day53(* django路由层版本区别 * 视图函数的返回值 * JsonResponse对象 * 接收文件数据 * FBV与CBV(基于函数的视图、基于类的视图) * CBV源剖析(学习查看源码) * )

今日内容详细
昨日内容回顾:
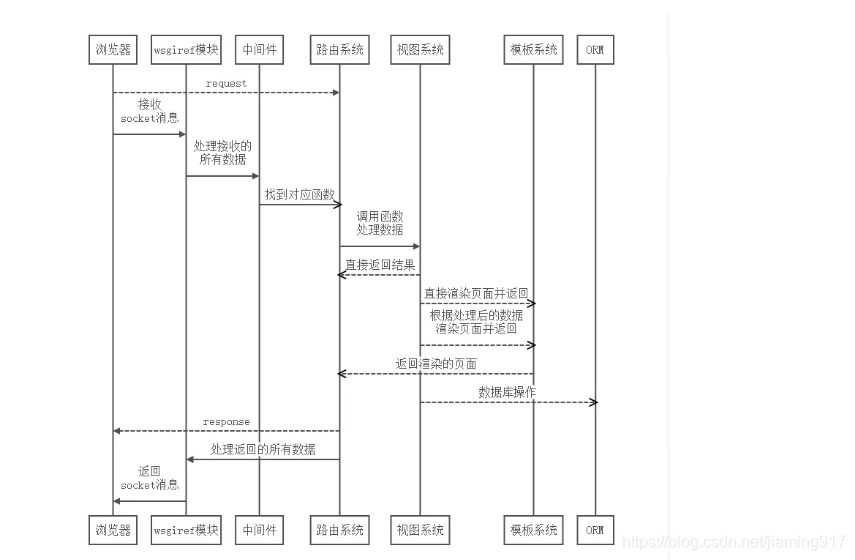
django请求生命周期流程图
#web服务网关接口
1.并发量
默认使用的是wsgiref(并发量很小)
上线之后会替换成uwsgi(并发量较高)
2.处理数据
解析数据 打包数据
路由匹配
特性:url方法第一个参数是一个正则表达式,所哟一路由匹配的一个特点就是能够从用户输入后缀中匹配到即可
注:一般是不会去更改但是要知道
1.django有一个末尾追加斜杠的机制
APPEND_SLASH = True

无名分组 又名分组
1.无名分组
用括号对url方法里面的正则进行分组,当匹配到路由之后
会自动将括号内匹配到的内容当做位置参数传递给视图函数
url(r'^index/(\d+)/',view.index)
index(request,括号内正则匹配到的内容)
2.有名分组
url(r'^testadd/(?P<user_id>[0-9]{4})$', views.testadd)
"""
给括号内的正则表达式起别名之后 匹配成功则会讲括号内匹配到的内容按照关键字参数传递给视图函数
testadd(request,user_id=括号内正则表达式匹配到的内容)
反向解析
"""通过反向解析可以获取到一个结果 该结果可以匹配对应的路由"""
# 基本反向解析
url(r'^index/',index,name='index_view')
{% url 'index_view' %}
from django.shortcuts import reverse
reverse('index_view')
# 无名分组反向解析
url(r'^index/(\d+)/',index,name='index_view')
{% url 'index_view' 123 %}
from django.shortcuts import reverse
reverse('index_view',args=(321,))
# 有名分组反向解析
url(r'^index/(?P<id>\d+)/',index,name='index_view')
{% url 'index_view' 123 %}
{% url 'index_view' id=222 %}
from django.shortcuts import reverse
reverse('index_view',args=(321,))
reverse('index_view',kwargs={'id':333})
无名有名反向解析中的手动传值 这个值在实际工作中到底可以是什么?
一般情况下这个值可以是数据的主键值、页面的页码、区域的编号等
路由分发
"""
django为了更好的协同开发 支持每个应用都可以有自己独有的
urls.py\static\templates
路由分发是为了解决总路由代码过多的问题
那么如果多个应用下业务逻辑代码很多 导致views.py内代码繁重
views.py
我们可以将views.py移除 换成views文件夹
然后在该文件夹内根据业务逻辑的不同拆分成不同的py文件
views文件夹
users.py
account.py
backend.py
"""
# 总路由结尾一定不能加$符 否则无法分发
url('^app01/',include('app01.urls'))
url('^app02/',include('app02.urls'))

名称空间
"""
在使用反向解析起别名的时候 其实应该遵循整个项目中名字都不可以重复
如果出现重复 则需要使用名称空间
"""
url('^app01/',include('app01.urls',namespace='app01'))
url('^app01/',include('app01.urls',namespace='app02'))
# 其实也可以在起别名时就独居重复现象
比如每个应用下的别名全部使用应用应用名作为前缀
今日内容概要

1.数据展示
2.给按钮附加功能
3.如何明确用户到底想要编辑哪条数据
在路由匹配中就应该获取到用户想要编辑的数据主键值
4.点击编辑按钮 应该展示当前数据的编辑页面
通过无名或者有名分组获取到用户想要编辑的数据主键值
获取对应的数据对象传递给页面 展示给用户看并提供编辑功能
5.编写删除功能
路由设计跟编辑功能一致
def home(request):
data_queryset = models.User.objects.filter() # [obj1,obj2,obj3]
return render(request,'home.html',{'data_queryset':data_queryset})
def edit_data(request,edit_id):
# 获取用户编辑的数据对象
edit_obj = models.User.objects.filter(id=edit_id).first()
if not edit_obj:
return HttpResponse('当前用户编号不存在')
if request.method == 'POST':
# 获取新的数据
username = request.POST.get('username')
password = request.POST.get('password')
# 修改原数据 方式1
# models.User.objects.filter(id=edit_id).update(name=username,pwd=password)
# 修改原数据 方式2
edit_obj.name = username
edit_obj.pwd = password
edit_obj.save()
# 重定向到展示页
return redirect('home_view') # 括号内也可以直接写反向解析的别名 不适用于无名有名反向解析
# 将待编辑的数据对象传递给页面展示给用户看
return render(request,'edit.html',{'edit_obj':edit_obj})
def delete_data(request,delete_id):
# 获取想要删除的对象数据
edit_queryset = models.User.objects.filter(id=delete_id)
if not edit_queryset:
return HttpResponse("用户编号不存在")
edit_queryset.delete()
return redirect('home_view')

虚拟环境
到目前位置,我们所有的第三方包安装都是直接通过pip install xx的方式进行安装的,这样安装会将那个包安装到你的系统级的Python环境中。但是这样有一个问题,就是如果你现在用Django 1.18.x写了个网站,然后你的领导跟你说,之前有一个旧项目是用Django 2.1.x开发的,让你来维护,但是Django 1.18.x不再兼容Django 2.1.x的一些语法了。这时候就会碰到一个问题,我如何在我的电脑中同时拥有Django 1.18.x和Django 2.1.x两套环境呢?这时候我们就可以通过虚拟环境来解决这个问题。
方式2:提前准备好多个解释器环境 针对不同的项目切换即可
# 创建虚拟环境
相当于在下载一个全新的解释器
# 识别虚拟环境
文件目录中有一个venv文件夹
# 如何切换环境
选择不用的解释器即可 全文不要再次勾选new enviroment...
django版本区别
django版本区别
- 路由的区别
- django1.X版使用的是url函数
- django2.0版的re_path与path
- 其中url和re_path的用法一样
urlpatterns = [
# 用法完全一致
url(r'^app01/', include(('app01.urls','app01'))),
re_path(r'^app02/', include(('app02.urls','app02'))),
]
- path中第一个是绝对的路径不是正则表达式
- 如果2.X版本中要使用url函数也是可以的,但不推荐使用
from django.conf.urls import url # 在django2.0中同样可以导入1.0中的ur
urlpatterns = [
# 用法完全一致
url(r'^app01/', include(('app01.urls','app01'))),
re_path(r'^app02/', include(('app02.urls','app02'))),
]
- 如何用path完成有名和无名分组
django默认支持一下5种转换器(Path converters)
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
urlpatterns = [
# 问题一的解决方案:
path('articles/<int:year>/', views.year_archive),
# <int:year>相当于一个有名分组,其中int是django提供的转换器,相当于正则表达式,专门用于匹配数字类型,而year则是我们为有名分组命的名,并且int会将匹配成功的结果转换成整型后按照格式(year=整型值)传给函数year_archive
# 问题二解决方法:用一个int转换器可以替代多处正则表达式
path('articles/<int:article_id>/detail/', views.detail_view),
path('articles/<int:article_id>/edit/', views.edit_view),
path('articles/<int:article_id>/delete/', views.delete_view),
]
- 使用尖括号(<>)从url中捕获值,相当于有名分组
-<>中可以包含一个转化器类型(converter type),比如使用 <int:name> 使用了转换器int。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符
- 转换器可以自定义
- 模型层里的外键1.X都是默认级联更新,2.x需要手动配置
name = models.ForeignKey(to='XX', on_delete=models.CASCADE)
# on_delete=models.CASCADE就是级联更新

视图函数的回值HttpResonse
1、Django服务器接收到客户端发送过来的请求后,会将提交上来的数据封装成httpRequest对象传给视图函数。那么视图处理完相关逻辑后,也需要返回一个响应给浏览器。而这个响应必须返回HttpResponseBase或者他的子类的对象,而HttpResponse就是HttpResponseBase中用得最多的子类对象
⑴在django.http模块中定义了HttpResponse对象的API
⑵HttpRequest对象由Django自动创建,HttpResponse对象由程序员创建
⑶在每一个视图函数中必须返回一个HttpResponseBase对象,当然也可以是HttpResponseBase的子类的对象(如HttpResponse对象、JsonResponse对象等)
2、因为HttpResponse对象和JsonResponse对象在Django中使用得比较常见,所以主要介绍这两种
总结
最常用的三个response对象
1、HttpResponse('xxx'):HttpResponse对象,返回字符串
2、render(request, '模板的路径', {}):返回一个页面
3、redirect('路径') 重定向:对这个路径再发出一次请求
注:
1、上面三个函数都可以用来创建一个HttpResponse对象,只是使用方法不一致
2、render和redirect的本质都是HttpResponse对象
⑴render返回的是一个页面
⑵redirect的本质就是HttpResponse对象加上一个状态码( 301 , 302 )和响应头

JsonResponse对象
url路由层
urlpatterns = [
url(r'ab_jason/',views.ab_NMjason)
]
views.py层代码:
(1).import json
def ab_jason(request):
user_dict={'name':'zqh','pwd':666,'hobby':'加油努力好好学习'}
dict_json=json.dumps(user_dict)
return HttpResponse(dict_json)
访问网页结果会乱码:
{"name": "zqh", "pwd": 666, "hobby": "\u52a0\u6cb9\u52aa\u529b\u597d\u597d\u5b66\u4e60"}
views.py层代码防止乱码:
import json
def ab_jason(request):
user_dict={'name':'zqh','pwd':666,'hobby':'加油努力好好学习'}
dict_json=json.dumps(user_dict,ensure_ascii=False)
"""ensure_ascii=False 他只会帮你加一个双引号 然后防止乱码"""
return HttpResponse(dict_json)
{"name": "zqh", "pwd": 666, "hobby": "加油努力好好学习"}
我们上述所操作的东西 防止乱码这个操作其实django帮我们封装好了一东西下面我们看一下:
我们先进行 JsonResponse的导入
from django.http import JsonResponse
def ab_jason(request):
"""JsonResponse方法"""
user_dict = {'name': 'zqh', 'pwd': 666, 'hobby': '加油努力好好学习'}
return JsonResponse(user_dict)
他也会乱码,但是我们自己要学会看源码了,只看自己能看懂的部分
源码:
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
data = json.dumps(data, cls=encoder, **json_dumps_params)
super(JsonResponse, self).__init__(content=data, **kwargs)
#下面我们只看 data = json.dumps(data, cls=encoder, **json_dumps_params)和 json_dumps_params=None 和
if json_dumps_params is None:
json_dumps_params = {}
这句首先看**我们所学函数时候,知道**再调用函数的时候会打散函数,将字典打散成关键字参数,然后我们看 json_dumps_params=None, if json_dumps_params is None:是一个空字典
言外之意就是改成不是None,就用我们传过来的值
记下来我们进行操作
views.py层代码:
from django.http import JsonResponse
def ab_jason(request):
"""JsonResponse方法"""
user_dict = {'name': 'zqh', 'pwd': 666, 'hobby': '加油努力好好学习'}
return JsonResponse(user_dict, json_dumps_params={'ensure_ascii': False})
views.py层代码:
from django.http import JsonResponse
def ab_jason(request):
user_list = [11, 22, 33, 44, 55, 66]
return JsonResponse(user_list,safe=False)
看源码、、、、 def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)看一下报错,为什么看报错,因为这里边告诉了你如果你想序列化不是字典的对象会报错需要改成
:safe =False,看报错就是为了就看解决方案,如果不加safe=False 直接报错
In order to allow non-dict objects to be serialized set the safe parameter to False.
"""为什么使用JsonResponse还不是原始的json模块"""
django对json序列化的数据类型的范围做了扩充
form表单上传文件
url代码:
urlpatterns = [
url(r'ab_form/', views.ab_form)
]
views.py代码:
@csrf_exempt
def ab_form(request):
if request.method == 'POST':
print(request.POST)
print(request.FILES)
file_obj = request.FILES.get('my_file')
print(file_obj.name)
with open(file_obj.name, 'wb') as f:
for line in file_obj:
f.write(line)
return render(request, 'form.html')
form.html代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Title</title>
</head>
<body>
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<form action="" method="post" enctype="multipart/form-data">
<p>username:
<input type="text" name="username" class="form-control">
</p>
<p>files:
<input type="file" name="my_file" class="form-control">
</p>
<input type="submit" class="btn btn-success btn-block">
</form>
</div>
</div>
</div>
</body>
</html>
form表单上传的数据中如果含有文件 那么需要做以下几件事
1.method必须是post
2.enctype必须修改为multipart/form-data
默认是application/x-www-form-urlencoded
3.后端需要使用request.FILES获取
# django会根据数据类型的不同自动帮你封装到不同的方法中
补充:
POST报错去settings里面注释掉这句话'django.middleware.csrf.CsrfViewMiddleware'
或者导入from django.views.decorators.csrf import csrf_exempt
导入模块之后在用到POST的代码中加入装饰器@csrf_exempt

request其他方法
request.method 返回的是纯大写的请求方法字符串'POST' 'GET'
request.POST 结果是一个QueryDict 可以看成字典处理
request.GET
request.FILES
request.body
存放的是接收过来的最原始的二进制数据
request.POST、request.GET、request.FILES这些获取数据的方法其实都从body中获取数据并解析存放的
request.path
获取路径
request.path_info
获取路径
request.get_full_path()
获取路径并且还可以获取到路径后面携带的参数
获取当前请求方式
request.method 返回的是纯大写的请求方法字符串'POST' 'GET'
FBV与CBV

#FBV就是在url中一个路径对应一个函数
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/', views.index)
]
在视图函数中
def index(request):
return render(request, 'index.html')
#CBV就是在url中一个路径对应一个类
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 执行类后面的as_view()方法,是父类里面的方法
url(r'^index/', views.IndexView.as_view())
]
在视图函数中
from django.views import View
class IndexView(View):
# 以get形式访问会执行get函数,一般情况下获取数据
def get(self, *args, **kwargs):
return HttpResponse('666')
# 以post形式访问的话会执行post函数,一般情况下发送数据
def post(self, *args, **kwargs):
return HttpResponse('999')
在写代码中的几点注意事项
cbv定义类的时候必须要继承view
在写url的时候必须要加as_view
类里面使用form表单提交的话只有get和post方法
CBV:基于类的视图
from django import views
class MyLoginView(views.View):
def get(self, request):
return HttpResponse("from CBV get view")
def post(self, request):
return HttpResponse("from CBV post view")
url(r'^ab_cbv/', views.MyLoginView.as_view())
"""
如果请求方式是GET 则会自动执行类里面的get方法
如果请求方式是POST 则会自动执行类里面的post方法
"""
CBV源码剖析

"""
函数名或者方法名遇到括号执行优先级最高
对象查找属性或方法的顺序
永远都是先从自己身上找
然后去产生对象的类中找
再去类的父类中找 如果都没有才会报错
闭包函数
定义在函数内部并且使用了外层函数名称空间中的名字
回去记得复习面向对象反射
"""
FBV与CBV在路由匹配上本质其实是一样的
都是正则表达式对应函数名
切入口为url对应关系:
url(r'^login/', views.MyLogin.as_view())
def as_view(cls, **initkwargs):
def view(request, *args, **kwargs):
# cls使我们自定义的类 MyLogin
self = cls(**initkwargs) # 产生一个MyLogin类的对象 obj
return self.dispatch(request, *args, **kwargs)
return view
def dispatch(self, request, *args, **kwargs):
if request.method.lower() in self.http_method_names: # 判断当前请求方法是否在八个方法内
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^analysis', views.MyLogin.as_view())
'''
函数名/方法名 加括号执行优先级最高
猜测:
1.as_view() 是被 @classmethod 修饰的类方法
2.as_view() 是被 @staticmethod 修饰的静态方法
'''
# 由于上述代码在执行之后会立即执行并返回 view 方法的内存地址
# 因此可以转化为 url(r'^analysis', views.view)
]
因此 CBV 与 FBV 在路由匹配上本质是一样的,都是路由对应函数的内存地址
def view(request, *args, **kwargs):
self = cls(**initkwargs) ==> selg = MyLogin(**initkwargs) # 产生一个我们自己写的类的对象
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
def dispatch(self, request, *args, **kwargs):
# 获取当前请求的小写格式,然后比对当前请求方式是否合法,http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
"""
反射:通过字符串来操作对象的属性或方法
handler = getattr(自定义的类产生的对象,请求方式,找不到该请求方式的属性或方法时就会使用第三个参数)
"""
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
# 自动调用自定义的方法
在查看 Python 源码时,一定要时刻牢记面相对象属性方法查找顺序
- 先从对象自己找
- 再去产生对象的类里找
- 之后再去父类里找
1.切入点:路由匹配
类名点属性as_view并且还加了括号
as_view可能是普通的静态方法
as_view可能是绑定给类的方法
2.对象查找属性的顺序
先从对象自身开始、再从产生对象的类、之后是各个父类
MyLoginView.as_view()
先从我们自己写的MyLoginView中查找
没有再去父类Views中查找
3.函数名加括号执行优先级最高
url(r'^ab_cbv/', views.MyLoginView.as_view())
项目已启动就会执行as_view方法 查看源码返回了一个闭包函数名view
def as_view(cls):
def view(cls):
pass
return view
url(r'^ab_cbv/', views.view)
# CBV与FBV在路由匹配本质是一样的!!!
4.路由匹配成功之后执行view函数
def view():
self = cls()
return self.dispatch(request, *args, **kwargs)
5.执行dispatch方法
需要注意查找的顺序!!!
def dispatch():
handler = getattr(self, request.method.lower())
return handler(request, *args, **kwargs)
"""查看源码也可以修改 但是尽量不要这么做 很容易产生bug"""

模板语法的传值
模板语法
只有两种书写格式
{{ }}:变量相关(引用变量值)
{% %}:逻辑相关(流程控制 模块方法),列如:for,if
传值范围
https://www.cnblogs.com/Dominic-Ji/articles/11109067.html#_label15
注释:
<!--HTML注释--> 浏览器能够查看
{#模板语法注释#} 浏览器查看不了
def reg(request):
# python基本数据类型
f = 1.1
i = 11
s = 'hello world'
l = [11,22,33,44]
d = {'username':"jason",'password':123}
t = (11,22,33,44,55,66,77)
se = {11,22,33,44,55,66}
b = True
# 函数(自动加括号调用函数 展示的是函数的返回值)
def func(args): # 模板语法不支持给函数传递额外的参数
print('from func')
return '下午有点困'
# 面向对象
class MyClass(object): # 自动加括号实例化产生对象
def get_obj(self):
return 'from obj'
@classmethod
def get_cls(cls):
return 'from cls'
@staticmethod
def get_func():
return 'from func'
obj = MyClass()
# 1.指名道姓的传(需要传的值较少)
return render(request,'reg.html',{...})
# 2.一次性批量传(效率偏低) 为了演示方便我们使用locals居多
return render(request,'reg.html',locals())
locals() 函数会以字典类型返回当前位置的全部局部变量。
补充:给HTML页面传递函数名和类名都会自动加括号调用(模板语法不支持额外的传参)
类名
自动加括号实例化成对象
对象名
直接显示对象的地址 并且具备调用属性和方法的能力
如何给html文件传值
1.{}字典挨个指名道姓
节省系统资源
2.locals()全部传递
节省人力资源 # 学习阶段就使用这种方式
1.python基本数据类型全部支持模板语法传值
2.在django中模板语法取值只能使用一种方式(句点符.)
3.针对函数名模板语法传值之后会自动加括号执行将返回值渲染到页面上
4.针对类名和对象名模板语法传值之后都会先加括号调用
类名加括号会产生对象
对象加括号不符合正常的调用方式 还是对象本身
但是会触发产生该对象类中的__call__方法
"""
小总结
django模板语法不支持函数传参
当需要引用变量名的时候使用双大括号 {{}}
"""
{{}} # 跟变量名相关
{%%} # 跟功能逻辑相关
单词仅供参考

注:一切以实际代码为主
learn:学习
index:索引
include:包括
namespace:命名空间
return:返回
render:渲染
home:首页
request:请求(要求计算机提供信息或执行另一任务的)指令
edit:编辑
compile:编译
data:数据
method:方法
filter:过滤器
redirect:重定向
qureyset:查询
dele:删除
info:信息
full_path:完整路径
getattr:获取属性
handler:管理者 处理程序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号