
day34(UDP,操作系统)
上周内容回顾
上周最后一天所学就是一个python内置模块,socket套接字
它是专门适用于远程数据交互,我们也了解到了什么是服务端客户端
客户端
1.创建一个数据字典 内部记录了真实数据的各项信息
2.针对字典做序列化、编码处理并获取字典的大小
3.对字典制作一个固定长度的报头
4.发送字典报头
5.发送字典
6.发送真实数据
服务端
1.先接收一个固定长度的报头
2.根据报头解析出字典数据的大小
3.接收字典数据并处理成字典
4.根据字典中的数据接收真实数据
如果数据较大最好不要一次性在recv括号内接收
建议采用循环接收的方式
python内置模块
与应用层打交道,负责协调管理应用层之下的所有层,作用类似于操作系统
"""
服务端的特征
1.固定的ip和port
2.24小时不间断提供服务
...
还有另一个模块 struckt模块两个常见的内置方法
能够将数据大小打包成固定的长度并且还可以解析会之前的大小
struckt.pack (打包固定)
strucke.unpack(解析打包之前)
粘包问题核心是在于recv括号内不知道即将到来的数据量到底多大
# TCP协议的特征
流式协议:会将数据量比较小并且时间间隔较短的数据整合到一起发送
今日内容详细
作业讲解
服务端
import socket
import json
import struct
#
sever = socket.socket()
sever.bind(('127.0.0.1', 8809))
sever.listen(5)
sock, addr = sever.accept()
header = sock.recv(4)
dict_len = struct.unpack('i', header)[0]
dict_bytes = sock.recv(dict_len)
dict_data = json.loads(dict_bytes)
recv_size = 0
total_size = dict_data.get('file_size')
file_name = dict_data.get('file_name')
with open(file_name, 'wb') as f:
while recv_size < total_size:
data = sock.recv(1024)
recv_size += len(data)
# 上周作业讲解
客户端
# os.path.getsize(path)
# 获取指定路径 path 下的文件的大小,以字节(byte)为单位
# 计算机中的单位换算:字节→1024-k→1024-m→1024-g→1024-t…
import socket
import os
import json
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8809))
movie_dir_path = r'D:\day34视频'
while True:
movie_name_list = os.listdir(movie_dir_path)
for i, movie_nam in enumerate(movie_name_list, start=1):
print(i, movie_nam)
choice = input('请选择你想要上传的视频编号>>>>: ').strip()
if not choice.isdigit():
continue
choice = int(choice)
if choice not in range(1, len(movie_name_list) + 1):
print('这个视频不存在')
continue
target_movie_name = movie_name_list[choice - 1]
movie_path=os.path.join(movie_dir_path,target_movie_name)
movie_dict={
'file_name':target_movie_name,
'file_desc':'请你好好欣赏',
'file_size':os.path.getsize(movie_path)
}
movie_dict_json=json.dumps(movie_dict)
movie_dict_len=len(movie_dict_json.encode('utf8'))
dict_header=struct.pack('i',movie_dict_len)
client.send(dict_header)
client.send(movie_dict_json.encode('utf8'))
with open(movie_path,'rb')as f:
for line in f:
client.send(line)
UDP协议
import socket
server = socket.socket(type=socket.SOCK_DGRAM) # 自己指定UDP协议(默认是TCP协议)
server.bind(('127.0.0.1', 8080))
msg, addr = server.recvfrom(1024)
print('msg>>>:', msg.decode('utf8'))
print('addr>>>:', addr)
server.sendto(b'hello baby', addr)
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_addr = ('127.0.0.1', 8080) # 查找通讯录
client.sendto(b'hello server baby', server_addr)
msg, addr = client.recvfrom(1024)
print('msg>>>:', msg.decode('utf8'))
print('addr>>>:', addr)
基于UDP实现简易版本的qq
操作系统的发展史
什么是操作系统:?
操作系统是一组能有效地组织和管理计算机软件和硬件资源,合理地对各类作业进行调度,以方便用户使用的程序的集合
操作系统的发展史也是非常早的,
1945-50年代中期
人工操作方式
1.穿孔卡片
程序员将事先已穿孔的纸带(或卡片)装入纸带输入机(或卡片输入机),再启动它们将纸带(或卡片)上的程序和数据输入计算机,然后启动计算机运行。仅当程序运行完毕并取走计算机结果后,才允许下一个用户上机。
缺点:
1. 用户独占全机。一台计算机的全部资源由上机用户所独占。
2. CPU等待人工操作。当用户进行装带(卡)、卸载(卡)等人工操作是,CPU及内存等资源是空闲的
优势:一个人独占电脑
劣势:CPU利用率极低
有两种批处理方式:联机批处理和脱机批处理
a.联机批处理:联机批处理的主机一直参与包括慢速I/O在内的所有操作。
这种方式不足之处在于:主机仍需处理慢速I/O操作,当进行此操作时,主机一直处于等待状态,造成资源浪费。
b.脱机批处理:脱机批处理有一个快速的大型主机和一个慢速的小型机作为卫星机。
主机可与卫星机进行并行操作,这样提高了主机的利用率和吞吐量
这种方法的去的点是磁带需要人工装卸,作业需要手工分类,监督程序容易造成用户程序遭到破坏,需要人工干预才能恢复。
"""
学习并发编程其实就是在学习操作系统 理论居多 实战很少 都是封装的代码
"""
1.穿孔卡片
优势:一个人独占电脑
劣势:CPU利用率极低
2.联机批处理系统
一次性可以录入多个用户指令、缩短了CPU等待的时间、提高了CPU的利用率
3.脱机批处理系统
是现代计算机核心部件的雏形、提高CPU的利用率
# 总结:操作系统的发展史其实就是提升CPU利用率的过程
1.第一代计算机(1940~1955):真空管和穿孔卡片
2.第二代计算机(1955~1965):晶体管和批处理系统
3.第三代计算机(1965~1980):集成电路芯片和多道程序设计
4.第四代计算机(1980~至今):个人计算机
多道技术
# 目的:提升
CPU利用率 降低程序等待时间
'''强调:目前我们研究并发都是以计算机是单核的情况下:只有一个CPU'''
1.多道技术中的多道指的是多个程序,多道技术的实现是为了解决多个程序竞争或者说共享同一个资源(比如cpu)的有序调度问题,解决方式即多路复用,多路复用分为时间上的复用和空间上的复用
2.空间上的复用:将内存分为几部分,每个部分放入一个程序,这样,同一时间内存中就有了多道程序
3.空间上的复用最大的问题是:程序之间的内存必须分割,这种分割需要在硬件层面实现,由操作系统控制。如果内存彼此不分割,则一个程序可以访问另外一个程序的内存。首先丧失的是安全性,比如你的qq程序可以访问操作系统的内存,这意味着你的qq可以拿到操作系统的所有权限;其次丧失的是稳定性,某个程序崩溃时有可能把别的程序的内存也给回收了,比方说把操作系统的内存给回收了,则操作系统崩溃
串行
多个任务排队执行 总耗时就是多个任务完整时间叠加
多道
利用空闲提前准备 缩短总的执行时间并且还能提高CPU利用率
"""
多道技术
1.空间上的复用
多个任务共用一套计算机硬件
2.时间上的复用
切换+保存状态
CPU在两种情况下会被拿走
1.程序遇到IO操作 CPU自动切走运行其他程序
2.程序长时间占用CPU 系统发现之后也会强行切走CPU 保证其他程序也可以使用
"""
做饭需要30min
洗衣需要50min
烧水需要20min
串行总共需要耗时:30min + 50min + 20min
多道总共需要耗时:50min
进程理论
# 什么是程序、什么是进程
程序:一堆没有被执行的代码(死的)
进程:正在运行的程序(活的)
# 为什么有进程的概念
就是为了更加精确的描述出一些实际状态
他的结构组成:程序、数据和进程控制块
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
进程与程序区别
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。
而进程是程序在处理机上的一次执行过程,它是一个动态的概念。
程序可以作为一种软件资料长期存在,而进程是有一定生命期的。
程序是永久的,进程是暂时的。
进程特征
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行。
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位。
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进。
#进程调度
1.先来先服务
对短作业任务不太友好
2.短作业优先
多长作业任务不太友好
3.时间片轮转法与多级反馈队列
时间片轮转法:先公平的将CPU分给每个人执行
多级反馈队列:根据作业长短的不同再合理分配CPU执行时间
'''目的就是为了能够让单核的计算机也能够做到运行多个程序'
"""并发:
指一个物理CPU(也可以多个物理CPU) 在若干道程序(或线程)之间多路复用,并发性是对有限物理资源强制行使多用户共享以提高效率。
看上去像同时在执行就可以称之为是并发
特点
微观角度:所有的并发处理都有排队等候,唤醒,执行等这样的步骤,在微观上他们都是序列被处理的,如果是同一时刻到达的请求(或线程)也会根据优先级的不同,而先后进入队列排队等候执行。
宏观角度:多个几乎同时到达的请求(或线程)在宏观上看就像是同时在被处理。"""

并行
"""并行:指两个或两个以上事件(或线程)在同一时刻发生,是真正意义上的不同事件或线程在同一时刻,在不同CPU资源呢上(多核),同时执行。"""
""" 特点
同一时刻发生,同时执行。
不存在像并发那样竞争,等待的概念。 """

# 高并发与高并行
高并发:我们写的软件可以支持1个亿的并发量
一个亿的用户来了之后都可以感觉到自己被服务着
高并行:我们写的软件可以支持1个亿的并行量
上述话语的言外之意是计算机有一亿个CPU
同步(synchronous): 所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。简言之,要么成功都成功,失败都失败,两个任务的状态可以保持一致。
异步(asynchronous):所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
# 同步与异步
同步
提交完任务之后原地等待任务的返回结果 期间不做任何事情
异步
提交完任务之后不愿地等待任务的结果 直接去做其他事情 有结果自动提醒

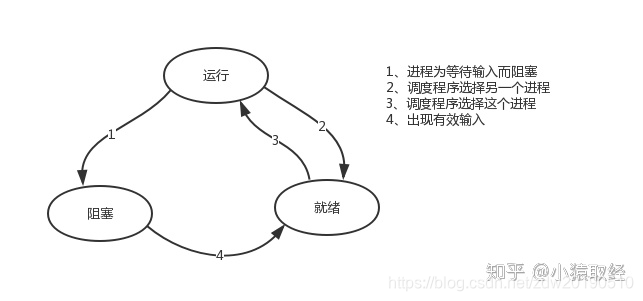
就绪(Ready)状态:当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
执行/运行(Running)状态:当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
阻塞(Blocked)状态:正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
import time
print("程序开始") # 程序开始,运行状态
name = input("请输入姓名:") # 用户输入,进入阻塞
print(name) # 运行状态
time.sleep(1) # 睡眠1秒,阻塞状态
print("程序结束") # 运行状态
同步异步与阻塞非阻塞结合
同步异步:用来描述任务的提交方式
阻塞非阻塞:用来描述任务的执行状态
# 上述两组属于两个不同概念 但是可以结合
同步阻塞:银行排队办理业务 期间不做任何事
同步非阻塞:银行排队办理业务 期间喝水吃东西 但是人还在队列中
异步阻塞:在椅子上坐着 但是不做任何事
异步非阻塞:在椅子上坐着 期间喝水吃东西办公 (程序运行的极致)
同步阻塞,异步阻塞,同步非阻塞,异步非阻塞:
#1.同步阻塞形式
效率最低。拿上面的例子来说,就是你专心排队,什么别的事都不做。
#2.异步阻塞形式
如果在银行等待办理业务的人采用的是异步的方式去等待消息被触发(通知),也就是领了一张小纸条,假如在这段时间里他不能离开银行做其它的事情,那么很显然,这个人被阻塞在了这个等待的操作上面;
异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞。
#3.同步非阻塞形式
实际上是效率低下的。
想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的。
#4.异步非阻塞形式
效率更高,
因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
比如说,这个人突然发觉自己烟瘾犯了,需要出去抽根烟,于是他告诉大堂经理说,排到我这个号码的时候麻烦到外面通知我一下,那么他就没有被阻塞在这个等待的操作上面,自然这个就是异步+非阻塞的方式了。
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号