Logistic Regression
简要说明
LR虽然是回归模型,但却是分类方法。
相较于SVM,在二分类问题中,SVM只会回答该样本是正类还是负类;LR,会回答该样本是正类的概率是多少
模型
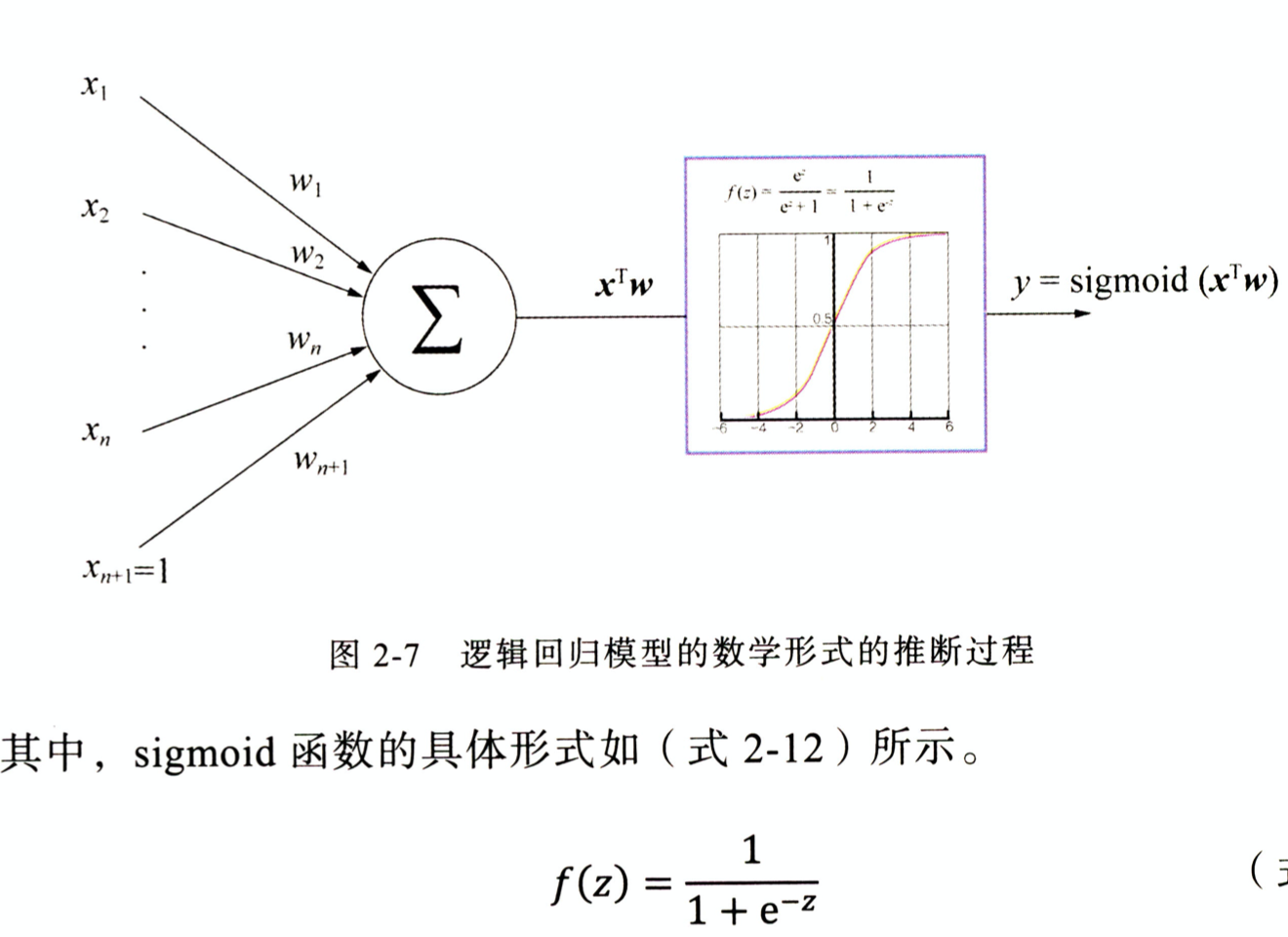
求解方式
利用极大似然

利用梯度下降求解
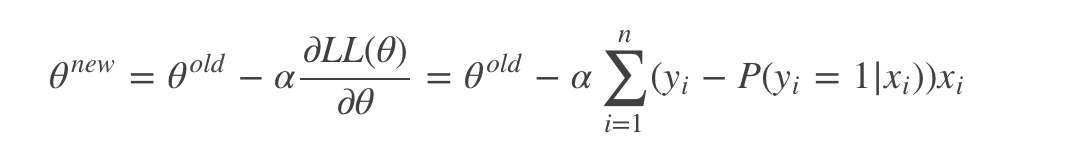
其中,参数α叫学习率,这个参数设置很关键。如果设置的太大。缺点:那么很容易就在最优值附加徘徊;优点:能很快的从远离最优值的地方回到最优值附近。如果设置的太小。缺点:迭代速度太慢。所以通常的技巧是开始迭代时,学习率大,慢慢的接近最优值的时候,学习率变小。
梯度下降算法在每次迭代更新参数时都需要遍历整个数据集,计算复杂度太高。改进的方法是一次仅随机采用一个样本数据的回归误差来更新回归系数。这个方法叫随机梯度下降算法。
regulization:
防止过拟合,利用L1或L2regulization 来减小参数。
正则化是奥卡姆剃刀(Occam’s Razor)原理的一个体现:在所有可能选择(能很好地解释已知数据)的模型中,更倾向于选择尽量简单的模型。
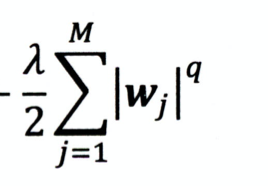
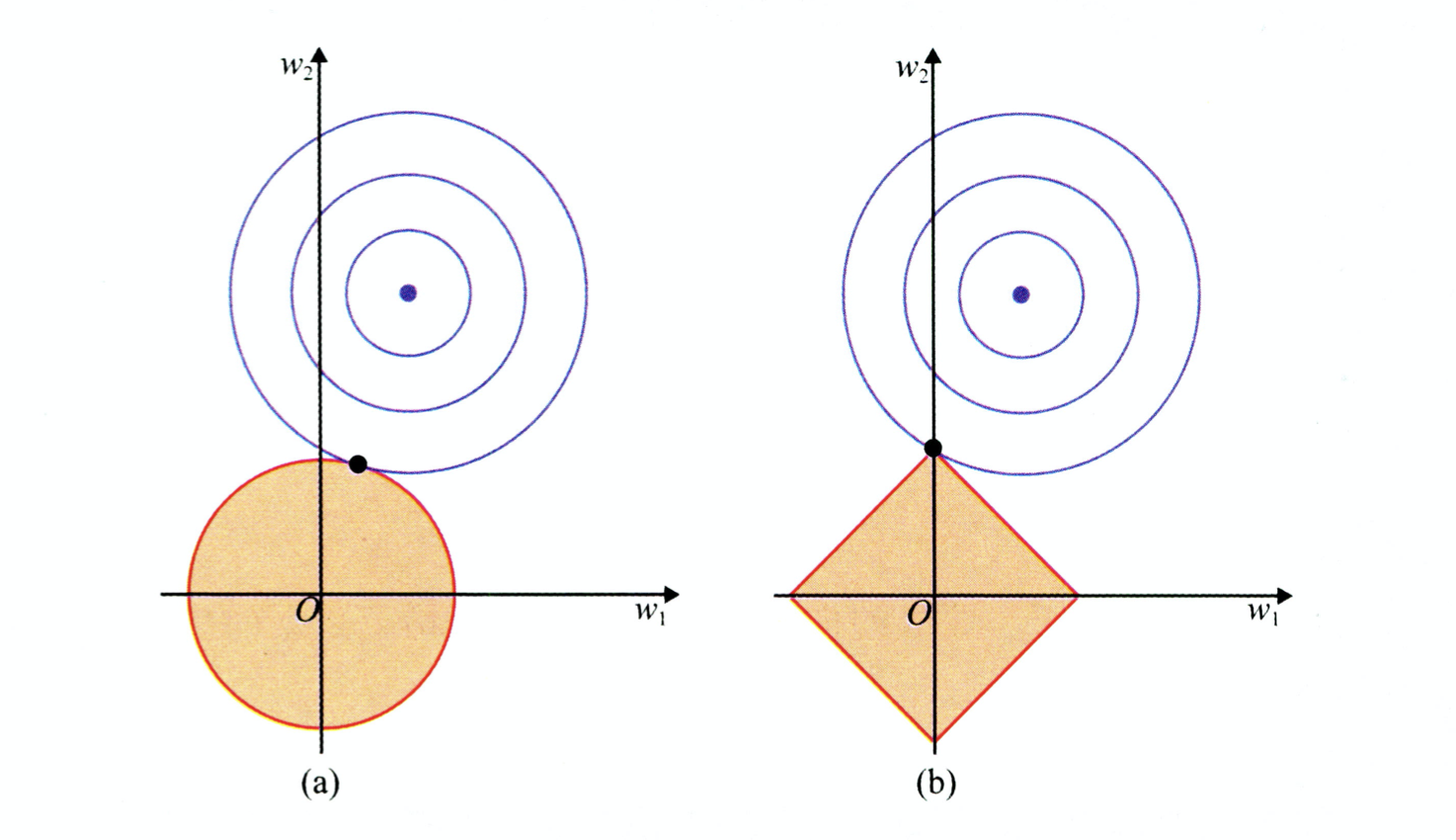
q为1为L1 Regulization, q为2为L2 Regulization
L1 比 L2更容易产生稀疏解
运用似然函数求解概率最大为什么可以用似然函数。
因为目标是要让预测为正的的概率最大,且预测为负的概率也最大,即每一个样本预测都要得到最大的概率,将所有的样本预测后的概率进行相乘都最大,这就能到似然函数了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号