01_spark入门
Spark
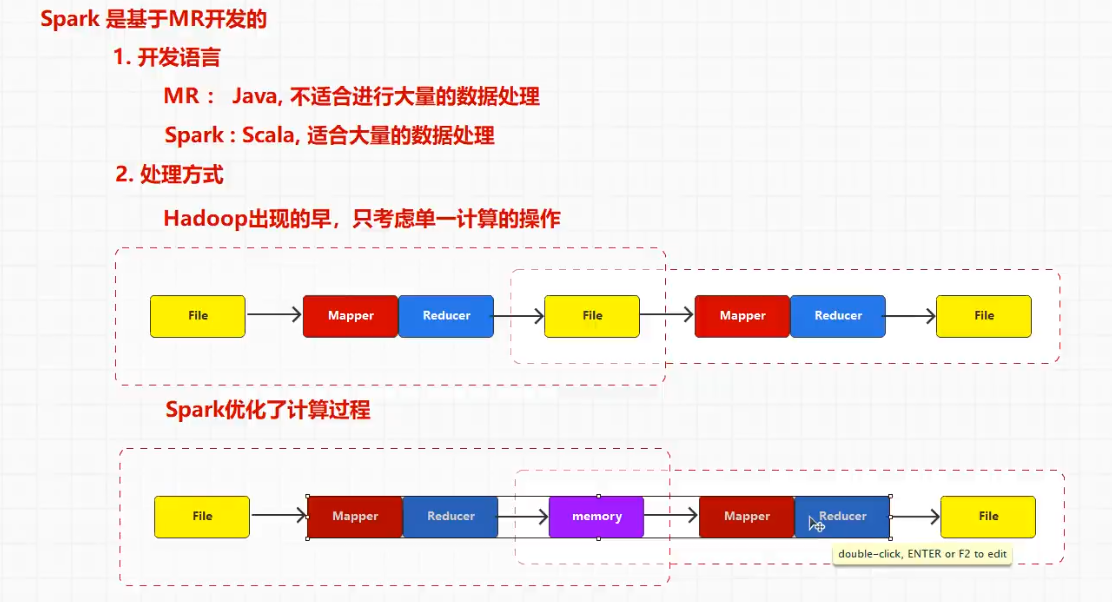
Spark 作为分布式计算框架,基于 MapReduce 框架开发,但是也有以下区别:
- Spark 基于 Scala 语言开发,MR 基于 Java 语言开发;Scala 是函数式编程语言,对于函数间相互调用效率更高;而 Java 是面向对象语言,函数间调用必须依赖于对象,效率低。
- MapReduce 核心是一次性计算,不适合迭代计算,因为中间结果必须存盘,后续步骤依赖于当前中间结果,会造成大量的磁盘IO,导致效率低;Spark 优化了执行逻辑,前一步执行的结果保存到内存而不是磁盘,所以可以提取出重复的步骤,封装成函数。
- Spark 的 RDD(弹性分布式数据集)支持数据的自动缓存,使得重复的数据可以快速访问,无需重新从磁盘读取。
- Spark 和 MapReduce 各有利弊,MapReduce 因为依赖于磁盘所以能够保证程序一定运行完毕,Spark 因为依赖于内存,可能会出现内存溢出等问题。
- 如果旧项目是基于 Hadoop 的,现在需要迁移到 Spark,那么就可以使用
On Yarn模型,基于 Yarn 调度。

为什么 Spark 比 MapReduce 快?
- MapReduce 会分为 Map/Reduce 两个过程,Map 将任务分发到不同节点执行,执行结果先写各自内存,内存溢满后写文件,文件数等于 Reduce 的任务数,Map的结果为
<key,value>格式,对 Key 计算哈希值然后对 ReduceNum 取模得出结果存储到哪个文件;Reduce 任务执行时会从每个 Map 节点拉取对应的文件,先拉取到的文件存入内存,等溢满后合并写磁盘,等拉取所有文件后开始执行。 - Spark 只有在 shuffle 时会存盘,其他操作都是内存操作。
- MapReduce 由 java 语言开发,Java 是面向对象语言,对象间转换需要调用方法,较为复杂;Spark 通过 Scala 开发,Scala 语言支持链式编程,可以将算子设计为一个个函数,链式地调用函数更加方便。
Spark 内置模块:
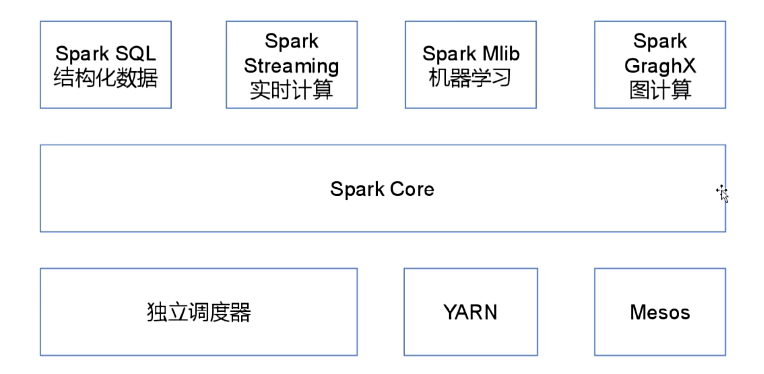
Spark SQL:提供 HQL 与 Spark 进行交互处理的 API,每个数据表当作一个 RDD,Spark SQL 查询被转化为 Spark 操作;Spark Streaming:对实时数据流进行处理和控制;MLib:机器学习算法库;Graphix:控制图、并行图操作和计算的一组算法和工具的集合;Spark Core:底层 RDD API基础库,其他模块都会依赖;
RDD
RDD(Resilient Distributed Datasets,弹性分布式数据集)在 Spark 计算过程中扮演重要的角色。Spark 的计算任务始于 SparkContext 上下文对象,它负责资源的申请、任务的调度以及 RDD 的管理和创建。
RDD 特点
RDD 具有以下特点:
- 每个 RDD 都是只读的,是分布在集群中的只读对象的集合;
- 一个 RDD 由多个 Partition 分区组成,每个分区可能分布在不同节点的内存中;
- RDD 之间可以执行转换操作,转换但是不计算,每次计算后的结果都需要保存为新的 RDD;
RDD 操作
RDD 主要包含了以下两种方法,通过两种方法不断对数据处理保存,最终实现高效、可靠的大数据处理任务:
- 转换算子:
- 将 Scala 集合或者 Hadoop 输入数据构造一个新的 RDD;
- 通过已有的 RDD 产生新的 RDD;
- 惰性执行,只记录转换关系不执行计算;
- 常见操作包括
map、filter、flatmap、union、distinct、sortbykey;
- 动作算子:
- 通过 RDD 计算得到新的一组值;
- 触发真正的计算;
- 常见操作包括
first、count、collect、foreach、saveAsTextFile等;
比如 rdd.map(_+1).saveAsTextFile("hdfs://node01:9000") 操作,map 对应转换,saveAsTextFile 对应计算。
RDD 依赖
RDD 中区分宽窄依赖,因为宽依赖回复起来速度很慢。
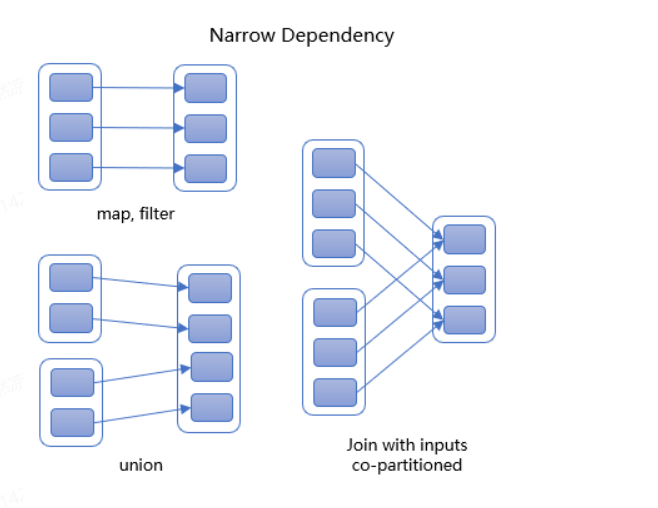
窄依赖:
- 父 RDD 中分区最多被一个子 RDD 分区使用;
- 子 RDD 如果部分分区数据丢失或损坏,只需要从父 RDD 重新计算恢复;
- 窄依赖可以并行地生成子 RDD 的分区,使得任务可以在多个节点上并行执行;
- 常见操作如
map、filter、union、sample
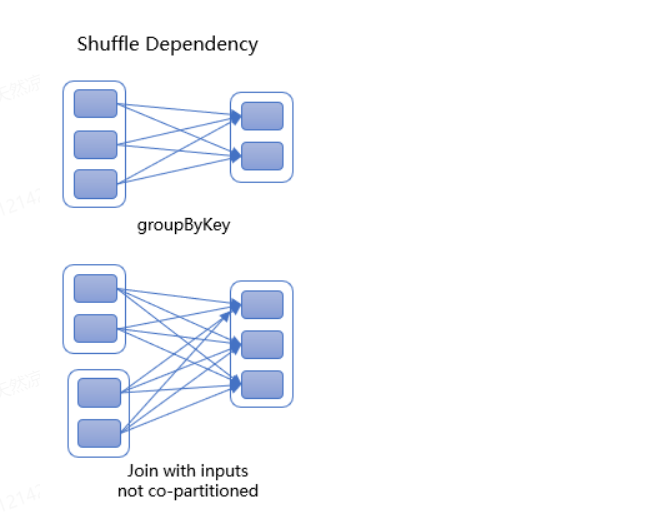
宽依赖:
- 主要发生在需要跨分区的数据重组或者聚合操作;
- 父RDD的分区被多个子RDD的分区依赖;
- 子 RDD 如果部分或者全部分区数据丢失或损坏,必须从所有父 RDD 分区重新计算;
- 宽依赖一定会导致 shuffle,数据需要重新分配到不同的分区,涉及到大量的数据移动和 IO 操作,执行宽依赖时性能可能会受到影响;
- 例如:
sort、groupByKey、reduceByKey、sortByKey、join、rePartition;
RDD 的创建
RDD 有三种创建方式:
- 从集合创建 RDD;
- 从文件系统创建 RDD;
- 从RDD 上创建 RDD;
- 从外部数据源读取;
// 从集合创建RDD
// 1.创建 sc 的配置对象
val conf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2.创建 sc 对象
val sc = new SparkContext(conf)
// 3.从集合创建RDD
val list = List(1,2,3,4)
val intRDD = sc.parallelize(list)
intRDD.collect().foreach(println)
val intRDD1 = sc.makeRDD(list)
intRDD1.collect().foreach(println)
intRDD.saveAsTextFile("output")
sc.stop()
// 从本地文件创建 RDD
val conf:SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]");
val sc = new SparkContext(conf)
val lineRDD = sc.textFile("input/1.txt")
lineRDD.collect().foreach(println)
sc.stop()
数据源表:
create table emp(
id int(11),
ename varchar(20),
deptno int(11),
sal int(11));
insert into emp values(1,"Tom",10,2500);
insert into emp values(2,"Movle",11,1000);
insert into emp values(2,"Mike",10,1500);
insert into emp values(2,"jack",11,500);
基于单机 MySQL 数据源创建 RDD,性能受限于 MySQL 的连接数:
def method04(): Unit = {
// 准备连接驱动
val connection = () => {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8", "root", "root")
}
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
// 建立连接
val mysqlRdd = new JdbcRDD(sc, connection, "select * from emp where sal > ? and sal <= ?", 900, 2000, 2, r=>{
val ename = r.getString(2)
val sal = r.getInt(4)
(ename, sal)
})
val result = mysqlRdd.collect()
println(result.toBuffer)
sc.stop()
}
基于分布式数据库 HBase 创建 RDD:
待补充.....
如果是本地模式 local[xxx] 会指定 RDD 的分区数量,这里看一下 parallelize(xxx) 源码实现:
parallelize(xxx, xxx) 接收两个参数,分别是集合类型、int类型的分区数,默认为 defaultParallelism,该类型是一个函数,函数返回值为Int。

// 默认分区数接口库
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
// 接口抽象类
def defaultParallelism(): Int
// 最终默认值取值
def defaultParallelism(): Int = {
// 这里的 conf 对应 SparkConf,也就是开始创建时传入的配置
scheduler.conf.getInt("spark.default.parallelism", totalCores)
}
RDD 分区数计算规则
Spark 分区数计算规则区分基于内存数据源、文件数据源:
综上在生成 RDD 时,基于集合生成 RDD 时,如果分区数需要手动设置,其解析规则如下:
- 优先使用方法
parallelism(xxx, xxx)参数; - 使用 Conf 配置参数,
spark.default.parallelism; - 采用环境默认值,如
local[*];
基于文件生成 RDD时,其解析规则如下:
textFile(xxx, xxx)第二个参数指定minPartitions,注意这里指定的是最小分区数,实际分区数可能会大于该值;实际开发中用 总文件大小/最小分区数,对结果向上取整。- 取 Conf 配置参数和 2的最小值,
minPartitions = Math.min(minPartitions, 2); - 采用环境默认总值和 2的较小值;
RDD 分区数据的分配
基于内存数据源的数据分配方式:
- 首先计算出分区数,然后根据分区数的索引编号(从0开始到n-1),每次计算当前分区存储的数据个数
(i*length)/numSlices, (i+1)*length/numSlices; - 比如总共6个数据,分区数为4,此时的数据分配情况:
- 0 => (06)/4, (16)/4 => (0,1) => 1;
- 1 => (16)/4, (26)/4 => (1,3) => 2;
- 2 => (26)/4, (36)/4 => (3,4) => 1;
- 3 => (36)/4, (46)/4 => (4,6) => 2;
基于文件数据源的数据分配方式:
- Hadoop 进行文件切片数据量计算时考虑的是尽可能地平均,按字节计算;
- 分区数量的存储考虑的是业务数据的完整性,是按照行读取的;
- 读取数据时,还需要考虑数据的偏移量,偏移量从 0 开始;
- 读取数据时,相同的偏移量不能重复读取。

举个例子
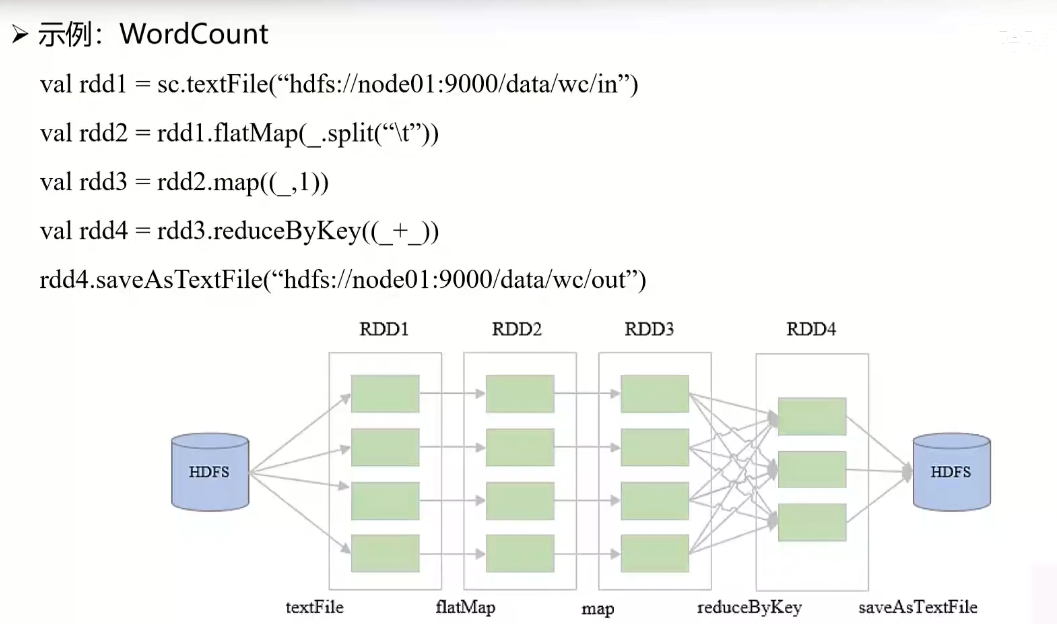
- 首先通过
SparkContext上下文对象加载 HDFS 某个目录下的文件; - 针对每一行数据按照分表符切分成多个单词,得到新的单词集合;
- 对每个单词执行 map 处理,具体就是标记次数为 1;
- 按照 Key 值执行 Reduce 处理,将 Key 相同的所有 Value 累加求和;(代码中的
_是 Scala 语法中的占位符) - 将最终结果保存到 HDFS 下的文件目录。
由于每个阶段都会保存新的 RDD,所以如果某阶段计算失败,就可以利用上一个步骤的 RDD 结果重新执行计算,而不需要从源头开始计算。
Spark 程序
程序架构
Spark 也是主从架构,包含管理节点 Master、工作节点 Worker。
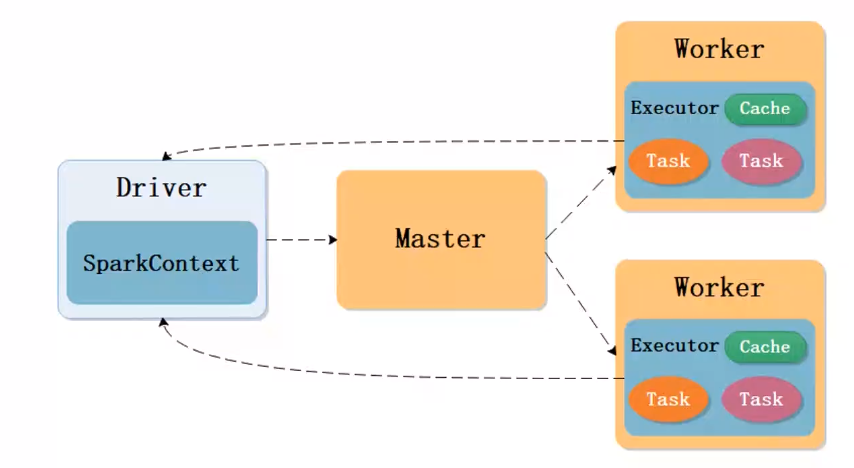
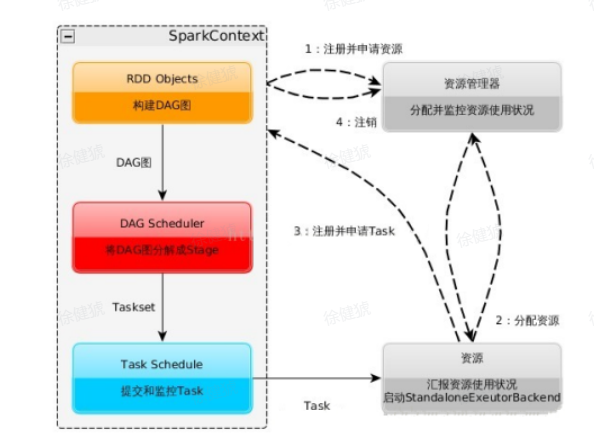
- 构建运行环境,Driver 创建
SparkContext上下文; - SparkContext 向资源管理器(standalone、Mesos、Yarn)申请
Executor资源,资源管理器启动StandaloneExecutorBackend; - Executor 向
SparkContext申请 Task; - RDD 对象构建成 DAG 图,
DAG Scheduler将 DAG图解析为 Stage,每个 Stage 对应一个 TaskSet,然后将其发送给TaskScheduler,由TaskScheduler调度发送给 Executor 运行; - Task 在
Executor运行完毕后释放资源;
Spark 作业运行模式
Local 模式:
Spark 应用以多线程方式运行在本地,方便调试。
- local:启动一个 Executor;
- local[k]:启动 k 个 Executor;
- local[*]:启动 CPU 核数个 Executor;
standalone 模式:
分布式集群运行,不依赖于第三方资源管理系统(Yarn、Mesos等)。
- 采用 Master-Slave 结构;
- Driver 运行于 worker,Master 只负责集群管理;
- Driver 向 Master 申请作业运行所需资源,Master 分配 Executor 给 Driver;
- Driver 将解析后的 Task 调度到 Executor 上运行,并且不间断监听运行情况,汇报给 Master;
- 整体架构类似于 Yarn,其中
Master——ResourceManager、Driver——Container、Executor——ApplicationMaster; - 为了避免 Master 单点故障,由 Zookeeper 负责 Master 节点集群高可用。
Spark On Yarn:
分布式部署集群、资源、任务监控由 Yarn 管理,目前仅支持粗粒度资源分配方式。
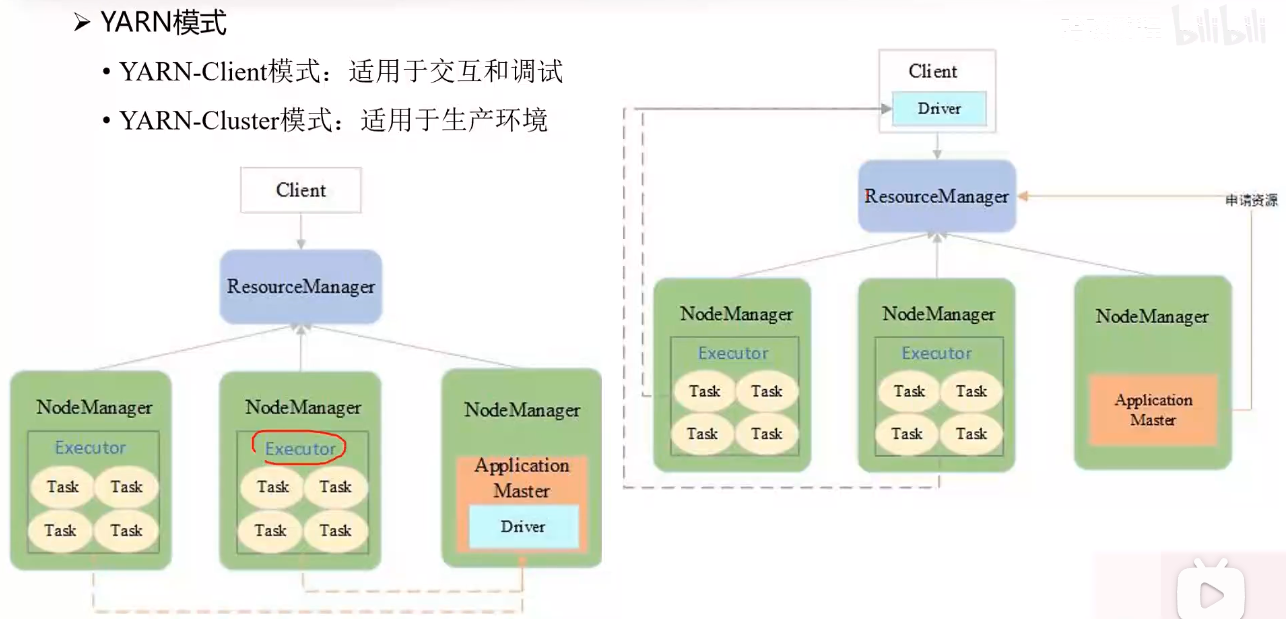
这种模式的工作流程:
Driver解析 Spark 数据生成一定量的 Task,然后需要开始申请Hadoop资源;- 但是 Dirver 无法申请,需要借助
ApplicationMaster申请,所以在 Driver 外部套用一个 ApplicationMaster 用作资源申请; - ApplicationMaster 通过向 ResourceManager 申请 Container 资源,到手后通知 Driver;
- Driver 将解析好的作业分发到 Container 节点上运行。
Yarn 包括 Yarn-Client(适用于交互和调试)、Yarn-Cluster(适用于生产环境)两种模式。
程序执行及底层逻辑
生成逻辑执行计划
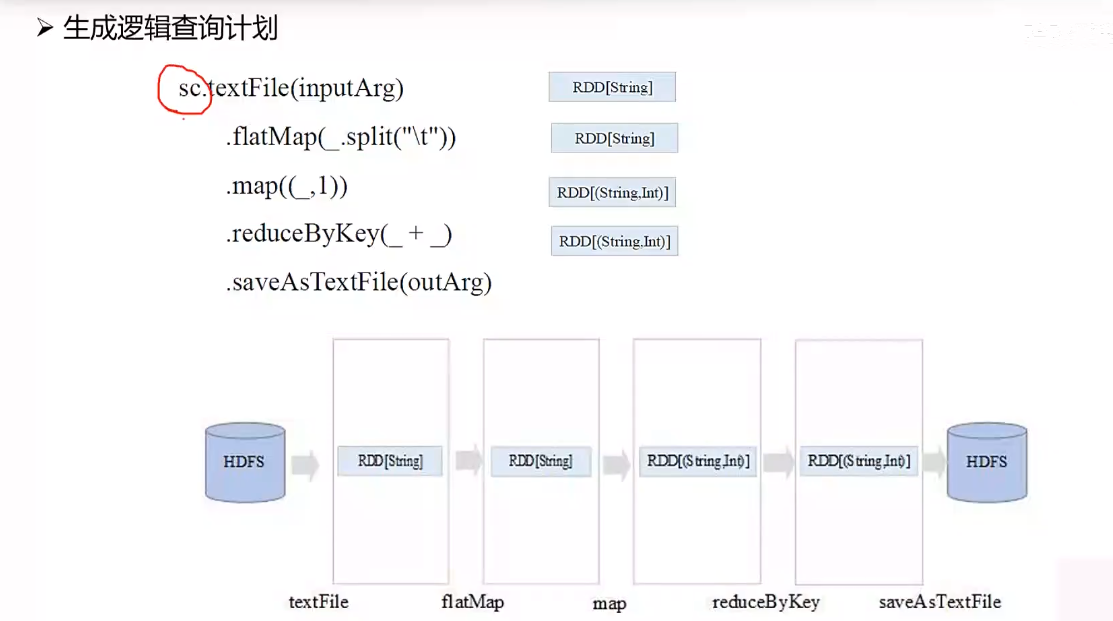
通过 Scala 语言编写 Spark 逻辑查询计划:
sc.textFile(inputArg)
.flatMap(_.split("\t"))
.map((_,1))
.reduceByKey(_+_)
.saveAsTextFile(outArg)
上述是一个 WordCount 程序的逻辑执行计划,每个阶段会生成一个单独的 RDD。
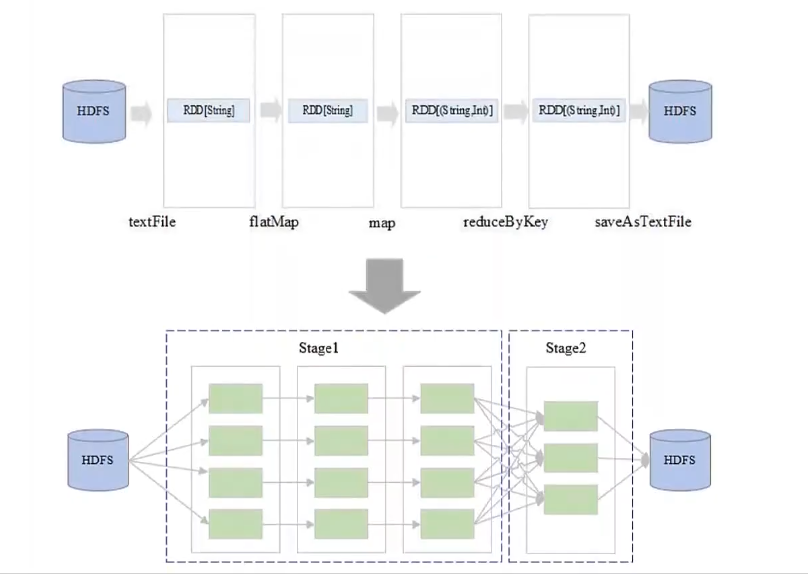
生成物理执行计划
物理查询计划关注于底层数据状态:
- 如图一个 RDD 有 4个 Partition,那么前三个 RDD 步骤作用于 RDD 迭代变换;这三个步骤可以划分到一个 Stage,因为可以多个分区并行执行(生成 4 个任务分别调度到不同计算节点);
- 接着第四个 RDD 步骤需要进行 shuffle,所以需要单独划分 Stage(可以生成 3个任务调度到不同计算节点上运行);
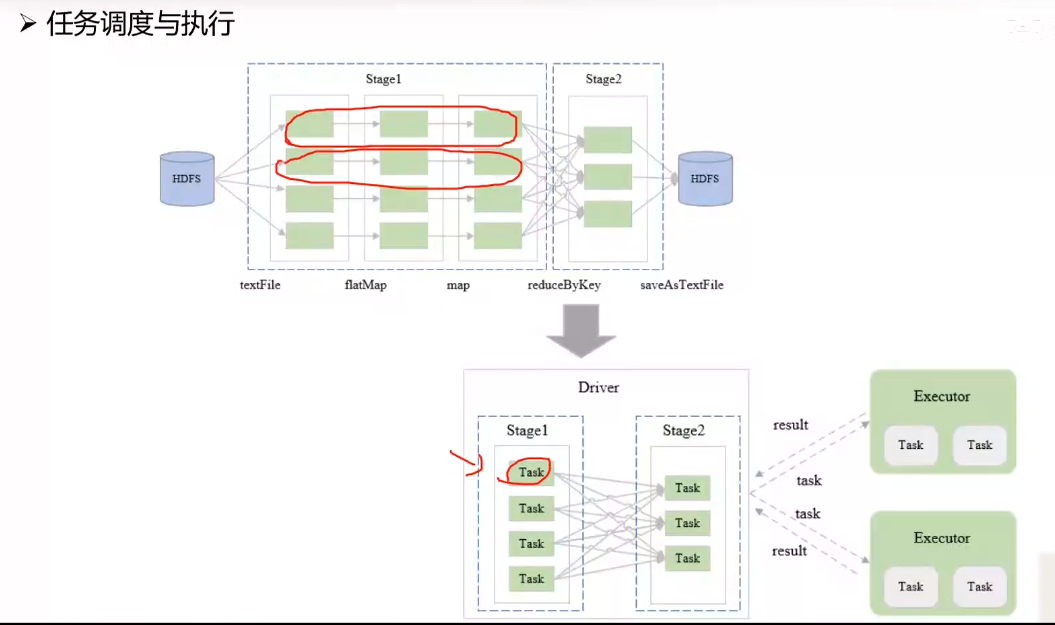
任务调度与执行
将各个阶段生成的 Task 调度到 Executor 上运行,执行过程中会不停向 Driver 汇报进度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号