hadoop之mr框架的源码理解注意点
1、reduce源码中的
GroupComparable和SecondaryComparable到底都是干什么的
理解点1:
源码位置
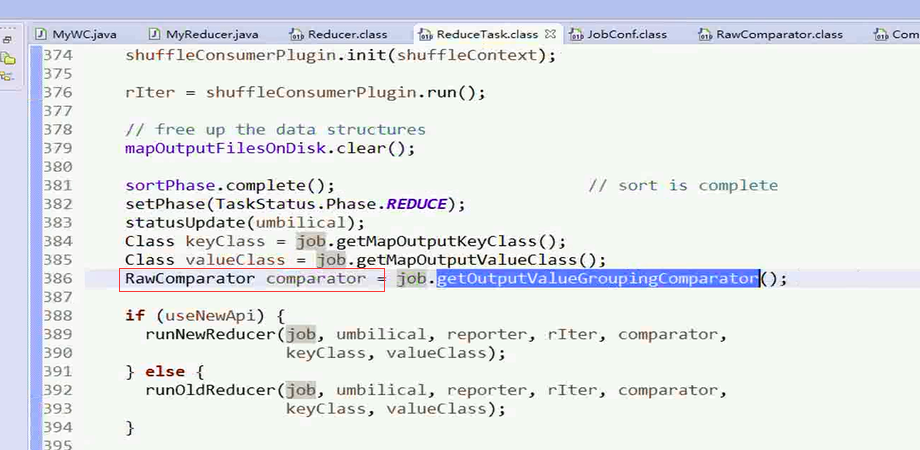
理解点
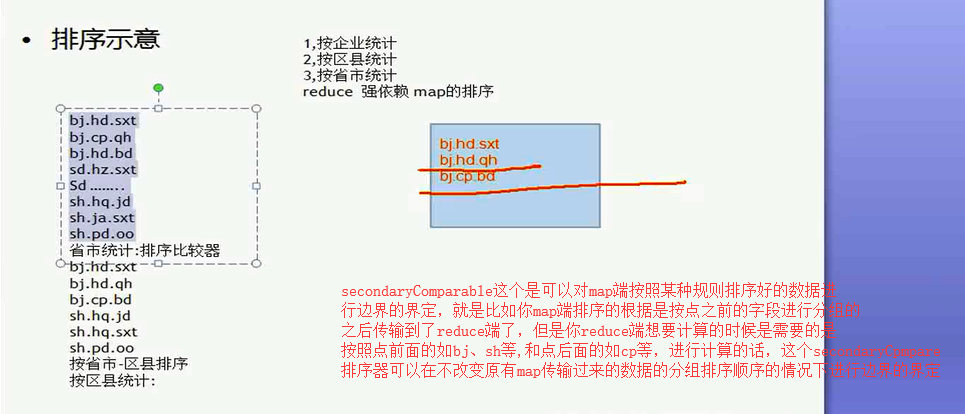
secondaryComparable这个是可以对map端按照某种规则排序好的数据进
行边界的界定,就是比如你map端排序的根据是按点之前的字段进行分组的
之后传输到了reduce端了,但是你reduce端想要计算的时候是需要的是
按照点前面的如bj、sh等,和点后面的如cp等,进行计算的话,这个secondaryCpmpare
排序器可以在不改变原有map传输过来的数据的分组排序顺序的情况下进行边界的界定
理解点2:ReduceTask.class这个类和reducer的开始关联了
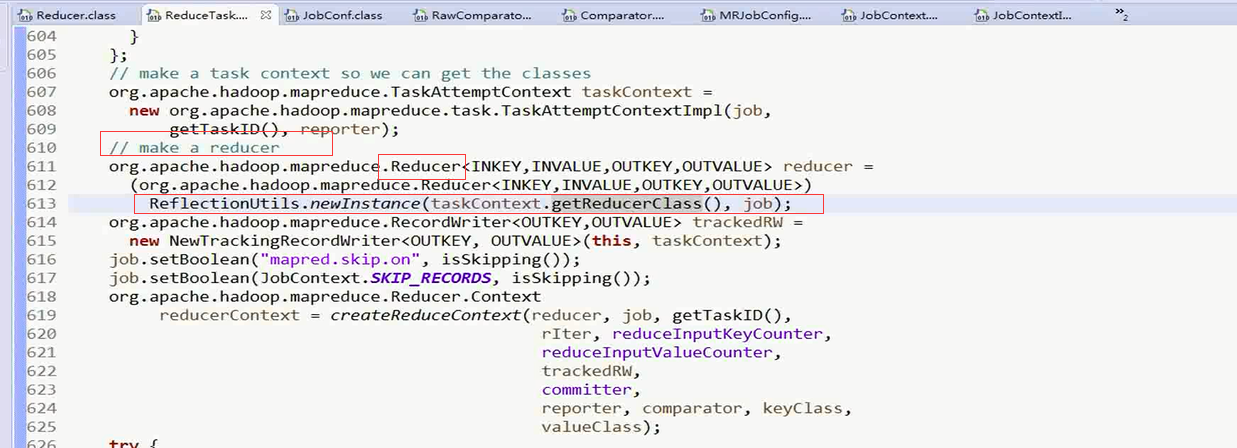
对于其中的Reducer对象的获取是通过反射实现的,可以看上面的 图片中,的ReflectionUtils.getClass()方法
这个方法调用的是JobContext中的方法
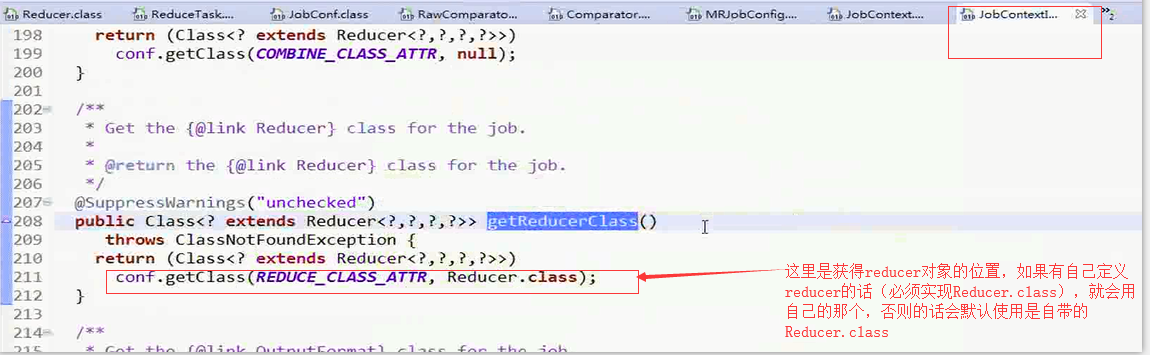
接着ReducerTask.class进行学习
RecordWriter这个是为了最后计算完毕之后向外写出结果的时候用的
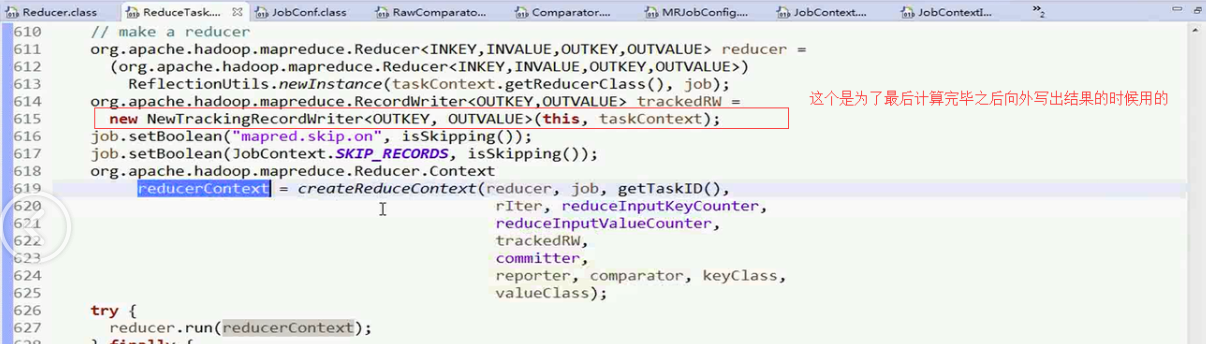
而其中的ReducerContext是为了帮助reducer完成数据迭代的一个上下文容器
具体的这个容器的创建的过程见下图

接下来进入到createReduceContext()方法
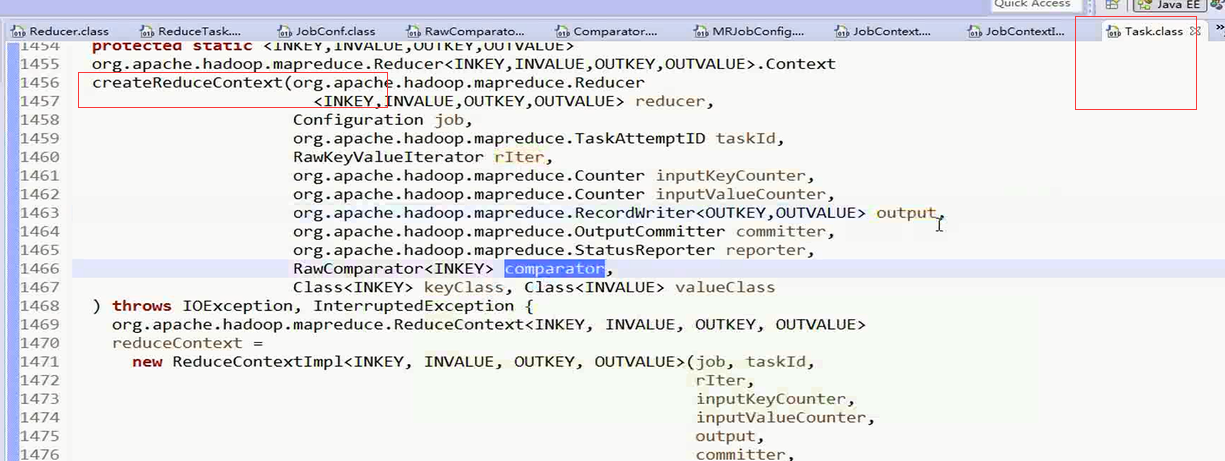
在这个方法里面初始化ReduceContext对象

下面深入源码进入ReduceContextImpl()
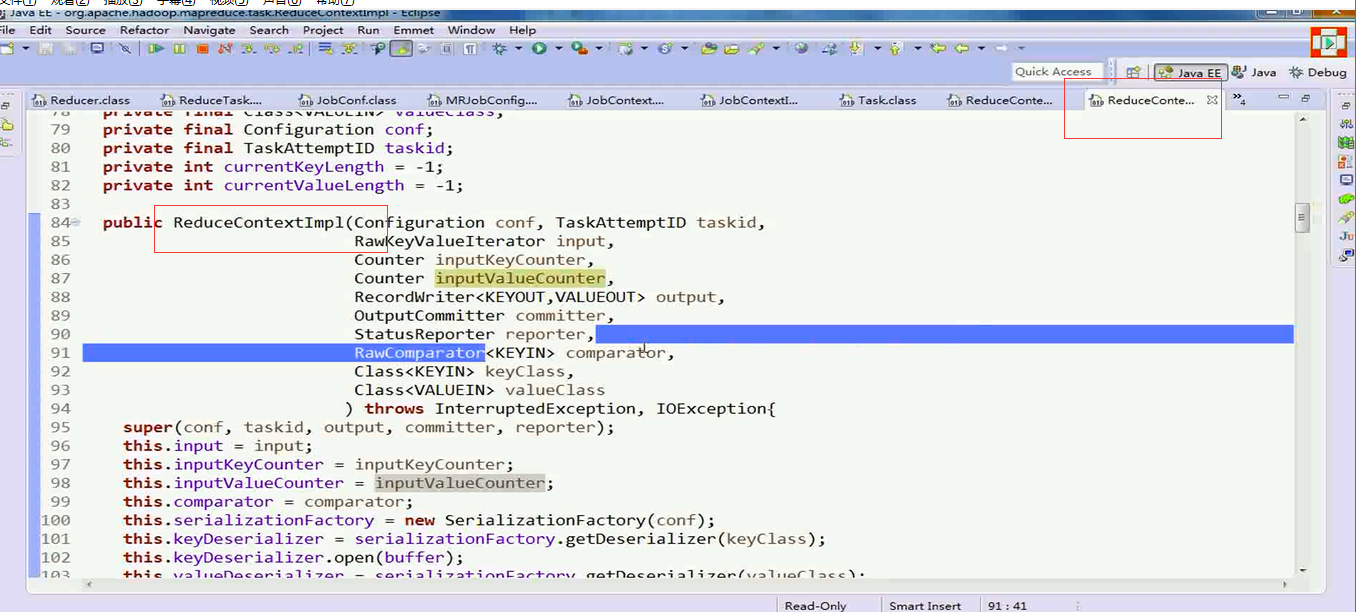
本方法中将获取的方法的参数赋值给ReduceContextimpl类的成员变量,供下面的使用
最后这个方法返回了reducerContext
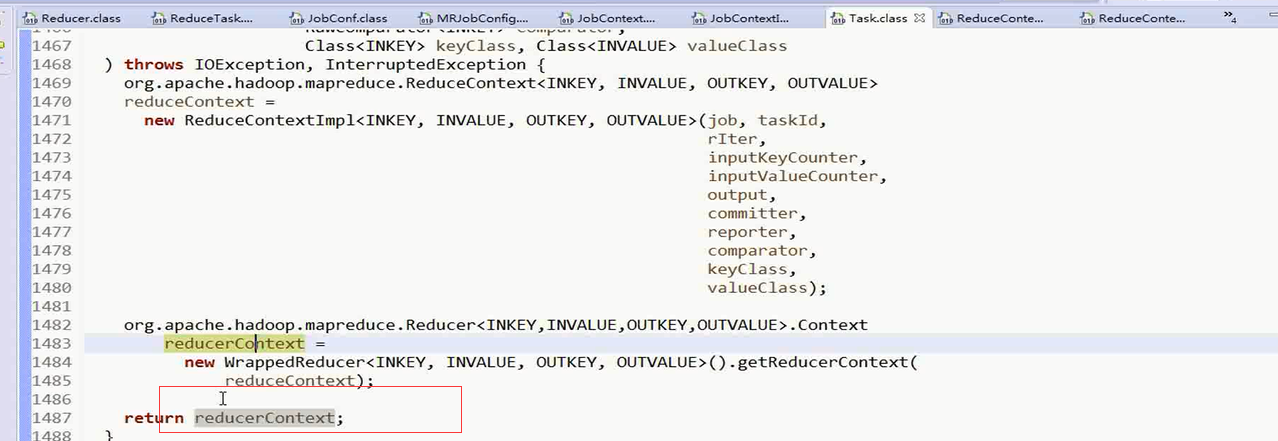
有reduceTask中的reducerContext对象来接收
之后调用自己定义的reducer或者默认的reducer.class的run()
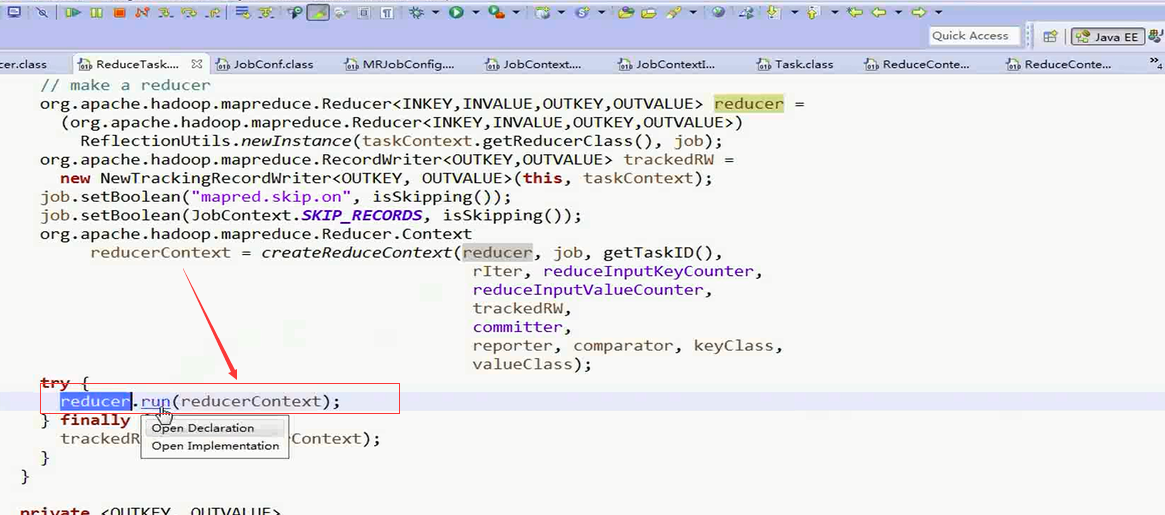
进入run方法
又跳回到Reducer.class类的run方法

接下来进入nextKey()方法
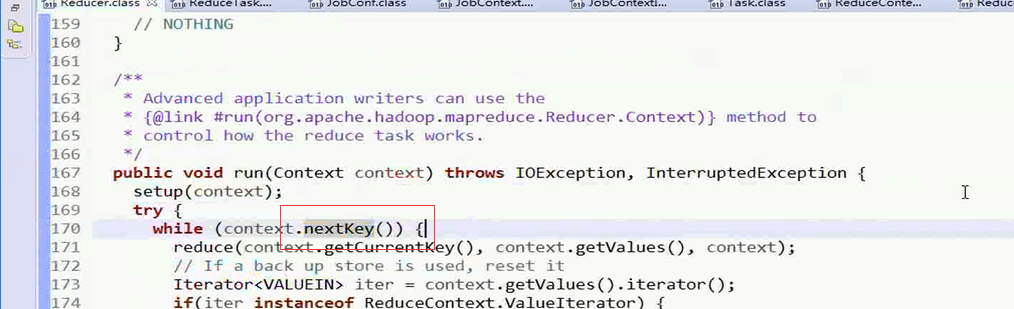
reducerContextImpl类中的nextKey()方法
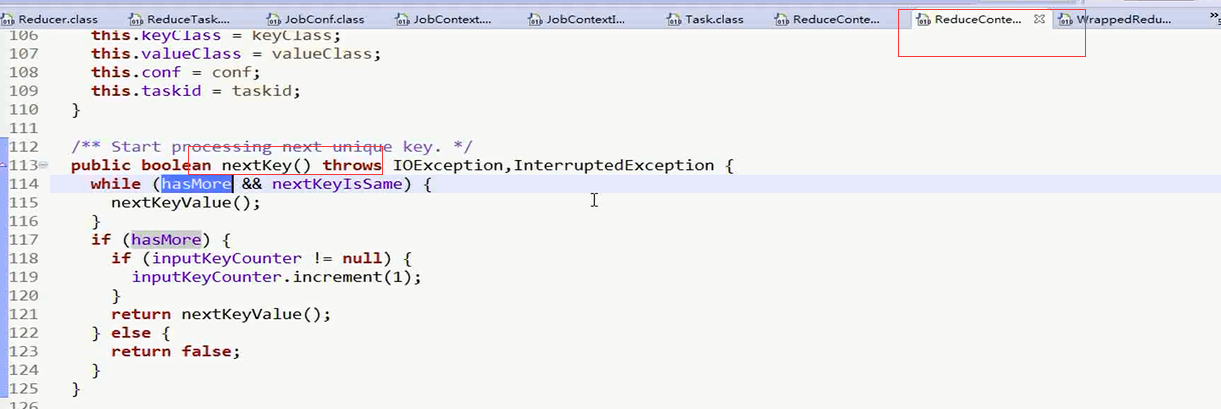
进入这个方法的nextKeyValue()
回到Reducer.class的方法,
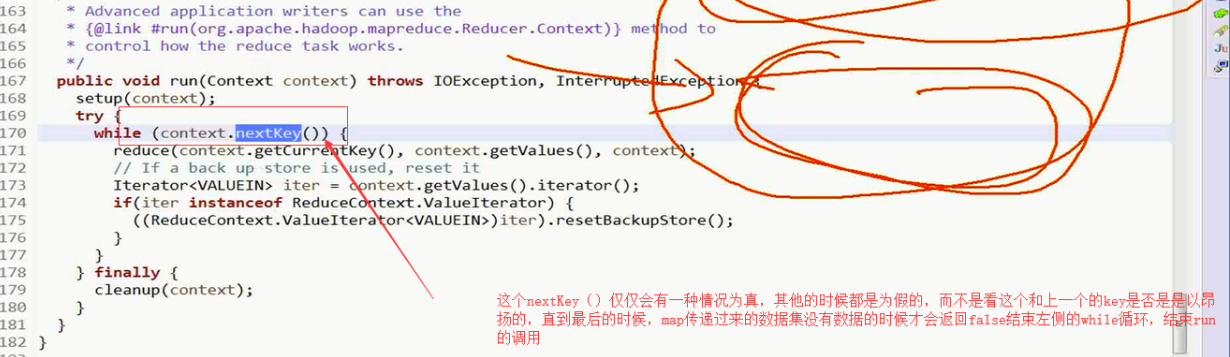
这个nextKey()仅仅会有一种情况为真,其他的时候都是为假的,而不是看这个和上一个的key是否是是以昂扬的,直到最后的时候,map传递过来的数据集没有数据的时候才会返回false结束左侧的while循环,结束run的调用
接下来看看reducer是怎么界定当前的这个reduce任务该结束了
转到自带源码中的reducer.class的run中的getVlues()方法,
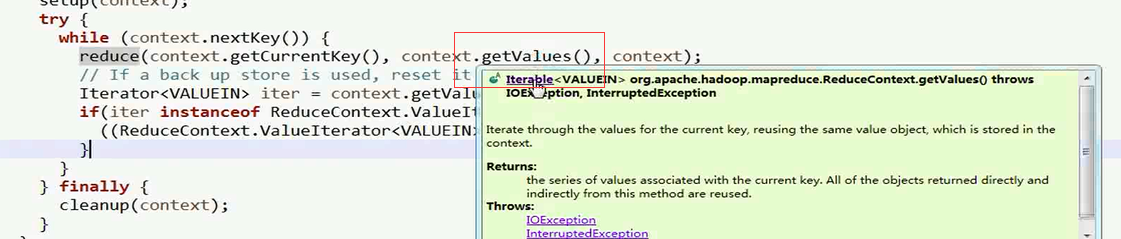
进入RecduceContextImpl类中的到getValue()方法
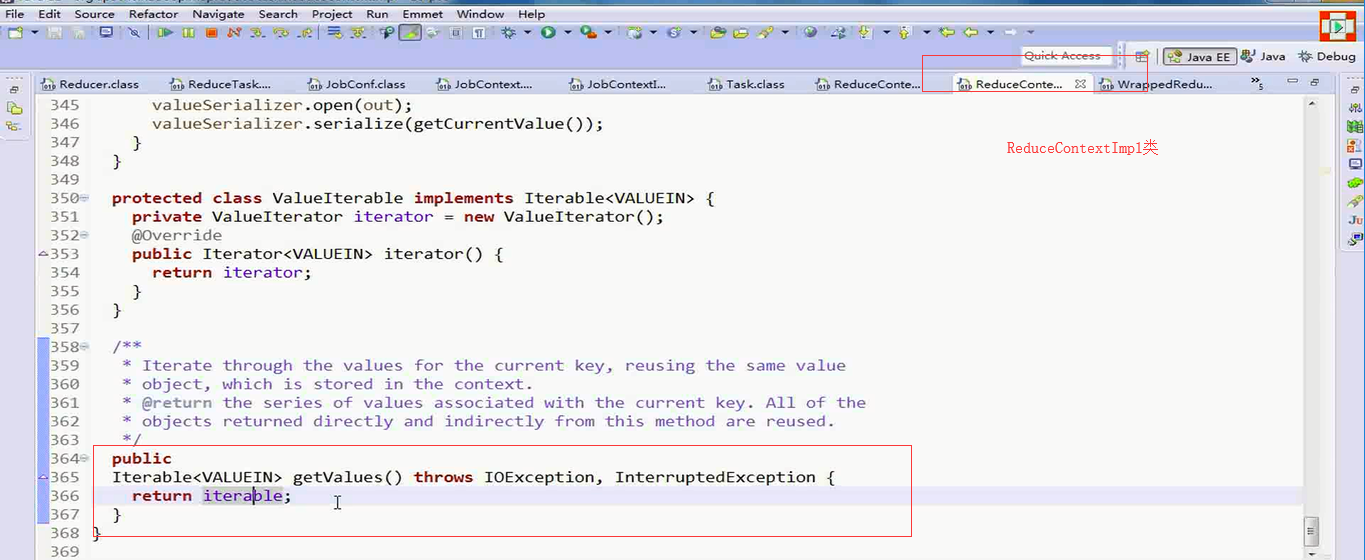
其中的迭代器的类型
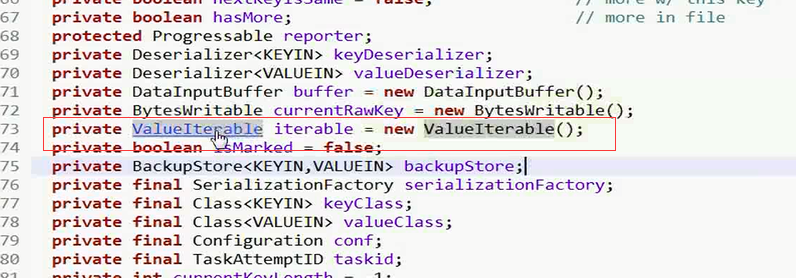
转到迭代器的源码ReduceContextImpl .class
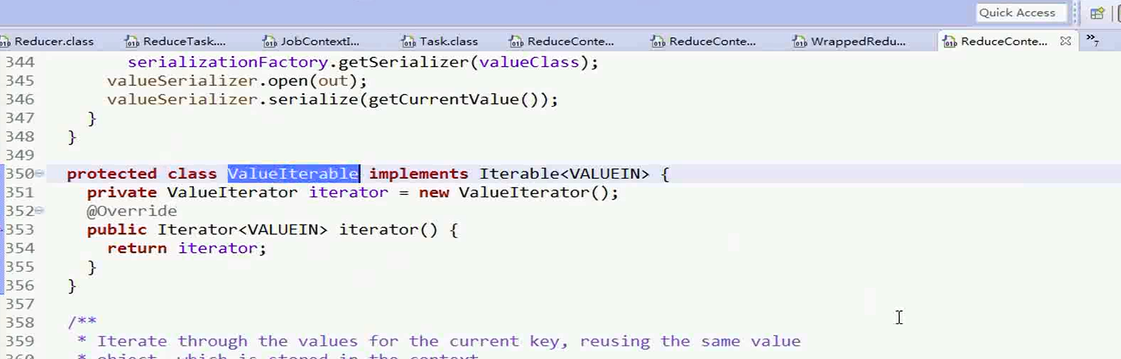
进入到ValueIterIterater类,这个类实现了Iterater接口
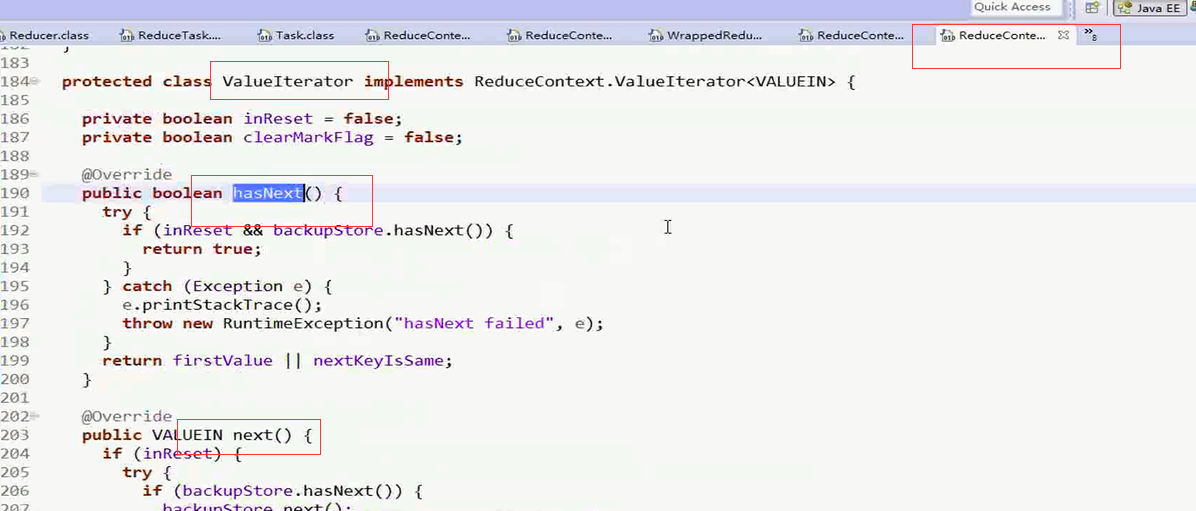
这个方法重写了Iterater中的next()方法和hasNext()方法
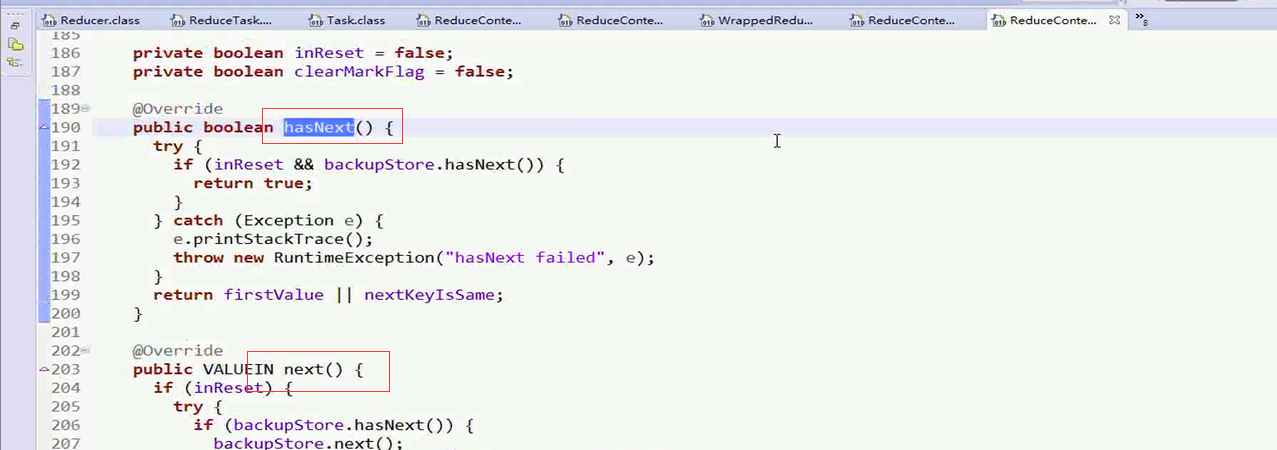
接下来回到ReduceContextImpl.class的 ValueIterator中理解这个方法中的hasNext()方法

您的资助是我最大的动力!
金额随意,欢迎来赏!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)