

Pytho框架(django)(三)
MVC和MTV模式
著名的MVC模式:所谓MVC就是把web应用分为模型(M),控制器(C),视图(V)三层;他们之间以一种插件似的,松耦合的方式连接在一起。
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。
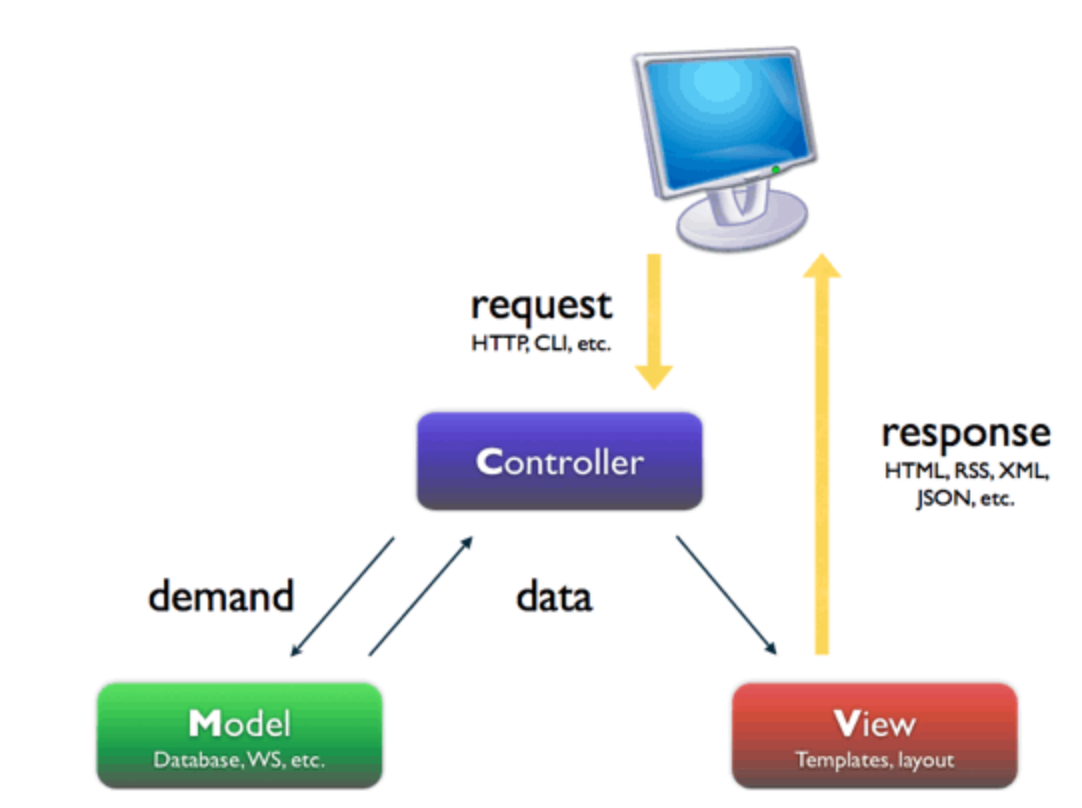
Django的MTV模式本质上与MVC模式没有什么差别,也是各组件之间为了保持松耦合关系,只是定义上有些许不同,Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个url分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
django的流程和命令行工具
django实现流程
 View Code
View Codedjango的命令行工具
django-admin.py 是Django的一个用于管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每一个Django Project里都会有一个mannage.py。
<1> 创建一个django工程 : django-admin.py startproject mysite
当前目录下会生成mysite的工程,目录结构如下:
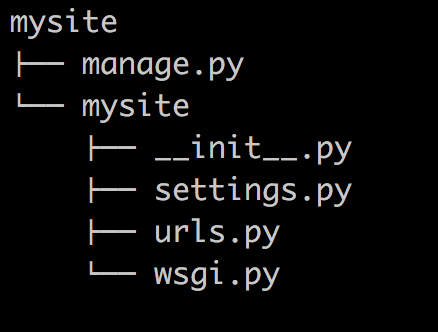
- manage.py ----- Django项目里面的工具,通过它可以调用django shell和数据库等。
- settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----- 负责把URL模式映射到应用程序。
<2>在mysite目录下创建blog应用: python manage.py startapp blog
<3>启动django项目:python manage.py runserver 8080
这样我们的django就启动起来了!当我们访问:http://127.0.0.1:8080/时就可以看到:

<4>生成同步数据库的脚本:python manage.py makemigrations
同步数据库: python manage.py migrate
注意:在开发过程中,数据库同步误操作之后,难免会遇到后面不能同步成功的情况,解决这个问题的一个简单粗暴方法是把migrations目录下
的脚本(除__init__.py之外)全部删掉,再把数据库删掉之后创建一个新的数据库,数据库同步操作再重新做一遍。
<5>当我们访问http://127.0.0.1:8080/admin/时,会出现:
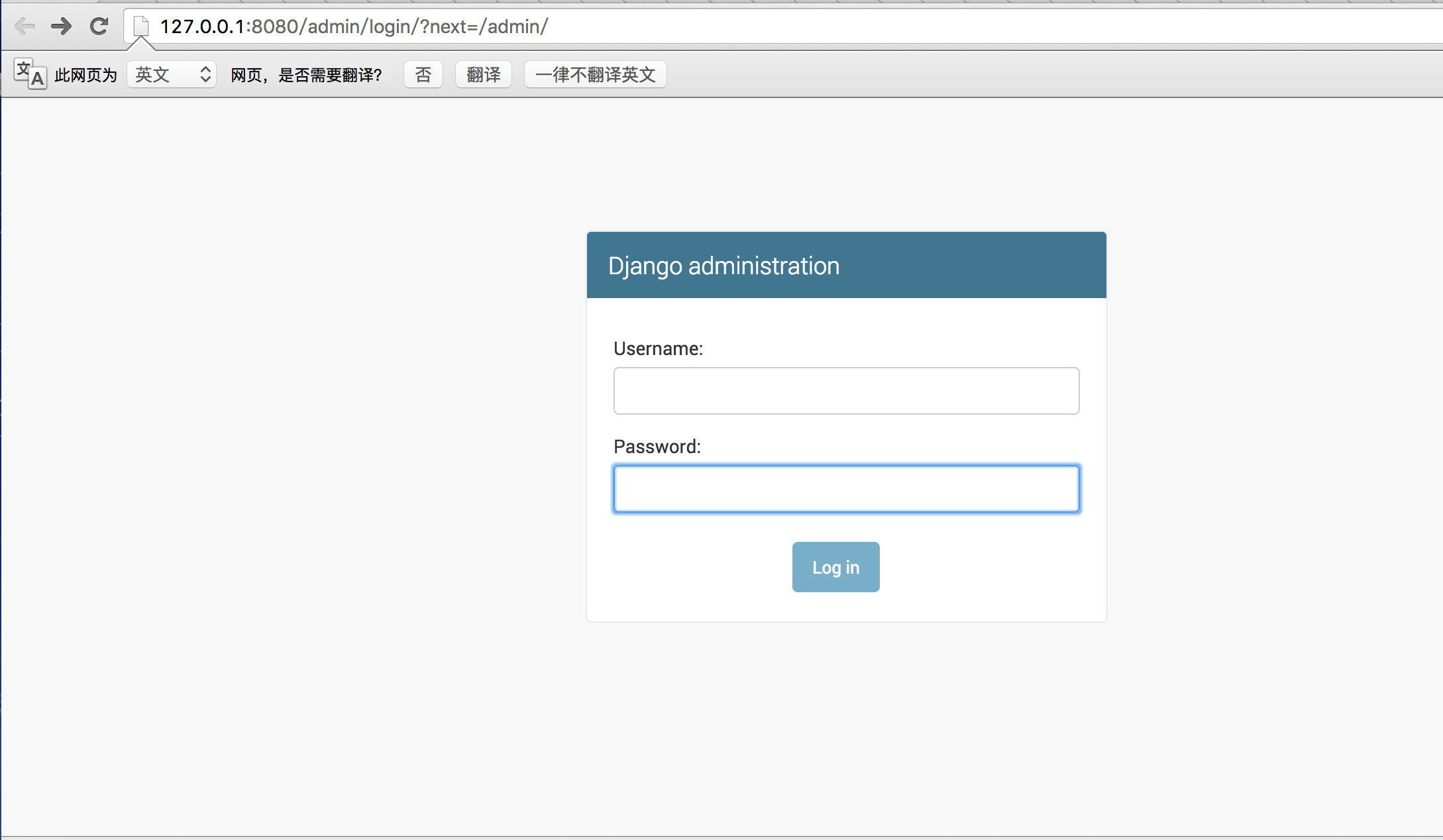
所以我们需要为进入这个项目的后台创建超级管理员:python manage.py createsuperuser,设置好用户名和密码后便可登录啦!
<6>清空数据库:python manage.py flush
<7>查询某个命令的详细信息: django-admin.py help startapp
admin 是Django 自带的一个后台数据库管理系统。
<8>启动交互界面 :python manage.py shell
这个命令和直接运行 python 进入 shell 的区别是:你可以在这个 shell 里面调用当前项目的 models.py 中的 API,对于操作数据,还有一些小测试非常方便。
<9> 终端上输入python manage.py 可以看到详细的列表,在忘记子名称的时候特别有用。
Django URL (路由系统)
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
|
1
2
3
|
urlpatterns = [ path(正则表达式, views视图函数,参数,别名),] |
参数说明:
- 一个正则表达式字符串
- 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 可选的要传递给视图函数的默认参数(字典形式)
- 一个可选的name参数


from django.conf.urls import path,re_path from django.contrib import admin from app01 import views urlpatterns = [ path('articles/2003/', views.special_case_2003), #re_path('articles/[0-9]{4}/$', views.year_archive), re_path('articles/([0-9]{4})/$', views.year_archive), #no_named group re_path('articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), re_path('articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
六 Django Views(视图函数)

http请求中产生两个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
所在位置:django.http
之前我们用到的参数request就是HttpRequest 检测方法:isinstance(request,HttpRequest)
1 HttpRequest对象的属性和方法:
View Code注意一个常用方法:request.POST.getlist('')
2 HttpResponse对象:
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse
在HttpResponse对象上扩展的常用方法:
|
1
2
3
|
页面渲染: render()(推荐)<br> render_to_response(),页面跳转: redirect("路径")locals(): 可以直接将函数中所有的变量传给模板 |
Template基础
模板系统的介绍
你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python代码之中。
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意。 让我们来看一下为什么:
-
对页面设计进行的任何改变都必须对 Python 代码进行相应的修改。 站点设计的修改往往比底层 Python 代码的修改要频繁得多,因此如果可以在不进行 Python 代码修改的情况下变更设计,那将会方便得多。
-
Python 代码编写和 HTML 设计是两项不同的工作,大多数专业的网站开发环境都将他们分配给不同的人员(甚至不同部门)来完成。 设计者和HTML/CSS的编码人员不应该被要求去编辑Python的代码来完成他们的工作。
-
程序员编写 Python代码和设计人员制作模板两项工作同时进行的效率是最高的,远胜于让一个人等待另一个人完成对某个既包含 Python又包含 HTML 的文件的编辑工作。
基于这些原因,将页面的设计和Python的代码分离开会更干净简洁更容易维护。 我们可以使用 Django的 模板系统 (Template System)来实现这种模式,这就是本章要具体讨论的问题。
------------------------------------------------------------------模板语法------------------------------------------------------------------
一模版的组成
组成:HTML代码+逻辑控制代码
二 逻辑控制代码的组成
1 变量(使用双大括号来引用变量):
|
1
|
语法格式: {{var_name}} |
Django 模板解析非常快捷。 大部分的解析工作都是在后台通过对简短正则表达式一次性调用来完成。 这和基于 XML 的模板引擎形成鲜明对比,那些引擎承担了 XML 解析器的开销,且往往比 Django 模板渲染引擎要慢上几个数量级。
推荐方式------深度变量的查找(万能的句点号)
在到目前为止的例子中,我们通过 context 传递的简单参数值主要是字符串,然而,模板系统能够非常简洁地处理更加复杂的数据结构,例如list、dictionary和自定义的对象。
在 Django 模板中遍历复杂数据结构的关键是句点字符 (.)。
View Code------变量的过滤器(filter)的使用
|
1
|
语法格式: {{obj|filter:param}} |
View Code2 标签(tag)的使用(使用大括号和百分比的组合来表示使用tag)
|
1
|
{% tags %} |
------{% if %} 的使用
{% if %}标签计算一个变量值,如果是“true”,即它存在、不为空并且不是false的boolean值,系统则会显示{% if %}和{% endif %}间的所有内容
View Code------{% for %}的使用
{% for %}标签允许你按顺序遍历一个序列中的各个元素,每次循环模板系统都会渲染{% for %}和{% endfor %}之间的所有内容
View Code------{%csrf_token%}:csrf_token标签
用于生成csrf_token的标签,用于防治跨站攻击验证。注意如果你在view的index里用的是render_to_response方法,不会生效
其实,这里是会生成一个input标签,和其他表单标签一起提交给后台的。
------{% url %}: 引用路由配置的地址
View Code------{% with %}:用更简单的变量名替代复杂的变量名
|
1
|
{% with total=fhjsaldfhjsdfhlasdfhljsdal %} {{ total }} {% endwith %} |
------{% verbatim %}: 禁止render
|
1
2
3
|
{% verbatim %} {{ hello }}{% endverbatim %} |
------{% load %}: 加载标签库
3 自定义filter和simple_tag
------a、在app中创建templatetags模块(必须的)
------b、创建任意 .py 文件,如:my_tags.py
View Code------c、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py :{% load my_tags %}
------d、使用simple_tag和filter(如何调用)
View Code------e、在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
注意:
filter可以用在if等语句后,simple_tag不可以
View Code4 extend模板继承
------include 模板标签
在讲解了模板加载机制之后,我们再介绍一个利用该机制的内建模板标签: {% include %} 。该标签允许在(模板中)包含其它的模板的内容。 标签的参数是所要包含的模板名称,可以是一个变量,也可以是用单/双引号硬编码的字符串。 每当在多个模板中出现相同的代码时,就应该考虑是否要使用 {% include %} 来减少重复。
------extend(继承)模板标签
到目前为止,我们的模板范例都只是些零星的 HTML 片段,但在实际应用中,你将用 Django 模板系统来创建整个 HTML 页面。 这就带来一个常见的 Web 开发问题: 在整个网站中,如何减少共用页面区域(比如站点导航)所引起的重复和冗余代码?
解决该问题的传统做法是使用 服务器端的 includes ,你可以在 HTML 页面中使用该指令将一个网页嵌入到另一个中。 事实上, Django 通过刚才讲述的 {% include %} 支持了这种方法。 但是用 Django 解决此类问题的首选方法是使用更加优雅的策略—— 模板继承 。
本质上来说,模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
让我们通过修改 current_datetime.html 文件,为 current_datetime 创建一个更加完整的模板来体会一下这种做法:
View Code这看起来很棒,但如果我们要为 hours_ahead 视图创建另一个模板会发生什么事情呢?
View Code很明显,我们刚才重复了大量的 HTML 代码。 想象一下,如果有一个更典型的网站,它有导航条、样式表,可能还有一些 JavaScript 代码,事情必将以向每个模板填充各种冗余的 HTML 而告终。
解决这个问题的服务器端 include 方案是找出两个模板中的共同部分,将其保存为不同的模板片段,然后在每个模板中进行 include。 也许你会把模板头部的一些代码保存为 header.html 文件:
View Code你可能会把底部保存到文件 footer.html :
View Code对基于 include 的策略,头部和底部的包含很简单。 麻烦的是中间部分。 在此范例中,每个页面都有一个<h1>My helpful timestamp site</h1> 标题,但是这个标题不能放在 header.html 中,因为每个页面的 <title> 是不同的。 如果我们将 <h1> 包含在头部,我们就不得不包含 <title> ,但这样又不允许在每个页面对它进行定制。 何去何从呢?
Django 的模板继承系统解决了这些问题。 你可以将其视为服务器端 include 的逆向思维版本。 你可以对那些不同 的代码段进行定义,而不是 共同 代码段。
第一步是定义 基础模板,该框架之后将由子模板所继承。 以下是我们目前所讲述范例的基础模板:
View Code这个叫做 base.html 的模板定义了一个简单的 HTML 框架文档,我们将在本站点的所有页面中使用。 子模板的作用就是重载、添加或保留那些块的内容。 (如果你一直按顺序学习到这里,保存这个文件到你的template目录下,命名为 base.html .)
我们使用模板标签: {% block %} 。 所有的 {% block %} 标签告诉模板引擎,子模板可以重载这些部分。 每个{% block %}标签所要做的是告诉模板引擎,该模板下的这一块内容将有可能被子模板覆盖。
现在我们已经有了一个基本模板,我们可以修改 current_datetime.html 模板来 使用它:
View Code再为 hours_ahead 视图创建一个模板,看起来是这样的:
View Code看起来很漂亮是不是? 每个模板只包含对自己而言 独一无二 的代码。 无需多余的部分。 如果想进行站点级的设计修改,仅需修改 base.html ,所有其它模板会立即反映出所作修改。
以下是其工作方式:
在加载 current_datetime.html 模板时,模板引擎发现了 {% extends %} 标签, 注意到该模板是一个子模板。 模板引擎立即装载其父模板,即本例中的 base.html 。此时,模板引擎注意到 base.html 中的三个 {% block %} 标签,并用子模板的内容替换这些 block 。因此,引擎将会使用我们在 { block title %} 中定义的标题,对 {% block content %} 也是如此。 所以,网页标题一块将由{% block title %}替换,同样地,网页的内容一块将由 {% block content %}替换。
注意由于子模板并没有定义 footer 块,模板系统将使用在父模板中定义的值。 父模板 {% block %} 标签中的内容总是被当作一条退路。继承并不会影响到模板的上下文。 换句话说,任何处在继承树上的模板都可以访问到你传到模板中的每一个模板变量。你可以根据需要使用任意多的继承次数。 使用继承的一种常见方式是下面的三层法:
<1> 创建 base.html 模板,在其中定义站点的主要外观感受。 这些都是不常修改甚至从不修改的部分。 <2> 为网站的每个区域创建 base_SECTION.html 模板(例如, base_photos.html 和 base_forum.html )。这些模板对base.html 进行拓展,
并包含区域特定的风格与设计。 <3> 为每种类型的页面创建独立的模板,例如论坛页面或者图片库。 这些模板拓展相应的区域模板。
这个方法可最大限度地重用代码,并使得向公共区域(如区域级的导航)添加内容成为一件轻松的工作。
以下是使用模板继承的一些诀窍:
View CodeModels
数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:

View Code注意:
View CodeORM(对象关系映射)
用于实现面向对象编程语言里不同类型系统的数据之间的转换,换言之,就是用面向对象的方式去操作数据库的创建表以及增删改查等操作。
优点: 1 ORM使得我们的通用数据库交互变得简单易行,而且完全不用考虑该死的SQL语句。快速开发,由此而来。
2 可以避免一些新手程序猿写sql语句带来的性能问题。
比如 我们查询User表中的所有字段:
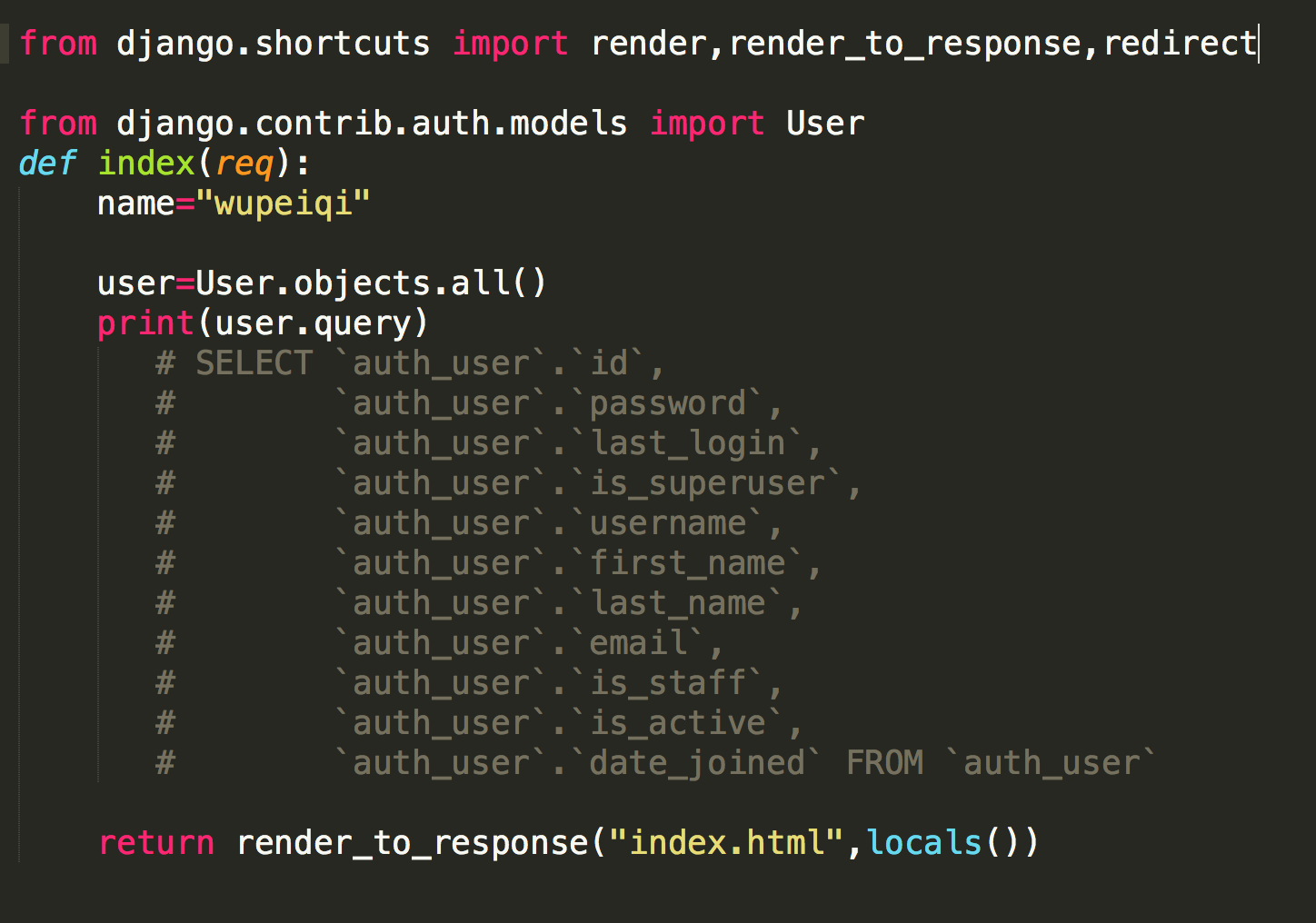
新手可能会用select * from auth_user,这样会因为多了一个匹配动作而影响效率的。
缺点:1 性能有所牺牲,不过现在的各种ORM框架都在尝试各种方法,比如缓存,延迟加载登来减轻这个问题。效果很显著。
2 对于个别复杂查询,ORM仍然力不从心,为了解决这个问题,ORM一般也支持写raw sql。
3 通过QuerySet的query属性查询对应操作的sql语句
|
1
2
|
author_obj=models.Author.objects.filter(id=2)print(author_obj.query) |
下面要开始学习Django ORM语法了,为了更好的理解,我们来做一个基本的 书籍/作者/出版商 数据库结构。 我们这样做是因为 这是一个众所周知的例子,很多SQL有关的书籍也常用这个举例。
表(模型)的创建:
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名。
作者详细模型:把作者的详情放到详情表,包含性别,email地址和出生日期,作者详情模型和作者模型之间是一对一的关系(one-to-one)(类似于每个人和他的身份证之间的关系),在大多数情况下我们没有必要将他们拆分成两张表,这里只是引出一对一的概念。
出版商模型:出版商有名称,地址,所在城市,省,国家和网站。
书籍模型:书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many),一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many),也被称作外键。
View Code注意1:记得在settings里的INSTALLED_APPS中加入'app01',然后再同步数据库。
注意2: models.ForeignKey("Publish") & models.ForeignKey(Publish)
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。大家可以留意下其它的类型都和数据库里的什么字段对应。
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
<4> 模型常用的字段类型参数
View Code<5> Field重要参数
View Code表的操作(增删改查):
-------------------------------------增(create , save) -------------------------------

from app01.models import *
#create方式一: Author.objects.create(name='Alvin')
#create方式二: Author.objects.create(**{"name":"alex"})
#save方式一: author=Author(name="alvin")
author.save()
#save方式二: author=Author()
author.name="alvin"
author.save()
重点来了------->那么如何创建存在一对多或多对多关系的一本书的信息呢?(如何处理外键关系的字段如一对多的publisher和多对多的authors)
View Code-----------------------------------------删(delete) ---------------------------------------------
>>> Book.objects.filter(id=1).delete()
(3, {'app01.Book_authors': 2, 'app01.Book': 1})
我们表面上删除了一条信息,实际却删除了三条,因为我们删除的这本书在Book_authors表中有两条相关信息,这种删除方式就是django默认的级联删除。
如果是多对多的关系: remove()和clear()方法:
#正向 book = models.Book.objects.filter(id=1) #删除第三张表中和女孩1关联的所有关联信息 book.author.clear() #清空与book中id=1 关联的所有数据 book.author.remove(2) #可以为id book.author.remove(*[1,2,3,4]) #可以为列表,前面加* #反向 author = models.Author.objects.filter(id=1) author.book_set.clear() #清空与boy中id=1 关联的所有数据
-----------------------------------------改(update和save) ----------------------------------------
实例:
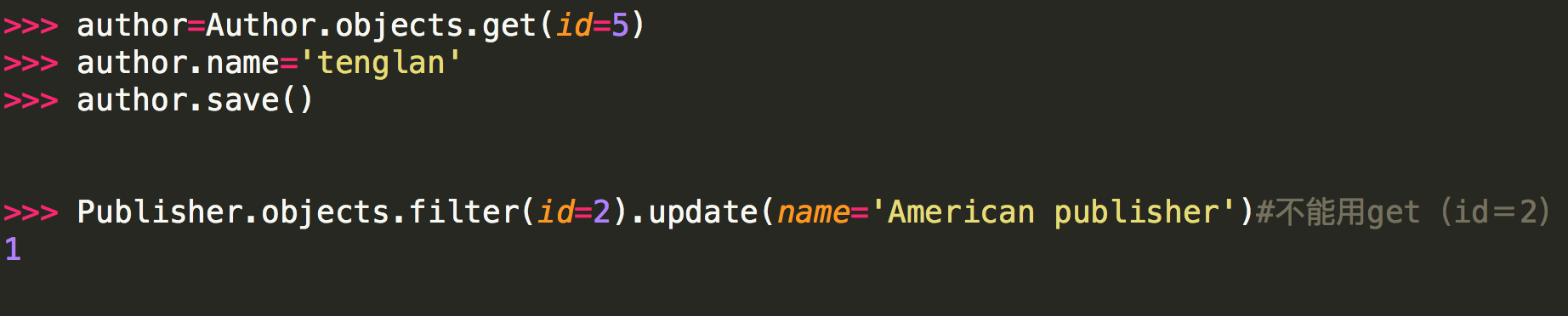
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
View Code在这个例子里我们可以看到Django的save()方法更新了不仅仅是title列的值,还有更新了所有的列。 若title以外的列有可能会被其他的进程所改动的情况下,只更改title列显然是更加明智的。更改某一指定的列,我们可以调用结果集(QuerySet)对象的update()方法,与之等同的SQL语句变得更高效,并且不会引起竞态条件。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING注意:如果是多对多的改:
obj=Book.objects.filter(id=1)[0]
author=Author.objects.filter(id__gt=2)
obj.author.clear()
obj.author.add(*author)
---------------------------------------查(filter,value等) -------------------------------------
---------->查询API:
View Code补充:
extra---------->惰性机制:
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
View CodeQuerySet的高效使用:
View Code---------->对象查询,单表条件查询,多表条件关联查询
View Code注意:条件查询即与对象查询对应,是指在filter,values等方法中的通过__来明确查询条件。
---------->聚合查询和分组查询
<1> aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
View Code<2> annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors__name

查询各个出版社最便宜的书价是多少

---------->F查询和Q查询
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
View Coderaw sql
django中models的操作,也是调用了ORM框架来实现的,pymysql 或者mysqldb,所以我们也可以使用原生的SQL语句来操作数据库!
九 admin的配置
admin是django强大功能之一,它能共从数据库中读取数据,呈现在页面中,进行管理。默认情况下,它的功能已经非常强大,如果你不需要复杂的功能,它已经够用,但是有时候,一些特殊的功能还需要定制,比如搜索功能,下面这一系列文章就逐步深入介绍如何定制适合自己的admin应用。
如果你觉得英文界面不好用,可以在setting.py 文件中修改以下选项
|
1
|
LANGUAGE_CODE = 'en-us' #LANGUAGE_CODE = 'zh-hans' |
一 认识ModelAdmin
管理界面的定制类,如需扩展特定的model界面需从该类继承。
二 注册medel类到admin的两种方式:
<1> 使用register的方法
|
1
|
admin.site.register(Book,MyAdmin) |
<2> 使用register的装饰器
|
1
|
@admin.register(Book) |
三 掌握一些常用的设置技巧
- list_display: 指定要显示的字段
- search_fields: 指定搜索的字段
- list_filter: 指定列表过滤器
- ordering: 指定排序字段
from django.contrib import admin
from app01.models import *
# Register your models here.
# @admin.register(Book)#----->单给某个表加一个定制
class MyAdmin(admin.ModelAdmin):
list_display = ("title","price","publisher")
search_fields = ("title","publisher")
list_filter = ("publisher",)
ordering = ("price",)
fieldsets =[
(None, {'fields': ['title']}),
('price information', {'fields': ['price',"publisher"], 'classes': ['collapse']}),
]
admin.site.register(Book,MyAdmin)
admin.site.register(Publish)
admin.site.register(Author)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号