hadoop04_MapReduce
MapReduce 模型
MapReduce 核心思想是移动任务而非移动数据
MapReduce 是一种编程模型,对数据集执行 MAP 映射,然后对结果进行 Reduce 规约,适用于大规模数据集的并行计算。核心思想可以理解为分治法,数据固定不动,分派计算任务到不同计算节点计算。
模型介绍
MapReduce 适用场景:
- 离线处理,比如数据统计,网站 PV、UV 的统计;
- 搜索引擎构建索引,例如搜索引擎需要对底层数据建立索引,然后才能高效快速查询;
- 海量数据查询;
- 复杂数据分析算法的实现。
不适用的场景:
- OLAP:在线分析场景,要求毫秒或者秒级返回结果;因为 MapReduce 是通过依赖磁盘交互从而减少内存使用,所以无法及时返回计算结果。
- 流式计算:输入的数据集是流动的,而 MapReduce 是固定的;
- DAG计算:有向无环图的任务计算,后续任务需要依赖前面任务的执行结果,但是 MapReduce 中每个作业的执行结果都需要落盘,落盘后再读取然后网络传输给后续节点,这产生大量磁盘IO,性能低下。DAG计算更适用于 Spark框架,因为 Spark 是基于内存的,计算结果无需落盘就可以传输给下一个对象。
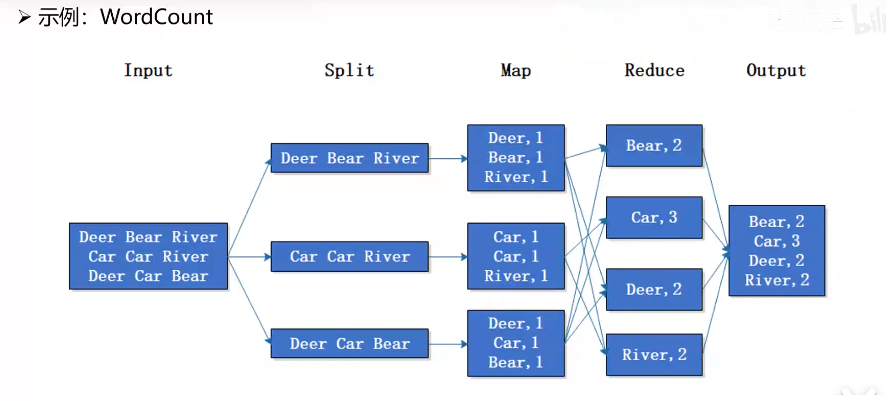
示例
举个例子词频统计,输入为多个文件,MapReduce 过程如下:
- 对输入进行拆分,如果文件存储在 HDFS 已经自动完成了切分,否则按照每 128MB 大小切分;
- 对每个数据块启动一个 Map 任务,任务会按照空格对字符串进行切分,统计每个词汇的出现次数;
- 对每个词汇名做哈希计算(shuffer),同名的词汇名与其对应结果会发送到相同的 Reduce节点上,待所有结果建立完映射,开始执行 Reduce任务;
- Reduce 任务即统计当前词汇的出现频率,最后合并所有结果输出。
所以我们得出一般场景下 MapReduce 的执行流程:
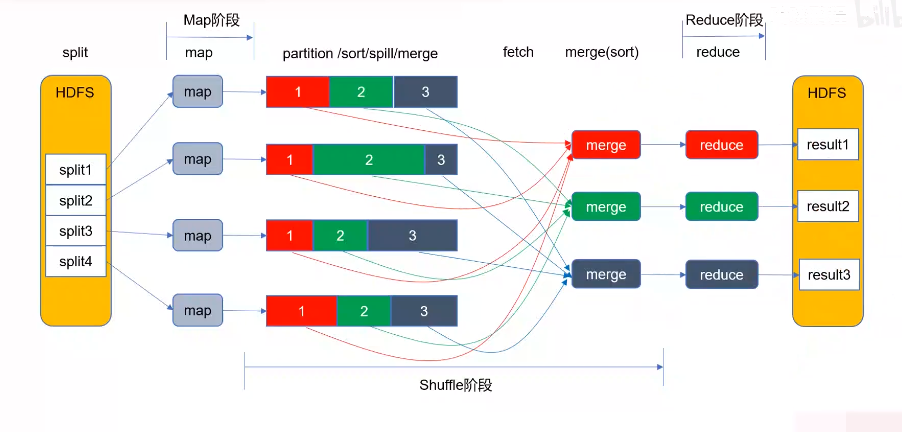
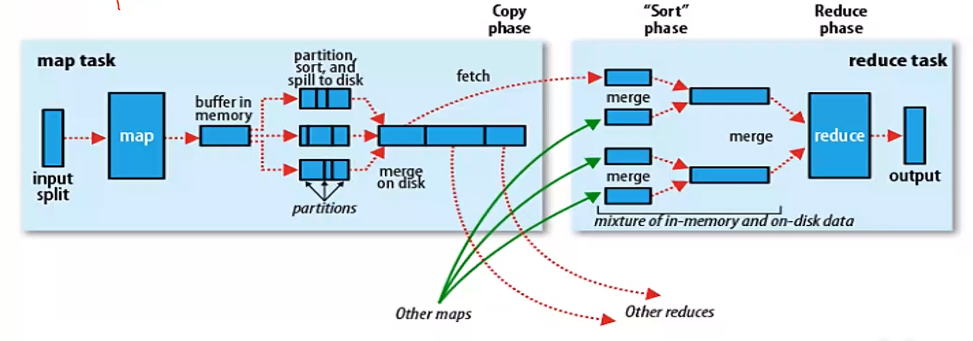
- 数据首先存储到 HDFS 中,HDFS 会自动对数据进行拆分为固定大小的块,对每个块启动一个 Map 任务;
- MapReduce 执行之前根据配置来进一步细分或者合并 Block 块来增加或者减少 Map 的数量。接着对每个数据块执行 Map 任务,输出的结果(<Key,Value> 格式)保存到内存缓冲区上(上限为100MB),当内存容量超过 80% 时执行溢写操作,tong
- 溢写包括分组排序,分组指按照 Reduce 数目对数据进行分组哈希取模排序,生成多个小文件;
- 为了方便传输,合并多个小文件为大的分组有序的文件,等待 Reduce 任务拉取;
- Reduce节点通过 fetch 线程从各个 Map节点拉取指定结果,拉取的数据先保存到缓冲区中。当大小超过阈值后执行溢写操作,溢写会生成多个小文件。然后合并多个小文件结果为一个大文件。
- 生成大文件时也需要进行分组排序,分组是指将 Key 相同的分到同一组,然后排序;
- 接着对分组有序的文件执行 Reduce 处理,每个任务最终会输出一个计算结果;合并所有计算结果,保存到 HDFS 中。
综上,MapReduce 整个过程中涉及到大量磁盘IO操作、大量网络IO操作、少量的内存操作:
- 少量内存操作:执行完 Map 任务结果输出到内存缓冲区;fetch线程拉取 Map结果后先保存到内存缓冲区;
- 大量磁盘IO操作:Map 阶段内存缓冲区超过阈值时执行溢写,分组排序落盘;Reduce 执行结果落盘。
- 大量网络IO操作:Map结果需要通过网络才能传输至Reduce节点,这个过程大量数据需要大量网络传输。
源码分析
Job 任务提交
// Job.java
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
// 任务状态检查
ensureState(JobState.DEFINE);
// 解决 Hadoop 新旧版本冲突
setUseNewAPI();
// 建立连接,远程Yarn客户端或者本地客户端
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
// 核心提交任务流程
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
submitJobInternal(Job job, Cluster cluster) 方法主要执行以下步骤:
- 检查输入文件、输出目录,如果存在输出目录报错;
- 创建给集群提交任务的文件目录
Stag,提交文件时会在目录下创建以任务名为目录名的子目录,然后初始化任务执行信息、配置; - 拷贝任务 jar 包到远程集群目录,如果是本地则无需拷贝;
- 计算切片信息,生成切片规划文件;
- 向
Stag目录中写入 XML 配置文件(job.xml),该文件内容为该任务运行所需的参数配置,然后客户端向远程集群提交任务信息; - 提交任务,返回提交结果状态。
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
// 创建给集群提交任务的目录
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 生成当前唯一任务ID
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 给当前任务生成提交用的目录
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
// 拷贝任务Jar包等文件到远程集群
copyAndConfigureFiles(job, submitJobDir);
// 计算切片,生成切片规划文件
int maps = writeSplits(job, submitJobDir);
// 向任务目录中写入任务XML执行配置文件
writeConf(conf, submitJobFile);
// 提交任务
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
}
分词案例实操
- 实现分词 Map、Reduce 过程,分别实现 Mapper、Reducer 接口;
- Map 过程,输入类型(key:Object、Value:IntWritable),输出类型(key:Text、Value:IntWritable);
- 配置生成任务所需的核心配置,创建作业并运行。
public class WordCount {
/**
* Mapper
* 接收的是文件,会读取文件的每一行,所以这里设置为 LongWritable/Object,Value 为这一行的文件内容
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable vOut = new IntWritable(1);
private Text kOut = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
while (stringTokenizer.hasMoreTokens()) {
String word = stringTokenizer.nextToken();
kOut.set(word);
context.write(kOut, vOut);
}
}
}
/**
* Reducer
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final static IntWritable vOut = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
vOut.set(sum);
context.write(key, vOut);
}
}
public static void main(String[] args) throws Exception {
// 初始化Job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
// 配置 Mapper/Reducer 实现类
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
// 配置结果输出类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 配置结果输入和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 运行作业,等待结束
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
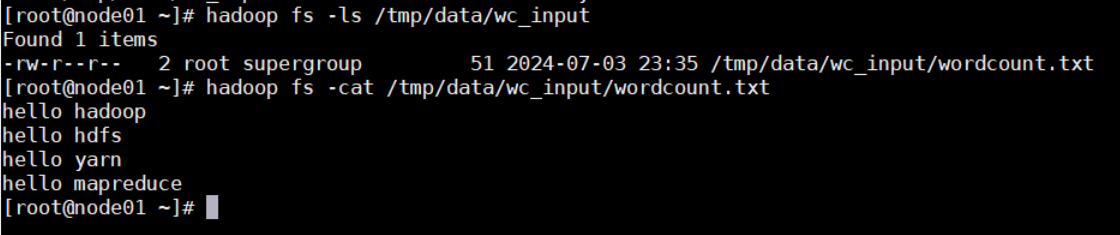
- 上传本地输入文件到 hdfs
# hdfs创建目录并赋予权限
hadoop fs -mkdir -p /tmp/data/wc_input
hadoop fs -chmod 777 /tmp/data/wc_input
# 本地创建词频文件并上传到 hdfs
echo -e "hello hadoop\nhello hdfs\nhello yarn\nhello mapreduce" > wordcount.txt
hadoop fs -put wordcount.txt /tmp/data/wc_input
- 本地 IDEA 打包为
wc.jar包并上传 linux; - 执行 hadoop 程序:
# 命令格式:hadoop jar xxx.jar 主类名(绝对路径) hdfs输出路径
hadoop jar wc.jar WordCount com.xjx.demo.WordCount /tmp/data/wc_output
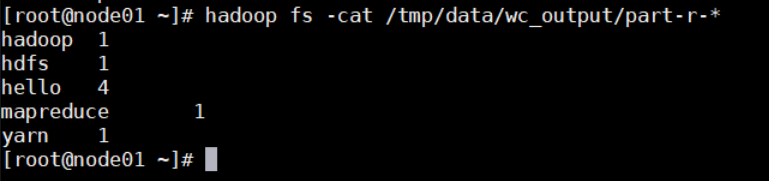
- 查看 hdfs 输出路径结果
hadoop fs -cat /tmp/data/wc_output/part-r-*

 浙公网安备 33010602011771号
浙公网安备 33010602011771号