双样本T检验、F检验——机器学习中样本中的某个特征(自变量)和因变量之间的相关性强弱
我认为T检验 和F检验在机器学习中的作用:判断机器学习中样本集中的某个特征(自变量)和因变量之间的相关性强弱(用于在建模中判断此自变量是否可以扔掉)
最近在做数据分析方面的工作,经常需要检验两组样本之间是否存在差异,所以会遇到统计学中假设检验相关的知识。在机器学习特征工程这一步,笔者最常用到的是假设检验中的卡方检验去做特征选择,因为卡方检验可以做两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。但是笔者今天想介绍一下通过T检验做机器学习中的特征工程,希望能够让大家初步了解到各种假设检验是如何在机器学习项目的特征工程发挥作用。
1、理论部分假设检验简介
统计学中,常见的假设检验有:T检验(Student's t Test),F检验(方差齐性检验),卡方验证等。无论任何假设检验,它们都遵循如下图所示的流程:
- 做两个假设:一般如果假设对象是两组样本的话(一组数据集中有多个特征,选择其中的两个特征,就是指的这里说的两组样本),都会假设这两组样本(其实也就是指的是样本数据中的两个特征值)均值相等,(T检验的假设),方差满足齐次性(F检验的假设)等。而另一个假设其实就是两组样本均值不相等(T检验的假设),方差不满足齐次性(F检验的假设)等,其实这两个假设就是一对非此即彼的选项。这两个假设在教科书上就叫做原假设
,和备择假设
。
- 设置一个显著性值:通俗点理解,就是如果真实的情况偏离原假设的程度。
1.如果真实情况和原假设差异不大(P值高于显著性值),那证明原假设是对的,接受原假设。
2.如果真实情况和原假设差异太大(P值低于显著性值),那证明原假设错了,我们得拒绝原假设,接受备择假设。
显著性值的选择是个经验值:一般和样本量有关,样本量越大,显著性值越大,一般几百左右的样本量P值一般选择0.05,样本量在两千左右时P值一般选择0.001,样本量再大,P值就没有作用了,所以做假设检验时样本量一般不会超过5千,样本量超过5千时P值就没什么意义了。 - 收集证据:用手头的数据去验证第一步定义的假设。这一步就是对样本进行统计计算等操作。
- T检验得到结论:结论一般不外乎这两种:
1.如果P>0.05(上方第二步设定的显著性的值),原假设成立;
2.如果P< 0.05(上方第二步设定的显著性的值),原假设不成立,备择假设成立。
假设检验
假设检验与特征相关性分析
熟悉机器学习的同学都知道,特征X和目标Y的数值类型经常会出现两类:1. 连续型数值,2. 离散性数值(类别特征可以编码成离散型特征)。
特征X和目标Y在不同数值类型的组合下,应该采用不同的假设检验手段去做特征相关性分析。下图罗列了特征X和目标Y在各种数值类型组合时最适合的假设检验方法。
 假设检验和特征相关分析对照表
假设检验和特征相关分析对照表T检验简介
T检验分单样本T检验和双样本T检验,单样本T检验检验的是样本的均值是否能代表总体的均值。双样本T检验检验的是两个独立样本所代表的总体数据均值差异是否显著。换句话说就是检验两个总体是否是存在差异。双样本T检验适用条件如下:
- 两样本均来自于正态总体
- 两样本相互独立
- 满足方差齐性,方差齐次性指的是样本的方差在一个数量级水平上(通过方差齐性检验)
接下来按照假设检验流程:
1.原假设:两个独立样本所代表的总体数据均值相同(),备择假设:两个独立样本所代表的总体数据均值不相同(
);
2.P值定为0.05;
3.计算两组样本的均值,标准差然后带入下图所示的公式后求得t值,然后查T检验表得到P值。其中 和
分别指这两组样本的均值,
和
分别代表两组样本的标准差,
和
分别代表两组样本的样本量;
4.如果P< 0.05,则两组数据均值不同,数据间存在差异,如果P> 0.05,则两组数据均值相同。

2、双样本T检验特征相关性分析实战
数据载入
导入必要的python包和数据集,这里笔者用的是boston房价预测的数据集。
from scipy import stats import pandas as pd from sklearn.datasets import load_boston data_value = load_boston().data data_target = load_boston().target feature = load_boston().feature_names data = pd.DataFrame({ i:j for i, j in zip(feature, [data_value[:,index] for index in range(len(feature))])}) data["Price"] = data_target
数据大致如下图所示,其中Price列是预测值Y,其他列都是特征X列,根据上文假设检验和特征相关分析对照表,我们发现如果X和Y中一个为二分类数值类型时,一个为连续数值类型时即可以使用双样本T检验。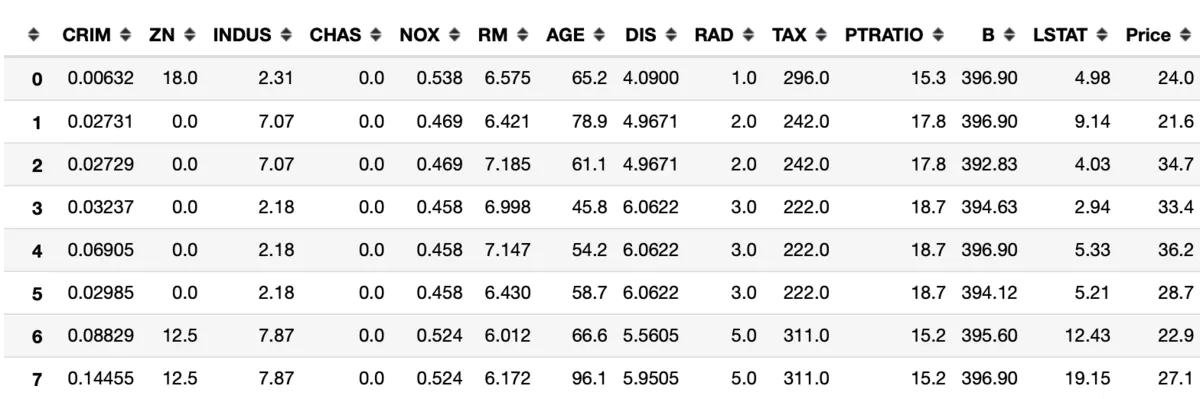
data
下图显示CHAS这列是二分类数值类型,506个样本中CHAS = 0的有471个样本,CHAS = 1的有35个样本,而boston 房价预测数据中Price是连续数值类型,所以我们可以采用双样本T检验去检验CHAS(0或者1)的不同是否会对房价有影响,换句话说就是去检验CHAS这列特征和房价是否有关联。
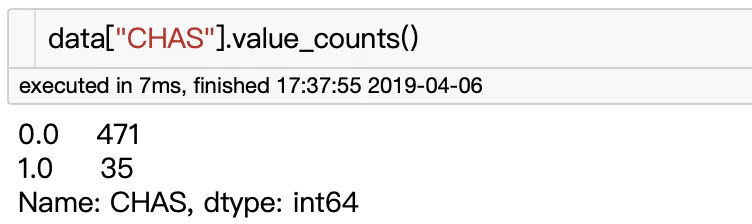
CHAS的统计结果
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
下面是实际的建模中 涉及到的判断因变量Y和自变量X之间相关性的实战
1)准备样本
将CHAS = 0 的房价Price 样本 和 将CHAS = 1 的房价Price 样本 分别抽取出来。
CHAS_0 = list(data[data["CHAS"]==0].Price) CHAS_1 = list(data[data["CHAS"]==1].Price)
2)方差齐次性检验
按照T检验的步骤,首先做方差齐次性检验,下方代码就是在做方差齐次性检验,一行代码,so easy。
stats.levene(CHAS_0,CHAS_1)
得到的结果如下所示:
LeveneResult(statistic=4.590342218715871,pvalue=0.03263097600633006)
这里我们只需要关注p value(上文提到的P值),P=0.03小于0.05,证明方差齐次性检验的原假设不成立,说明两组样本方差不满足齐次性。
3)双样本T检验
接着做双样本T检验,依然是一行代码。注意由于两组样本之间的方差不满足齐次性,需要加一个参数equal_var=False。此API默认为equal_var=Ture。
stats.ttest_ind(CHAS_0,CHAS_1,equal_var=False)
结果如下:
Ttest_indResult(statistic=-3.113291312794837,pvalue=0.003567170098137517)
P=0.003小于0.05,证明双样本T检验的原假设不成立,即两个总体之间的均值存在差异。
结论
下面结果显示:CHAS = 0的这一波房子的房价均值为22,而CHAS = 1的这一波房价的均值为26,说明CHAS = 1的房子比CHAS = 0的房子要贵。所以CHAS这列特征和房价还是很相关。而且T检验也证明其相关性还是很显著,所以这列特征,不能随意扔掉。

链接:https://www.jianshu.com/p/7555c4311a57
来源:简书

您的资助是我最大的动力!
金额随意,欢迎来赏!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)