
redis-数据结构
redis为什么快?
首先是基于内存存储 然后高效的数据结构是redis快速处理数据的基础,那么接下来讲讲redis的value数据结构
sds简单动态字符车/双向链表/压缩链表/哈希表/跳表/整数数组
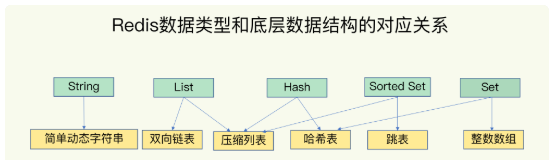
上述的数据结构都是value的表现形式,那么redis是如何通过redis的key找到对应的value的呢?
redis使用了一个哈希表来保存所有的键值对
那么问题又来了,redis哈希冲突与扩容怎么处理呢?
hash冲突就用链表连接,在合适的时机扩容rehash,redis rehash采用渐进式哈希,没处理一个请求时迁移旧表中的一个桶位数据 期间两个hash表同时使用,当有新数据放入新表中查询时两个都查
从key高效的找到value的工作解决了,那么如果value是复杂数据格式的话redis如何高效的处理呢?
压缩列表
类似于数组,数组中的每一个元素对应保存着一个数据,表头有三个字段zlbytes zltail zllen 表示列表长度 列表尾的偏移量 元素数量,列表尾部还有一个zlend表示列表结束

跳表
这个以后再说
根据不同数据结构的特点来选择性的使用是目的
比如list结构使用压缩列表 和 双向链表 由于list自身会存储表头和表位的偏移量,所以list用来做pop队列操作很快 而不适用于随机读写
hash/set底层使用hash表,sorted set采用跳表用来随机读写比较高效,但是遍历效率低,建议使用scan
redis在在集合元素较少的使用考虑内存的使用率采用压缩列表存储因为数组的数据结构紧凑
当元素超过阈值的时候避免查询的复杂度过高,转为hash表或者跳表存储

 浙公网安备 33010602011771号
浙公网安备 33010602011771号