hadoop02_HDFS
HDFS
HDFS全称Hadoop Distributed File System,Hadoop分布式文件系统。
HDFS 有以下缺点:
- 不适合低延迟的数据访问,因为数据存储到 HDFS 上,首先会切分为固定大小的数据块,然后对每块存储并进行多副本备份。读取数据时首先要从各个节点读取小数据块然后合并为大数据块,整体延迟较大;
- 不适合小文件存储,因为 NameNode 需要保存元数据,小文件越多导致元数据越多,所以会占用大量的 NameNode 空间;
- 不支持并发写入,仅支持追加,因为集群中随机进行文件修改,会造成多副本情况下的大负载。
HDFS 常见命令
# 启动 HDFS 集群
start-dfs.sh
# 查看命令帮助
hdfs dfs
hdfs dfs -help put
# 在 HDFS 上创建目录
hdfs dfs -mkdir -p /training/hdfs_data
# 修改指定目录权限
hadoop fs -chmod -R 777 /training/hdfs_data
# 本地创建文件,并上传至 HDFS 指定目录
echo "Hello Hadoop File System" > file01
hdfs dfs -put file01 /training/hdfs_data
# 查看 HDFS 目录下文件夹的内容
hdfs dfs -ls /training/hdfs_data
# 查看 HDFS 文件内容
hdfs dfs -cat /training/hdfs_data/file01
# 下载 HDFS 中的文件到本地,并改名为 file02
hdfs dfs -get /training/hdfs_data/file01 file02
HDFS 架构
Hadoop Distribute fileSystem 作为分布式文件系统存储,用来管理大数据场景下数据的存储、读写等操作。
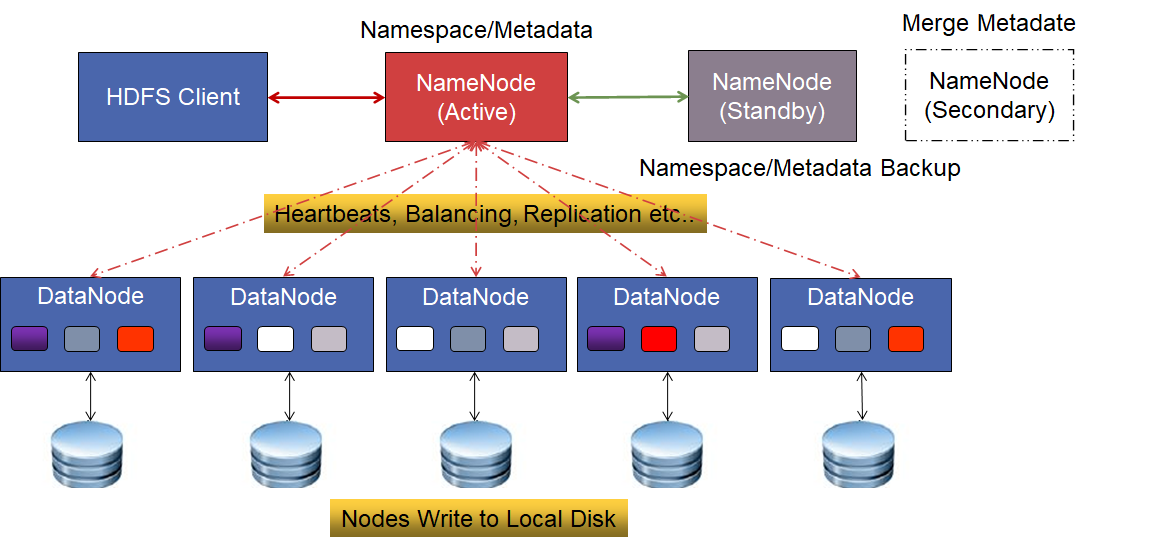
HDFS 主要由以下部件组成:
NameNode:存储系统的管理核心,分为 Active、Standby,二者互为热备节点,其中备节点至少存在一个。- 管理文件系统命名空间的主服务器;
- 管理客户端对文件系统的访问,如打开、读取、写入、重命名等操作;
- 管理文件、目录、block 间的对应关系,比如输入的文件被拆分为哪些 Block 块、文件基本信息;但是不会存储 Block块的位置信息,因为 DataNode 会经常出现宕机,如果保存位置信息到磁盘会触发大量修改。
- 内部维护目录树
FileSystemImage、日志记录Edits; - NameNode 做出有关块复制的所有决策。它定期从集群中的每个 DataNode 接收 Heartbeat 和 Blockreport。接收到检测信号意味着 DataNode 运行正常。Blockreport 包含 DataNode 上所有块的列表。
Secondary NameNode:注意不是热备节点,只是用于辅助 NameNode 的工作,比如及时更新 FsImage 并持久化磁盘;DataNode:管理数据存储的节点,作为 HDFS 最小的存储节点:- 连接到具体的存储节点;
- 负责处理来自文件系统客户端的读写、删除等请求。
- Block 默认大小 128MB,数据在存储时会进行多副本备份;
NameNode
数据复制
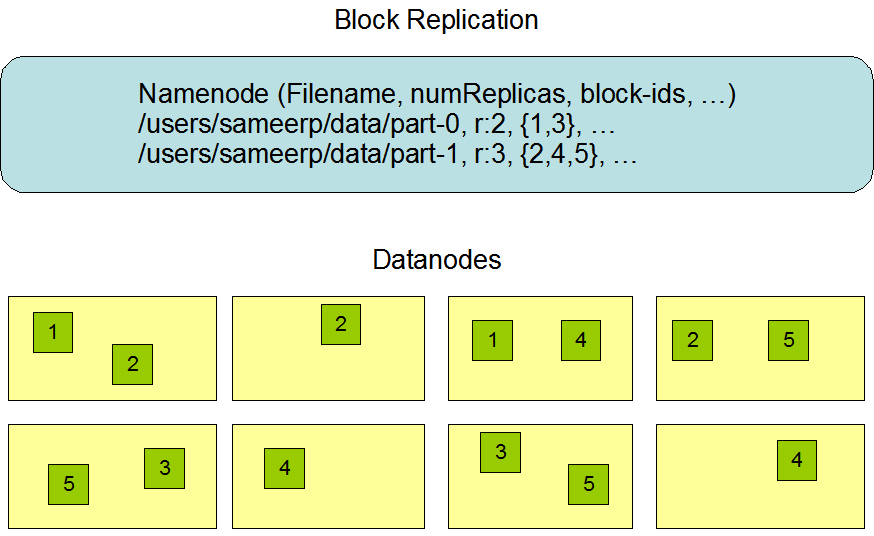
对于常见情况,当复制因子为 3 时,HDFS 的放置策略是,如果写入器位于数据节点上,则将一个副本放在本地计算机上,否则将一个副本放在与写入器位于同一机架的随机数据节点上,将另一个副本放在不同(远程)机架中的节点上,最后一个副本放在同一远程机架中的不同节点上。此策略可减少机架间写入流量,从而提高写入性能。机架故障的几率远小于节点故障的几率;本策略不会影响数据的可靠性和可用性保证。但是,它不会减少读取数据时使用的聚合网络带宽,因为一个块仅放置在两个唯一的机架中,而不是三个。使用此策略时,块的副本不会均匀分布在机架上。两个副本位于一个机架的不同节点上,其余副本位于另一个机架的节点上。此策略可在不影响数据可靠性或读取性能的情况下提高写入性能。
若复制因子大于3,则随机确定第4个及后续副本的位置,同时将每个机架的副本数保持在上限以下 (replicas - 1) / racks + 2。
持久性和高可用性
HDFS 命名空间由 NameNode 存储。NameNode 使用名为 EditLog 的事务日志来永久记录文件系统元数据发生的每个更改。例如,在 HDFS 中创建新文件会导致 NameNode 在 EditLog 中插入一条记录,以指示这一点。同样,更改文件的复制因子会导致将新记录插入到 EditLog 中。NameNode 使用其本地主机操作系统文件系统中的文件来存储 EditLog。整个文件系统命名空间(包括块到文件和文件系统属性的映射)都存储在名为 FsImage 的文件中。FsImage 也作为文件存储在 NameNode 的本地文件系统中。
NameNode 作为核心管理者,需要保证高可用性,如果发生宕机则需要保证高可用性,HDFS 提供了以下两种容错机制。
机制一:检查点+SecondaryNameNode
当 NameNode 启动或者由可配置阈值触发检查点时,从磁盘读取 FsImage、EditLog 并将 EditLog 的所有事务应用于 FsImage 的内存数据,接着将此新版本刷新到磁盘上的新 FsImage 中。此时可以截断旧 EditLog,因为它的事务已应用于持久性的 FsImage,这个过程叫做 checkpoint,通过生成文件系统元数据快照并将其保存到 FsImage 来确保具有唯一的文件系统元数据视图。checkpoint 期间对数据节点的操作直接作用于 FsImage。
非 checkpoint 期间对 DataNode 的操作都被记录在 EditLog,而并不直接作用于 FsImage。通过指定间隔时间 dfs.namenode.checkpoint.period 或者指定累计次数的操作 dfs.namenode.checkpoint.txns 之后,触发 checkpoint 过程。
上述操作有一些缺点,如果 EditLog 很大会导致开机启动耗时过长,而且每隔一定时间进行一次 checkpoint 对 NameNode 性能影响很大。所以就有了 SecondaryNameNode,可以看作 NameNode 的助理。
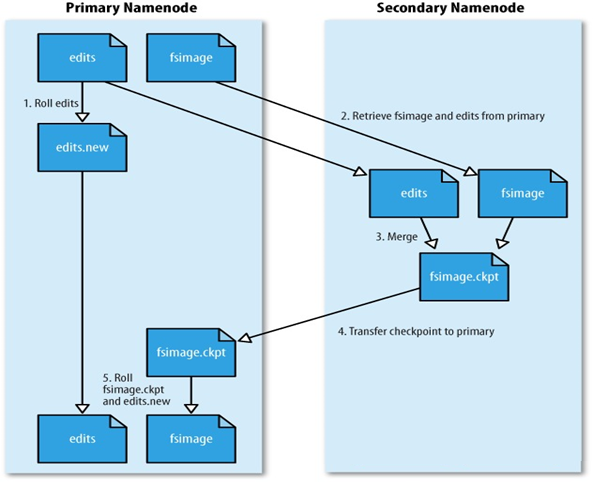
SecondaryNameNode 主要负责下载 NameNode 的 FsImage、EditLog 文件并合并生成新的 FsImage 文件,再推送给 NameNode,其工作过程如下:
- SecondaryNameNode 主动请求 NameNode 停止使用 EditLog,暂时将新的操作记录到新文件中;
- SecondaryNameNode 通过 http 从 NameNode 获取 FsImage、EditLog;
- SecondaryNameNdoe 将 FsImage 文件载入内存并逐一执行 EditLog 的事务操作,以此创建新的 FsImage;
- SecondaryNameNode 通过 http 将新的 FsImage 发送回 NameNode;
- NameNode 用接收到的文件替换旧文件,并用步骤一的新文件代替 EditLog,同时更新 fstime 来记录
checkpoint执行时间; - 最终 NameNode 拥有一个更小的 FsImage、EditLog 而没有过多性能影响。
机制二:
两种高可用方案 QJM(Quorum Journal Manager)、NFS(共享存储)。
这里先介绍基于 QJM 的高可用方案,核心思想就是在 HDFS 集群中维护多个 NameNode 节点。可是提供多个 NameNode 又产生了新问题:
- 如何保证各个 NameNode 的元数据一致性;
- 客户端如何决定访问正确的 NameNode;
- 怎么保证任意时刻只有一个 NameNode 对外提供服务状态(避免脑裂)。
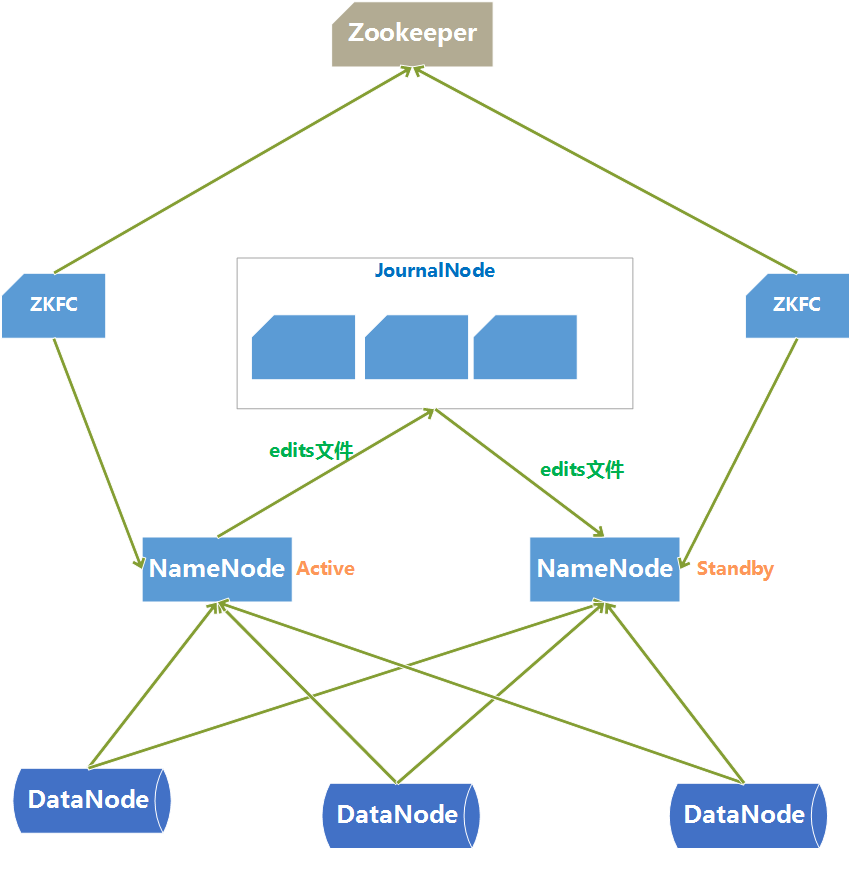
HDFS 集群中两台 NameNode 节点,一台处于活动状态(Active)对客户端提供服务,另一台处于热备份状态(Standby)。
为了保证 Active/Standby 节点数据的同步性,两个节点都需要和一些独立节点保持通信来同步数据,这些节点称为 JournalNode。
首先需要保证两个 NameNode 命名空间的一致性:
- Active NameNode 定期将修改命名空间、删除备份块等操作记录到 EditLog,同时记录到 JournalNode 的 EditLog;
- StandBy NameNode 会一直监听 JournalNode 上 EditLog 的变化,如果 EditLog 发生改动,StandBy NameNode 就会读取 EditLog 并与本地命名空间合并;
- Active NameNode 出现故障时,StandBy NameNode 会保证已经从 JournalNode 上读取了所有 EditLog 并与命名空间合并,此时才能切换到 Active NameNode。
- JournalNode 基于 Paxos 算法实现高可用,因此需要保证至少 3个节点,因为编辑日志修改必须写入大多数 JournalNode,这可以容许1个节点的故障。
- JournalNode 不会因为其中一个机器的延迟而影响整体,而且不会因为 JournalNode 数量的增多而影响性能,因为 NameNode 并行地向所有 JournalNode 发送数据。
同时需要保证两个 NameNode 数据块存储信息的一致性:
- 为了使故障切换能够尽快实现,需要保证 Standby NameNode 也实时保存了数据块的存储信息。
- DataNode 会同时向两个 NameNode 发送心跳以及数据块的存储信息。
如何进行故障检测,以及确定故障 NameNode 后如何切换到 StandBy NameNode?
- 集群中每个 NameNode 都会在 Zookeeper 中维护一个持久会话(
FailoverController),如果机器出现了崩溃,Zookeeper 会话将过期,此时通知其他 NameNode 应该触发故障转移。 - 当发生故障时如何进行主备切换,是通过 Zookeeper 分布式锁实现的,Zookeeper 为 HDFS 创建一个选举用的目录,所有 NameNode 都来竞争该锁,竞争成功则为 Active,否则为 StandBy。
ZKFC(ZKFailoverController) 是一个新组件,负责监控和管理每个 NameNode 的状态,运行 NameNode 的每台机器也运行 ZKFC,ZKFC 负责:
- 运行状况监视:ZKFC 会定期使用运行状况检查命令对本地 NameNode 执行 ping 操作,若 NameNode 及时响应回复,说明 NameNode 状态健康;否则标记运行状况不佳;
假设两个 NameNode 都处于活跃状态,可能存在这样一种情况导致出现了脑裂,如何预防脑裂?
预防脑裂的思路就是将旧的 Active NameNode 隔离起来,使它不能对外提供服务,保证集群中任何时候都只会存在一个 NameNode 处于工作状态:
- 基于共享存储隔离:同一时刻只允许一个 NameNode 向 JournalNode 写入 EditLog;
- 基于客户端隔离:同一时刻只允许一个 NameNode 响应客户端请求;
- 基于DataNode隔离:同一时刻只允许一个 NameNode 向 DataNode 下发命名空间相关命令(删除、复制数据块等);
QJM、NFA 实现原理及区别
核心思想是多个 NameNode 节点间如何共享 EditLog 文件:
Active NameNode 将日志文件写到共享存储上,Standby NameNode 会实时地从共享存储上读取 EditLog 文件然后合并到 Standby NameNode 的命名空间中。一旦 NameNode 发生故障就切换到 Standby NameNode。
QJM 基于 Paxos 算法的实现,基本原理是设置 2n+1 台 JournalNode 机器,每台机器都保存 EditLog 文件。QJM 向 JournalNode集群并行发送写 EditLog 文件的请求,当超过半数以上 JournalNode 返回成功,就认为此次操作成功了。
QJM 实现 HA 的好处是:
- JournalNode 集群不存在单点故障问题,可以配置 QJM 的鲁棒性,2n+1 台机器最多容忍 n 台机器同时故障;
- QJM 存储的日志不会因为某台机器延迟而影响整体系统的延迟,因为 NameNode 并行地向 JournalNode 发送 EditLog;
- JournalNode 进程可以运行在普通的机器上,而无需配置专业的共享存储硬件;
读写机制与安全模式
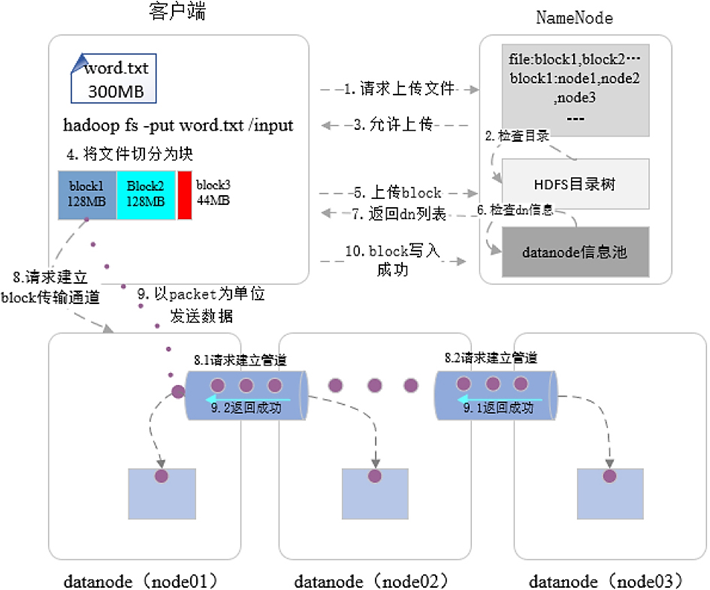
用户在向 NameNode 写入文件时,会按照如下步骤进行:
- 客户端向 NameNode 发起文件上传请求,NameNode 检查文件需要上传的目录,并鉴权;若有权限,则允许客户端上传操作;
- 客户端对大文件进行切分,然后以此上传小文件块,这里以上传 Block1 为例:
- 客户端首先向 NameNode 发起请求,NameNode 按照文件块副本放置策略,为当前文件块选择合适的 DataNode 节点,并按照与客户端的路由由近到远排序,最后返回 DataNode 列表给客户端;
- 客户端接收到 DataNode 列表数据后,按照由近到远,依次与 DataNode 建立管道连接,然后发送数据文件。
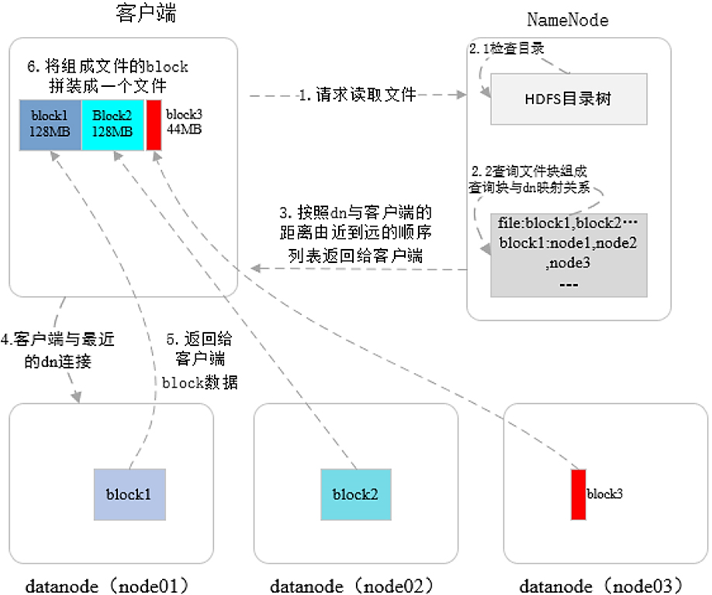
读操作更简单:
- 客户端向 NameNode 发起读文件请求,NameNode 开始鉴权,如果用户对文件有读取权限,就查询文件元数据信息并按照文件所在 DataNode 位置由近到远返回;
- 客户端接受到列表后,根据最近距离连接 DataNode,读取 Block 数据。
参考
https://www.cnblogs.com/shoufeng/p/15172108.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号