mysql-索引方案
简单的索引方案,不是真实索引方案
1. 要实现简单的索引方案有一些规则需要符合
- 下一个记录页的主键 必须大于上一个记录页的主键

假设表中有三条用户记录,当一条新的主键为4的用户记录插入到表中的时候,为了遵守第一条规则需要创建一个新的页,并且把主键为5的记录后移,这一过程称为页分裂
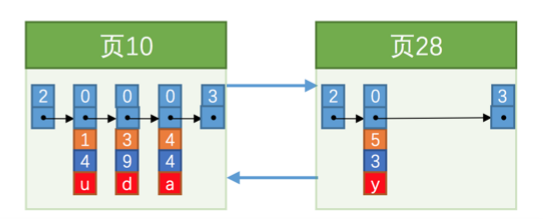
下一步是给这些用户记录建立一个目录, 每一个目录页对应一个目录项,目录项包含两部分数据
1. 一页的用户记录中最小的主键值,我们用key表示
2. 页号 我们用page_no表示
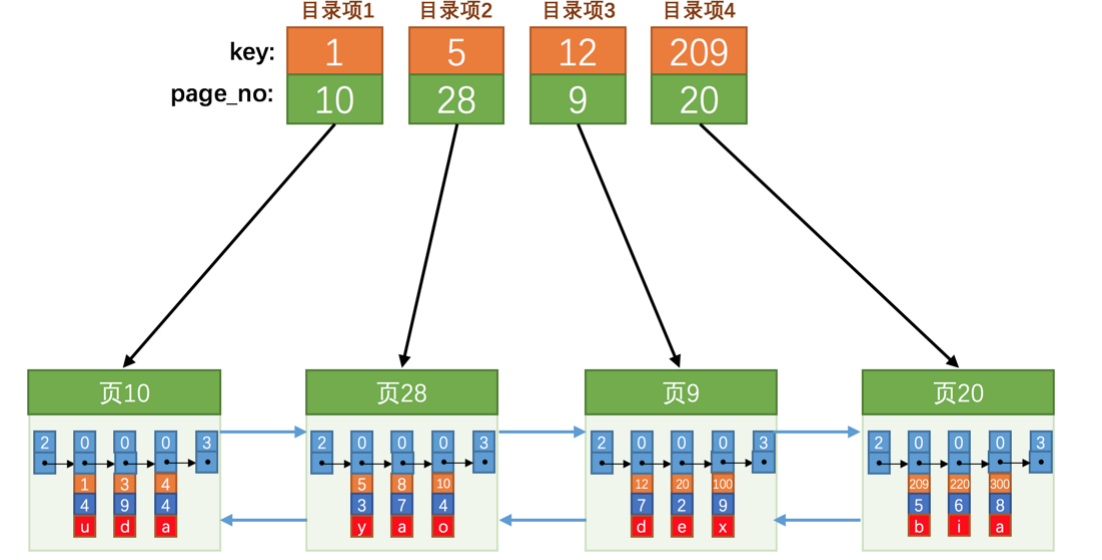
查找的时候,使用二分法先查找到合适的目录项,在遍历页中的数据查到想要的那条记录
Innodb中的索引方案
上面简单的实现方案问题出现在 目录页的数据在mysql中不可能是连续的空间,mysql的innodb索引实现方案是使用记录页来存储目录项
目录项的record-type是1,普通的用户记录为0
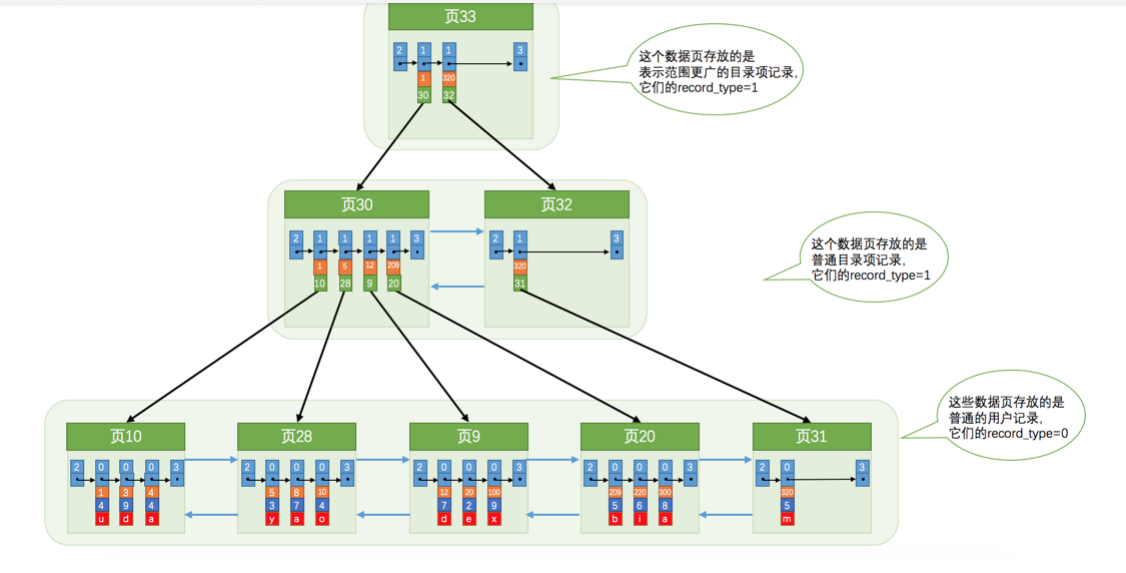
当目录项的记录过多超出了16kb,数据是不连续的如何快速定位呢?这是需要抽取出更高一级的目录页,目录项的范围更大
这样的结果就是 叶子节点存储着真实的用户记录,非叶子节点存储着目录项
聚簇索引的特点
1. 根据记录主键值大小进行页和记录的排序
- 页中的记录是根据主键大小排序成一个单向链表
- 相同层次的目录项 根据主键大小排序成一个双向链表
2. 叶子节点存储着完整的用户记录
二级索引
非主键建立的索引 特点是叶子节点存储的是索引字段的值和主键值
当使用索引查找到对应的用户记录是需要用索引字段关联的主键回表查询出用户记录 所以查询非主键记录需要用到两个b+树
联合索引
当多个字段组成联合索引的时候,以a/b字段举例,先以a字段排序 a相同再根据b字段排序,叶子节点存储着ab记录和记录对应的主键,也需要回表查询
innodb索引的特点
1. b+索引是先创建根节点页,然后在页分裂,自诞生之日起不会移动,创建的时候会存储在一个地方 方便直接使用根节点查找
2. 目录项记录的唯一性(索引字段+主键实现唯一性)
3. 一个页最少存储两条记录
page Directory页目录
在一个页中排序,对记录进行分组,每组最后一条记录着本组的记录数,每组中的最大记录存储在页目录中,查找的时候 通过二分法查找到槽位中对应的分组,然后从最小记录遍历查询到要找的记录
举例根据主键查找一条记录的过程,这个聚簇索引假设有三层
1.根据主键在根节点的目录项页中查找对应的记录,有页目录可以通过二分查找到对应的目录,然后从最小主键遍历查找,
目录项页中的记录是根据主键有小到大排序的,记录只有主键和页号值 record_type = 1
2. 查到到第二层的目录项页,重复第一步的过程 查找到对应的用户记录页 indexpage
3. 在用户记录页根据page direction 页目录二分查找对应的分组,在分组中从最小的主键遍历对比
页内的记录根据主键大小顺序形成一个单向链表
index页 根据主键大小形成一个双向链表
同一层的目录项页 也是根据主键大小形成一个双向链表
二级索引 除了排序使用的键值与聚簇索引的值不同外,叶子节点存储的是二级索引列值 和主键值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号