Hadoop学习笔记(三):分布式文件系统的写和读流程
写流程:怎么将文件切割成块,上传到服务器
读流程:怎么从不同的服务器来读取数据块
写流程
图一

图二
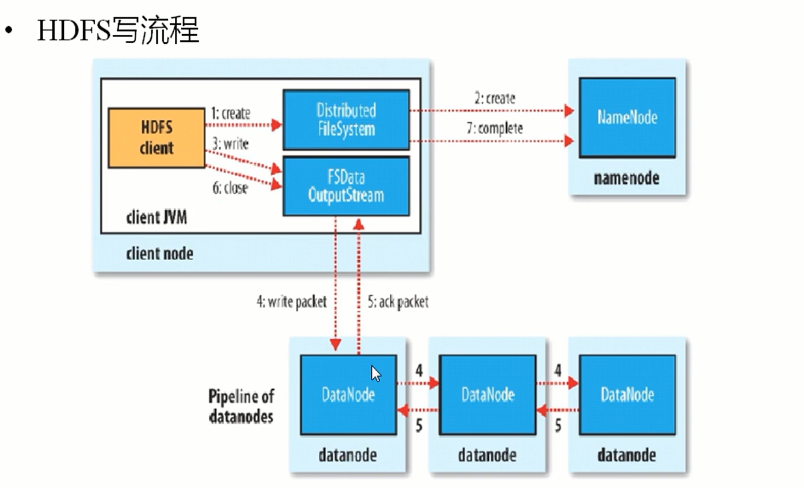
写的过程中:NameNode会给块分配存储块的位置,每次想要存储文件的时候都会在NameNode创建一个path,之后HDFSClient读取和写入数据都是先访问这个NameNode中的path去找从何处去下载文件或者上传文件到哪里,具体的NameNode怎么去分配块的存储位置根据的是图一的原则。
文件写流程的实例辅助理解:
假如我们有一个文件test.txt,想要把它放到Hadoop上,执行如下命令:
引用
# hadoop fs -put /usr/bigdata/dataset/input/20130706/test.txt /opt/bigdata/hadoop/dataset/input/20130706 //或执行下面的命令
# hadoop fs -copyFromLocal /usr/bigdata/dataset/input/20130706/test.txt /opt/bigdata/hadoop/dataset/input/20130706
整个写流程如下:
第一步,客户端调用DistributedFileSystem的create()方法,开始创建新文件:DistributedFileSystem创建DFSOutputStream,产生一个RPC调用,让NameNode在文件系统的命名空间中创建这一新文件;
第二步,NameNode接收到用户的写文件的RPC请求后,谁偶先要执行各种检查,如客户是否有相关的创佳权限和该文件是否已存在等,检查都通过后才会创建一个新文件,并将操作记录到编辑日志,然后DistributedFileSystem会将DFSOutputStream对象包装在FSDataOutStream实例中,返回客户端;否则文件创建失败并且给客户端抛IOException。
第三步,客户端开始写文件:DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。data queue会向NameNode节点请求适合存储数据副本的DataNode节点的列表,然后这些DataNode之前生成一个Pipeline数据流管道,我们假设副本集参数被设置为3,那么这个数据流管道中就有三个DataNode节点。
第四步,首先DFSOutputStream会将packets向Pipeline数据流管道中的第一个DataNode节点写数据,第一个DataNode接收packets然后把packets写向Pipeline中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向Pipeline中的第三个DataNode节点。
第五步,DFSOutputStream内部同样维护另外一个内部的写数据确认队列——ack queue。当Pipeline中的第三个DataNode节点将packets成功保存后,该节点回向第二个DataNode返回一个确认数据写成功的信息,第二个DataNode接收到该确认信息后在当前节点数据写成功后也会向Pipeline中第一个DataNode节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将packets从ack queue中将数据删除。
在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢?如果这种情况发生,那么就会执行一些操作:
首先,Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失,为存储在另一正常dataname的当前数据指定一个新的标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块;
接着,在正常的DataNode节点上的以保存好的block的ID版本会升级——这样发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,失效节点也会被从Pipeline中删除;
最后,剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。
如果Pipeline中的多个节点在写数据是发生失败,那么只要写成功的block的数量达到dfs.replication.min(默认为1),那么就任务是写成功的,然后NameNode后通过一步的方式将block复制到其他节点,最后事数据副本达到dfs.replication参数配置的个数。
第六步,,完成写操作后,客户端调用close()关闭写操作,刷新数据;
第七步,,在数据刷新完后NameNode后关闭写操作流。到此,整个写操作完成。
读流程
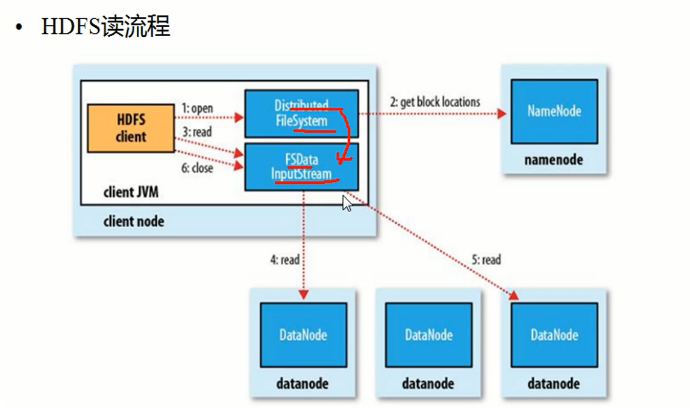
文件读流程的实例辅助理解:
Client调用FileSystem.open()方法:
1 FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有block拷贝的DN地址)。
2 选取举栗客户端最近的DN建立连接,读取block,返回FSDataInputStream。
Client调用输入流的read()方法:
1 当读到block结尾时,FSDataInputStream关闭与当前DN的连接,并未读取下一个block寻找最近DN。
2 读取完一个block都会进行checksum验证,如果读取DN时出现错误,客户端会通知NN,然后再从下一个拥有该block拷贝的DN继续读。
3 如果block列表读完后,文件还未结束,FileSystem会继续从NN获取下一批block列表。
关闭FSDataInputStream

参考链接:https://blog.csdn.net/zhang123456456/article/details/77882866,https://www.cnblogs.com/laowangc/p/8949850.html;

您的资助是我最大的动力!
金额随意,欢迎来赏!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)