爬虫中的Header请求头 在浏览器中通过F12和F5分析
转(https://blog.csdn.net/weixin_43797908/article/details/84790896)
很多网站再申请访问的时候没有请求头访问会不成功,或者返回乱码,最简单的解决方式就是伪装成浏览器进行访问,这就需要添加一个请求头来伪装浏览器行为

**
Header
**
请求头可以自己来写,其实很简单
打开任意浏览器某一页面(要联网),按f12,然后点network,之后再按f5,然后就会看到“name”这里,我们点击name里面的任意文件即可。
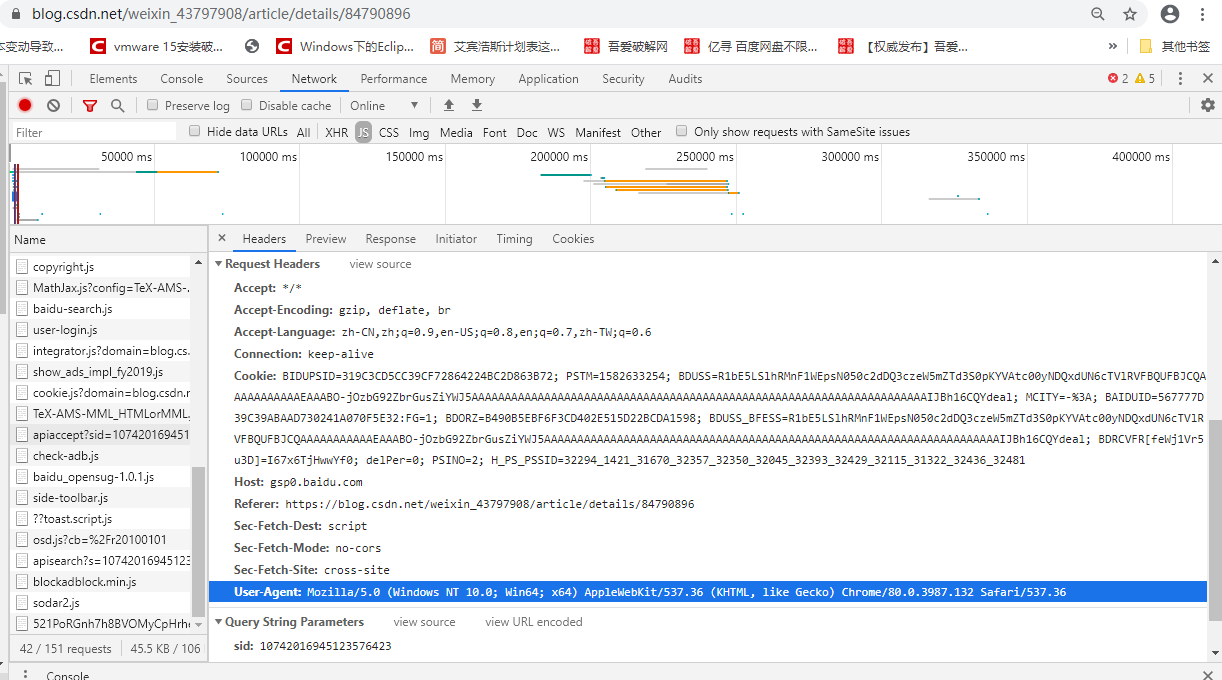
之后右边有一个headers,点击headers找到request headers,这个就是浏览器的请求报头了

然后复制其中的user-agent,其他的cookie还有Accept可以要也可以不要,主要是伪装成浏览器,所以我就用了user-agent
直接粘贴到代码中运行成功

您的资助是我最大的动力!
金额随意,欢迎来赏!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)