[2]")
val sc = new SparkContext(conf)
// 配置检查点路径
sc.setCheckpointDir("./checkpoint1")
val lineRdd = sc.textFile("input")
// 业务处理1
val wordRdd = lineRdd.flatMap(line=>line.split(" "))
val wordToRdd = wordRdd.map(word => {
println("**************")
(word, System.currentTimeMillis())
})
// 增加缓存,避免检查点重复运行,直接从缓存中取数据
wordToRdd.cache()
// 数据检查点
wordToRdd.checkpoint()
// Job0 执行
wordToRdd.collect().foreach(println)
println("第一次执行完毕")
println("=====================")
// Job1 执行
wordToRdd.collect().foreach(println)
println("第二次执行完毕")
println("=====================")
wordToRdd.collect().foreach(println)
println("第三次执行完毕")
println("=====================")
Thread.sleep(100000000)
sc.stop()
}
关闭检查点后的操作:
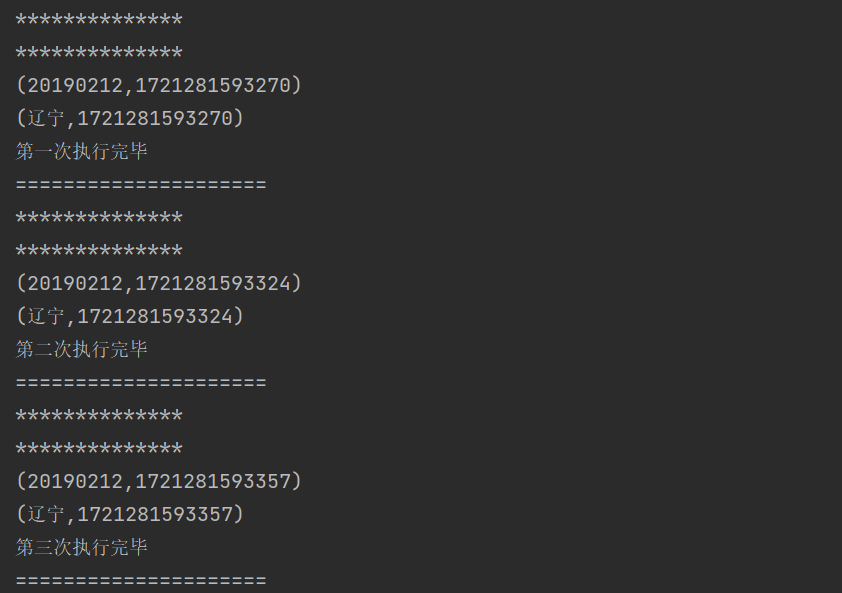
开启后,会在指定存储系统(这里默认是本地)生成 checkPoint 数据:
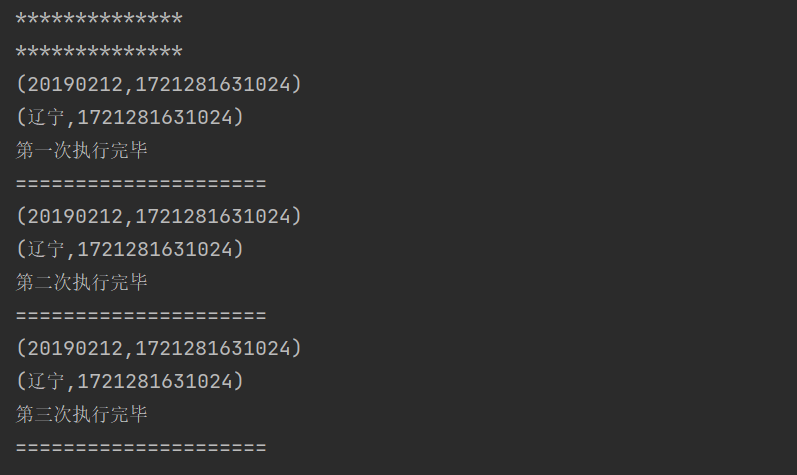
checkPoint+Cache 可以减少一次重复的数据操作:
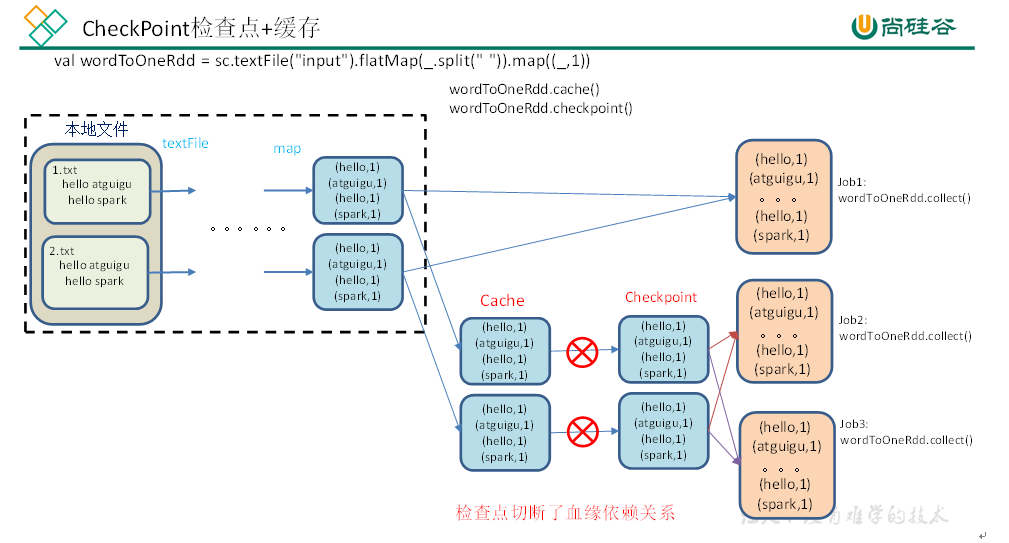
缓存和检查点对比
- 缓存只是将数据缓存起来,适用于同一个进程内部的多个任务操作,不会切断血缘;检查点适用于多个不同的进程操作,会切断血缘;
- 存储数据的媒介、可靠性不同。缓存在内存,检查点一般为 HDFS 等分布式文件存储系统,具有高可靠性。
- 建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD;
- 如果使用完了缓存,可以通过unpersist()方法释放缓存。
检查点存储到 HDFS 集群操作
def checkPoint2(): Unit = {
System.setProperty("HADOOP_HOME", "username")
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
// 配置 HDFS 检查点路径,注意需要提前在 HDFS 集群上创建检查点路径
sc.setCheckpointDir("hdfs://host:port/checkpoint")
// 初始化 RDD
val lineRdd = sc.textFile("input1")
// 业务逻辑操作
val wordRdd = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd = wordRdd.map(word => {
(word, System.currentTimeMillis())
})
// 增加缓存
wordToOneRdd.cache()
// 生成数据检查点
wordToOneRdd.checkpoint()
// 触发检查点逻辑
wordToOneRdd.collect().foreach(println)
sc.stop()
}
Spark Shuffle原理
Shuffle 操作分为两个阶段:
Map阶段:在该阶段,数据被分区并且根据键进行分组。在 Map 操作中,每个节点上的数据被处理为一个或多个键值对,并被分配到一个或多个分区中;Reduce阶段:对同一键的数据进行聚合或组合,将结果写回到磁盘或者发送到下一个操作,导致大量的网络传输和磁盘写入。
几种 shuffle 操作原理
常见以下几种操作造成 shuffe:
repartition类操作: repartition、repartitionAndWithPartitions
coalesce。by Key类操作:reduceByKey、groupByKey、SortByKey;Join类操作:join、cogroup;
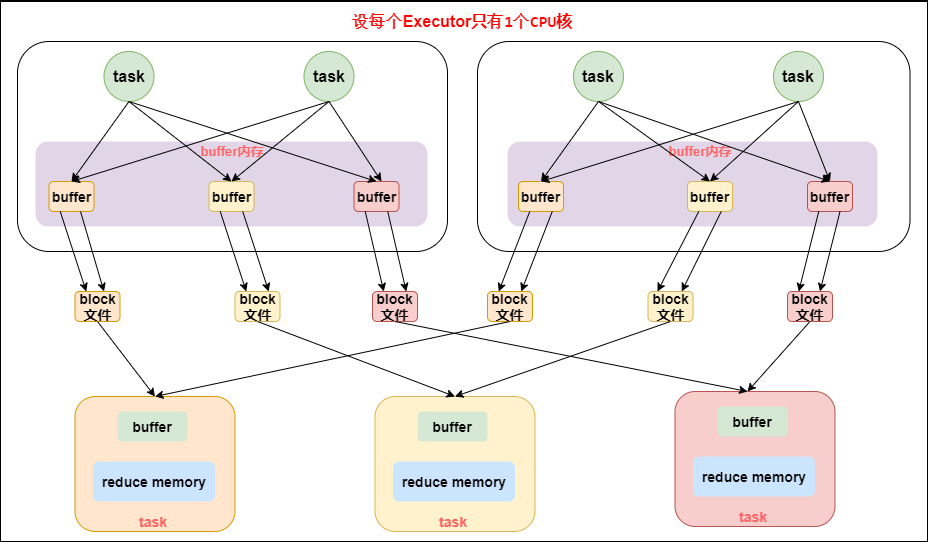
下面讲解各类 Shuffle 存在的问题,图中每个 Executor 只有 1个 Core,也就是说同一时间只能执行一个 Task。
Hash——Shuffle
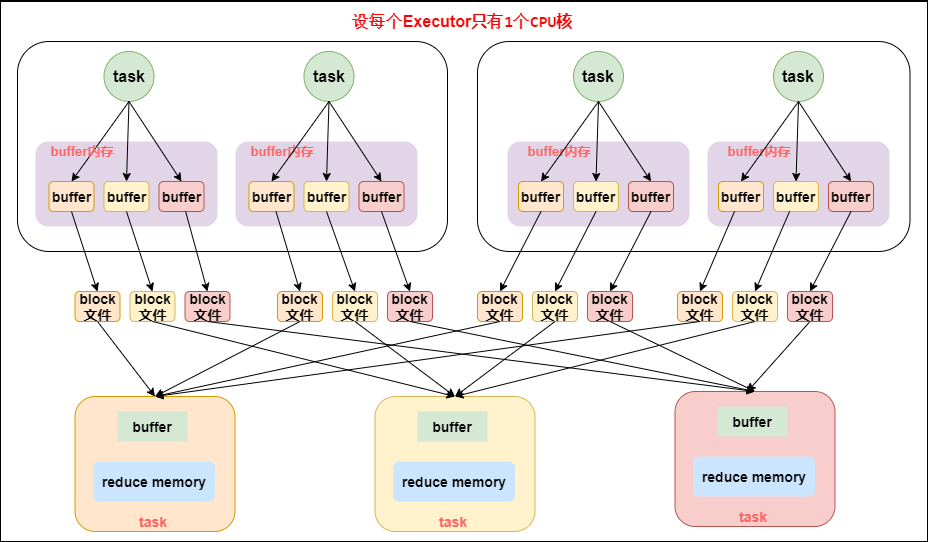
shuffle write阶段主要是为了在当前 stage 阶段结束后,为了下一个 Stage 可以执行 shuffle 类算子(比如 reduceByKey),而将每个 Task 处理的数据按照 key 划分,从而将相同 key 的数据写入到同一个磁盘文件中,每个磁盘文件属于下游 Stage 的一个 Task;- 下一个 Stage 的 Task 有多少个,当前 Stage 的每个 Task 就需要创建多少个磁盘文件。比如下一个 Stage 共有 100个Task,那么当前每个 Task 都需要创建 100个磁盘文件。
shuffle read阶段将上一个 Stage 计算结果中所有相同 Key,从各个节点上的磁盘文件通过网络拉取到当前 Reduce Task 所在的节点上,然后执行 Key 的聚合等操作。由于shuffle write的过程中,map task 给下游 stage 的每个 reduce task 都创建了一个磁盘文件,因此 shuffle read 的过程中,每个 reduce task 只要从上游 stage 的所有 map task 所在节点上,拉取属于自己的那一个磁盘文件即可。
- 设置参数
spark.shuffle.consolidateFiles=true,开启优化机制。 - 出现了
shuffleFileGroup的概念,不再是每个 Task 对应下游多个磁盘文件,而是每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游 stage 的 task 数量是相同的。一个 Executor 上有多少个 cpu 核,就可以并行执行多少个 Task,第一批并行执行的每个 Task 都会创建一个shuffleFileGroup,并将数据写入其中。 - 当 Executor 执行完这一批 Task 后继续执行下一批时,会复用之前的
shuffleFileGroup,包括磁盘文件。consolidate 机制允许不同的 task 复用同一批磁盘文件,这样就可以有效将多个 task 的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write 的性能。
Sort——Shuffle
基于
Hash—Shuffle的实现方式,生成的中间文件个数会依赖于 Reduce 节点的任务个数,即 Reduce 端的并行度,因此文件数仍然不可控,无法真正解决问题。
基于 Sort 的 shuffle 中,每个 Mapper 阶段的 Task 不会为每个 Reduce 阶段的 Task 生成一个单独的文件,而是全部写入到数据文件中,同时生成该数据文件的索引文件,Reduce 阶段各个 Task 可以根据索引文件获取数据。
Sort—Shuffle 避免产生大量文件的直接收益就是降低随机磁盘 I/0 与内存的开销。最终生成的文件个数减少到 2M ,其中 M 表示 Mapper 阶段的 Task 个数,每个 Mapper 阶段的 Task 分别生成两个文件(1 个数据文件、 1 个索引文件),最终的文件个数为 M 个数据文件与 M 个索引文件。因此,最终文件个数是 2M 个。
SortShuffleManager 运行机制主要分为三种:
- 普通运行机制;
- byPass 运行机制,当
shuffle read task数量小于spark.shuffle.sort.bypassMergeThreshold时,启用 byPass 机制; Tungsten Sort机制,需要开启spark.shuffle.manager=tungsten-sort配置。
普通运行机制
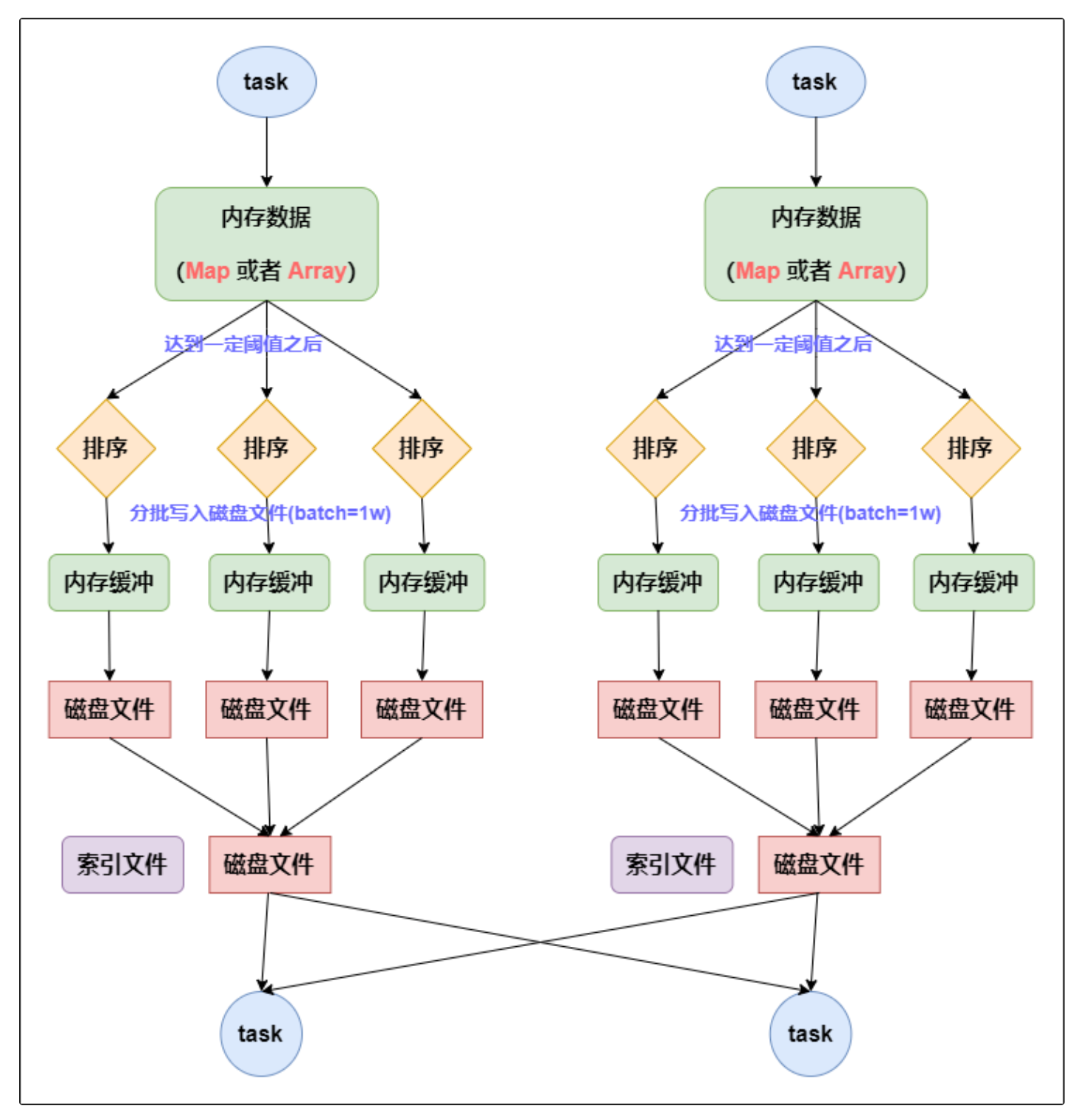
- 数据会先写入内存数据结构中,根据不同的 shuffle 算子选用不同的数据结构,比如
reduceByKey算子对应 Map 数据结构;Join算子对应 Array 数据结构。 - 当内存数据大小达到阈值后,根据 Key 对内存数据排序,然后分批写入磁盘文件。(默认是 10000 条)
- 将之前所有的临时磁盘文件都进行合并,这就是
merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的start offset与end offset。
byPass 运行机制
Reducer 端任务数比较少的情况下,基于
Hash Shuffle机制明显比Sort Shuffle要快,因此产生了 ByPass 机制。
- 每个 Task 会为下游的 Task 创建一个临时文件,然后将 MapTask 结果按照 Key 的哈希值取模放入对应的磁盘文件中。写入磁盘文件时也是先写入内存缓冲区,等达到阈值后再写入。
- 最后将所有临时磁盘文件合并为一个磁盘文件,并创建单独的索引文件。
- 这种机制与未优化的
Hash—Shuffle机制类似,区别在于最后的磁盘文件合并;与普通Sort Shuffle机制也有区别,比如磁盘写机制不同、不会进行排序。
Tungsten Sort运行机制
Tungsten Sort是对普通 Sort 的一种优化,其排序的不是内容本身,而是序列化后的字节数组的指针,把针对数据的排序转变为指针数组的排序,实现直接对序列化后的二进制数据排序。- 这个排序过程没有序列化和反序列化的过程,因此内存消耗大大降低,相应的会极大的减少 GC 的开销。
键值对 RDD分区器
Spark 目前支持 Hash分区、Range分区、自定义分区。
def partition_test(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val pairRdd = sc.makeRDD(List((1,1),(2,2),(3,3)))
println(pairRdd)
val partitionRdd = pairRdd.partitionBy(new HashPartitioner(2))
println(partitionRdd.partitioner)
sc.stop()
}
分区器包括 Hash分区、Ranger分区:
- Hash分区,计算 Key的哈希值并且针对分区个数取余,返回的结果就是该 Key 所属的分区ID;
- Ranger分区,原理是将一定范围内的数映射到某一个分区内,尽量保证每个分区中的数据量保持均匀,并且分区与分区之间是有序的。
- 第一步先从整个 RDD 中随机抽取一定数据样本,将数据样本排序然后计算出每个分区的最大 Key 值,形成一个
Array[KEY]类型的数组变量 rangeBounds; - 判断每个 Key 在 rangeBounds 中所处的范围,给出该 Key 值在下一个 RDD中的分区ID 下标,该分区器要求 RDD中的 Key 类型必须是可以排序的。
- 第一步先从整个 RDD 中随机抽取一定数据样本,将数据样本排序然后计算出每个分区的最大 Key 值,形成一个
RDD 相关案例
案例一:区分数据所在位置
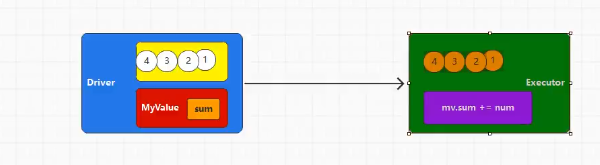
def case001(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(
Array(1,2,3,4,5)
)
// Driver 端数据
val mv = new MyValue()
rdd.foreach(num => {
println(s"num is $num")
// Executor 数据
mv.sum += num
})
// Driver 端数据
println(mv.sum)
sc.stop()
}
上述代码运行打印结果为0,为什么?
- 首先思考,
val mv = new MyValue()中的 mv 对象位于 Driver 端; rdd.foreach(xxx)循环中 mv 对象位于 Executor 端;- Executor 端的操作并不能影响到 Driver 端数据,修改的不是同一份数据。
改用 reduce 算子后就能返回结果,因为算子内部将数据从 Executor 端拉回 Driver 端;
累加器和广播变量
代码中往往不易区分Driver 和 Executor操作,因此二者间数据通信交互比较复杂。由此产生累加器(分布式共享只写变量)、广播变量(分布式共享只读变量)。
累加器
累加器用来将
Executor端变量信息聚合到Driver端。在 Driver 端定义的每个变量,在 Executor 端的每个 Task 都会得到这个变量的一个新的副本,每个 Task 更新这些副本值之后,传回 Driver 端进行合并计算。
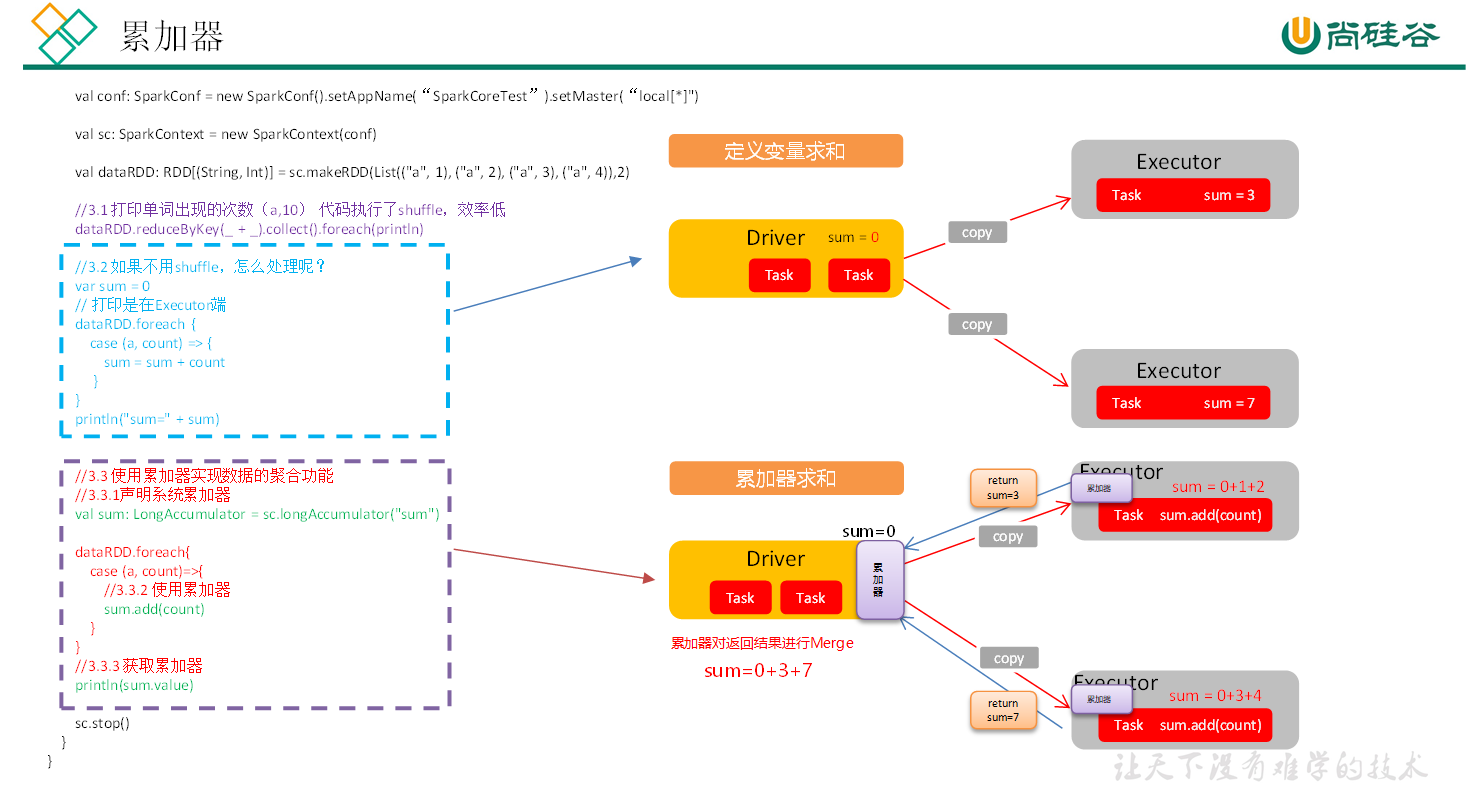
用累加器实现一个 Executor 计算列表之和并传回 Driver 端:
def case002(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(
Array(1, 2, 3, 4, 5)
)
val result = rdd.reduce(_ + _)
println(result)
}
def accumulator01(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRdd = sc.makeRDD(List(("a",1), ("a",2), ("a", 3), ("a", 4)))
// 普通算子实现 value 聚集求和,效率低
val rdd1 = dataRdd.reduceByKey(_ + _)
// 普通变量无法实现,因为普通变量无法从 Driver 端发送回 Executor 端
// var sum = 0
// dataRdd.foreach{
// case (a, count) => {
// sum += count
// println(s"sum = $sum")
// }
// }
// 声明累加器
val accSum = sc.longAccumulator("sum")
// 行动算子中使用累加器
dataRdd.foreach{
case (a, count) => {
// 累加器累加
accSum.add(count)
println(s"sum = ${accSum.value}")
}
}
println(s"a = ${accSum.value}")
sc.stop()
}
注意:
- Executor 端读取的累加器值不一定正确,因为可能存在多个节点同时操作累加器,它是一个分布式共享只写变量。
- 累加器需要放在行动算子(比如
foreach())中执行,如果放在转换算子(比如map()),可能会发生不止一次更新,导致结果错误;
广播变量
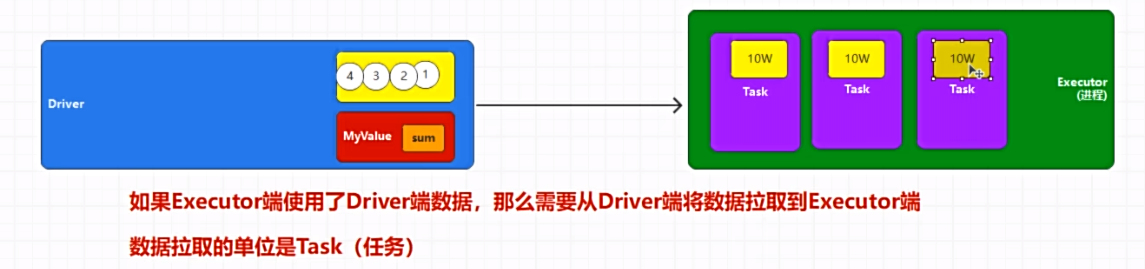
Executor 执行时如果用到 Driver 端声明定义的数据,需要执行前将对应数据拉到 Executor,拉取单位为 Task。
RDD 不能以 Executor 为单位进行数据拉取,也就是说如果 Executor 是多核,那么可以同时执行多个 Task,会造成大量重复数据拉取。
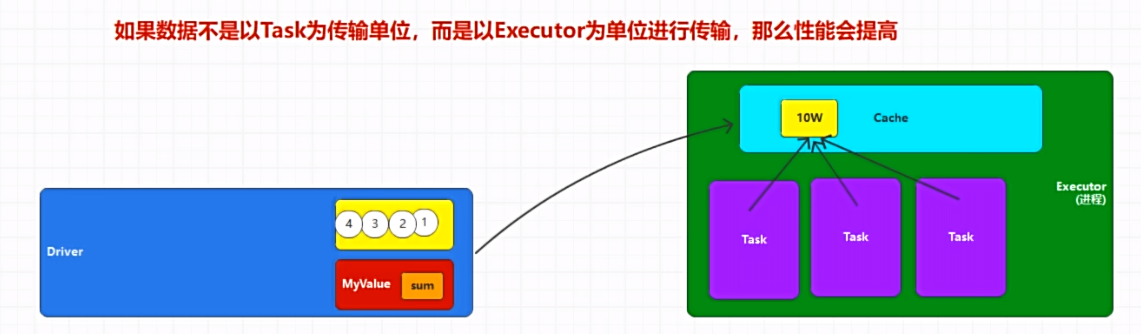
广播变量用来高效分发大对象,向所有工作节点发送一个较大的只读值,以供一个或多个 SparkTask 操作使用。
def broadcast01(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List("WARN:Class Not Find", "INFO:Class Not Find", "DEBUG:Class Not Find"), 4)
val str = "WARN"
// 广播变量
val bdStr = sc.broadcast(str)
val filterRdd = rdd.filter{
// 各个 Executor 访问广播变量值
log => log.contains(bdStr.value)
}
filterRdd.foreach(println)
sc.stop()
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号