wireshark抓包分析mybatis的sql参数化查询
我们使用jdbc操作数据库的时候,都习惯性地使用参数化的sql与数据库交互。因为参数化的sql有两大有点,其一,防止sql注入;其二,提高sql的执行性能(同一个connection共用一个的sql编译结果)。下面我们就通过mybatis来分析一下参数化sql的过程,以及和非参数化sql的不同。
注意:
①本次使用wireshark来监听网卡的请求,测试过程中,如果使用的是本地的mysql的话,java和mysql的交互是不需要经过wireshark的,所以如果是想用wireshark监听网卡的请求,推荐是链接远程的数据库。
②本文的项目源代码在文章末尾有链接(项目源代码中也有设计的表的sql)。
③可以结合wiereshark的抓包和mysql的general_log一起来查看sql的参数化过程,文章末尾会贴上从mysql的general_log角度检测到useServerPrepStmts=true/false两种执行方式的区别。
一开始,项目中我的db配置如下,我们就先用这个配置来测试一下。
jdbc:mysql://xxx.xxx.xxx.xxx:3306/test?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
mapper.xml如下
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mapper.UserMapper">
<select id="findByName" resultType="domain.User">
select *
from `user`
where user_id = #{name}
</select>
</mapper>
测试用例如下:
public class UserMapperTest { @Test public void findByPk() throws IOException { String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); try (SqlSession session = sqlSessionFactory.openSession()) { UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.findByName("SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8"); System.out.println(user); } } }
执行测试用例,通过wireshak监听请求,如下:

从上图wireshark抓到的数据来看,执行查询并没有使用preparestatement,也不是参数化的sql,都是把拼装好参数的sql发送到mysql执行引擎去执行,为什么呢?经过查资料发现,db配置的url配置,漏了一个属性配置分别是useServerPrepStmts,修改后的db的url配置如下:
jdbc:mysql://xxx.xxx.xxx.xxx:3306/test?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&useServerPrepStmts=true
增加了useServerPrepStmts属性配置之后,再来执行测试用例,看wireshark抓到的数据如下:
(ps.如果useServerPrepStmts=true,是通过wireshark抓包结果可以看到,先是发送Request Prepare Statement--sql模板(同一connection第一次执行改sql模板才会发送,后面就不会在发送该Request),再发送Request Execute Statement--sql参数。而useServerPrepStmts=false的话,都是清一色的Request Query,其实就是没用到mysql server的预编译功能,所以是推荐配置useServerPrepStmts=true,提高参数化sql的执行性能)
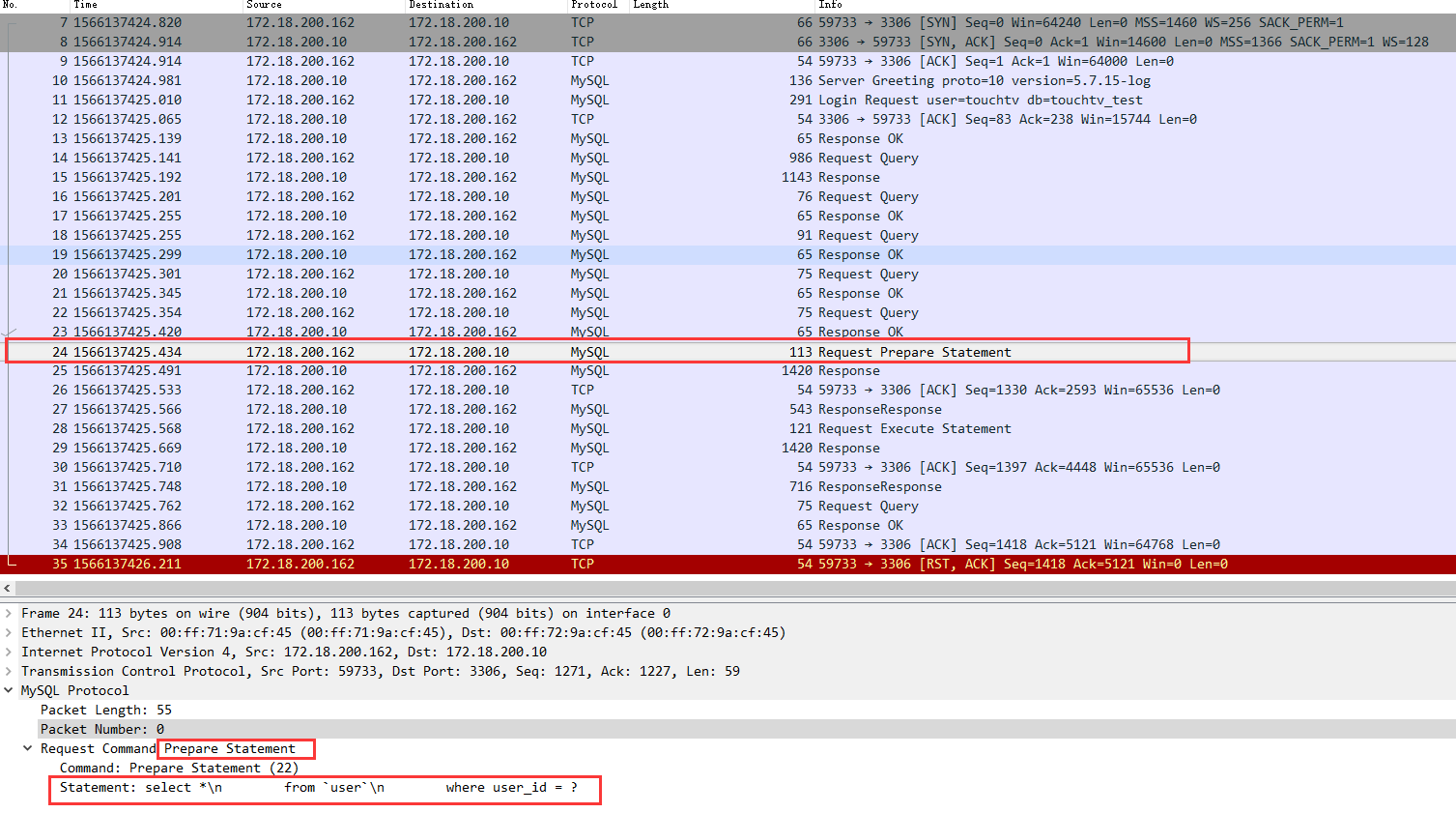
上图就是先发送待执行的sql模板(不带参数)到mysql服务端进行预编译,并且会在该请求的response中返回该sql编译之后的id,名曰:Statement ID,wireshark抓到的response数据如下:
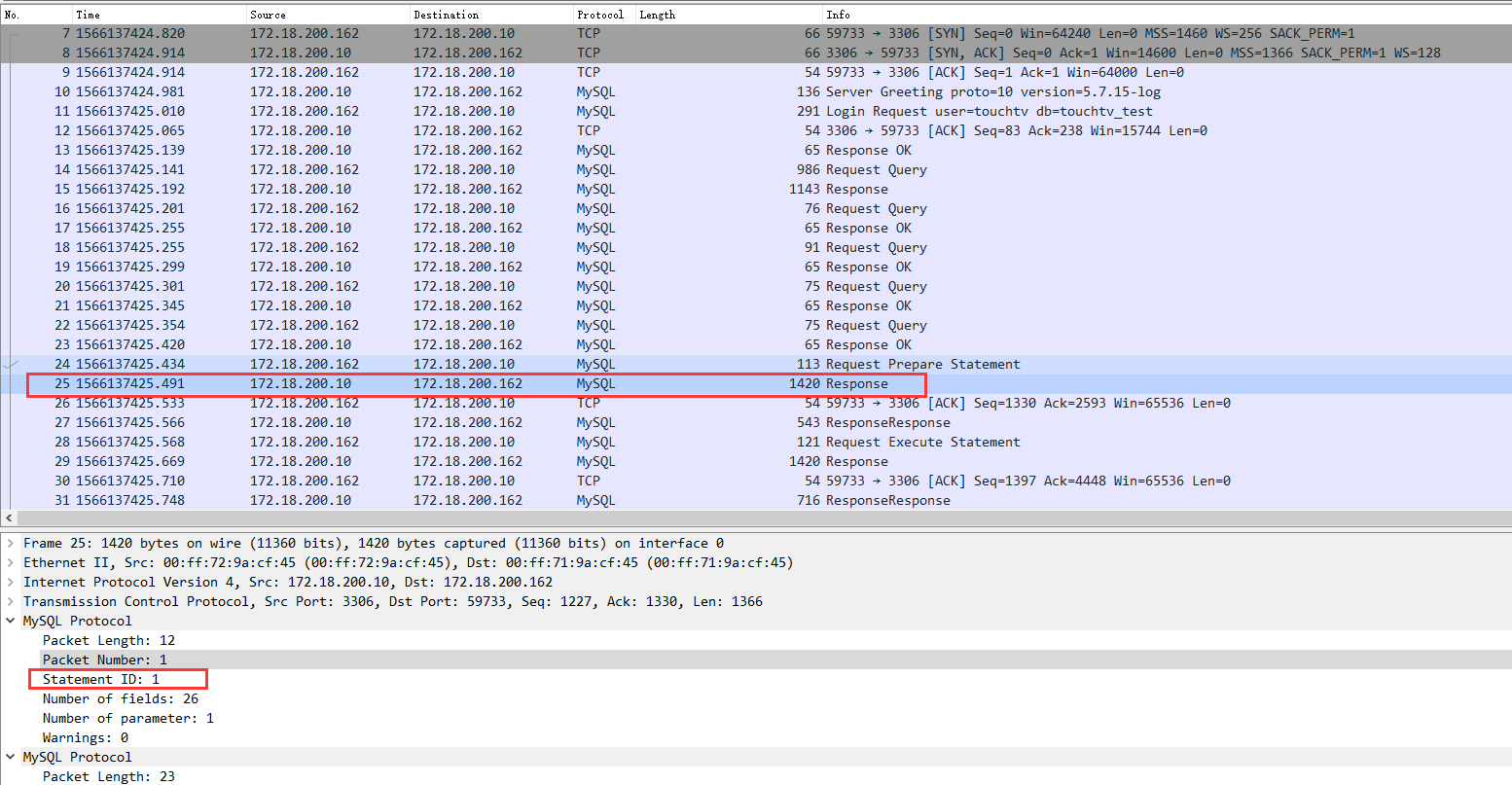
发送完sql模板之后,从response中拿到statement id之后,紧跟着就发送参数和statement id到mysql执行引擎,wireshark抓到的数据如下:
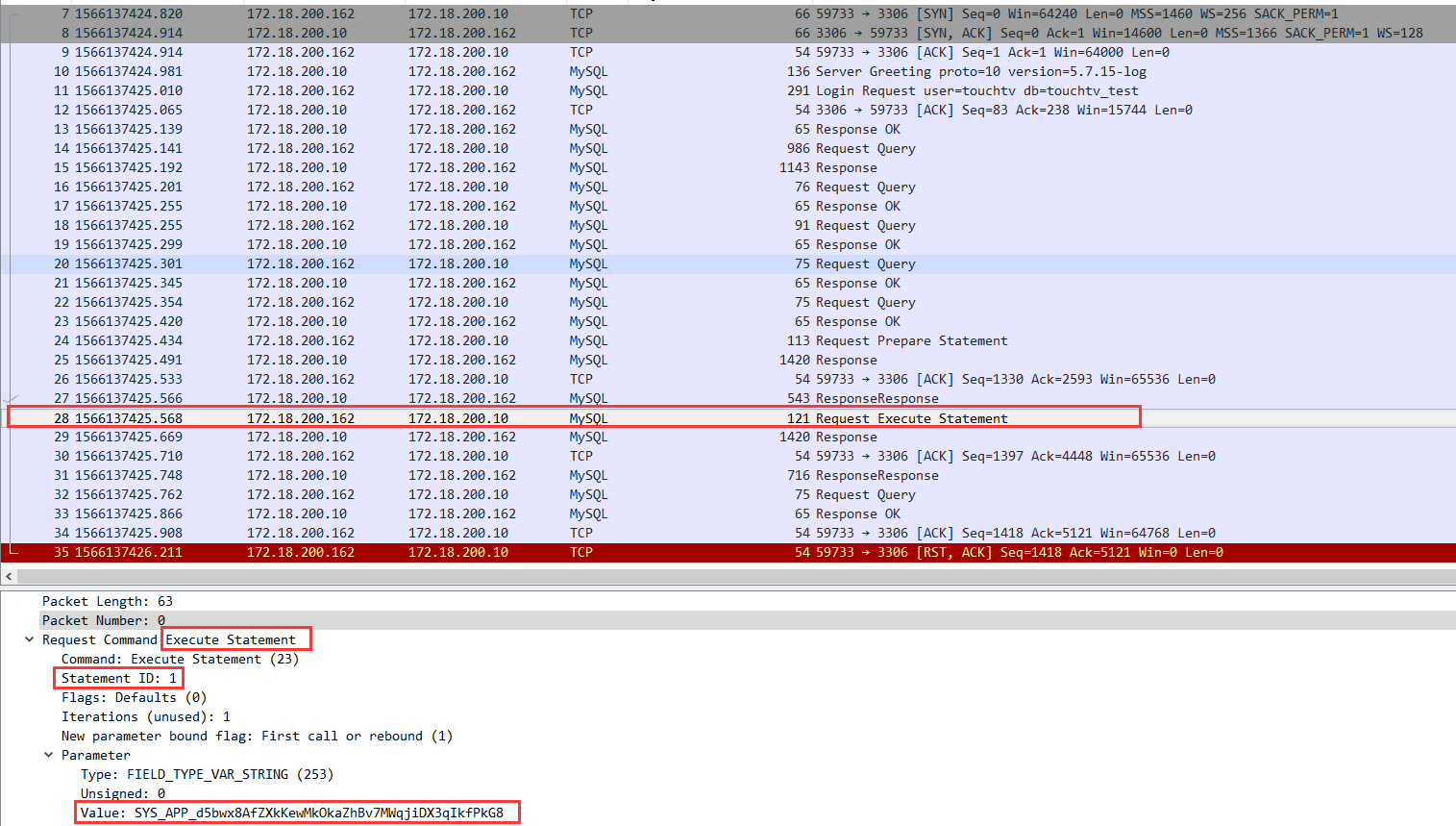
如此,便可实现sql的参数化查询。按照理解,如果此时再用此sql模板查询另外一个user_id的数据,理论上是不需要再发送sql模板到mysql服务器了的,只需要发送参数和statement ID就可以了的,下面我就试一下,测试用例如下:
@Test public void findByPk() throws IOException { String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); try (SqlSession session = sqlSessionFactory.openSession()) { UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.findByName("SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8"); if (user != null || user == null) { user = mapper.findByName("SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8"); } System.out.println(user); } }
执行测试用例,用wireshark抓包,如下:
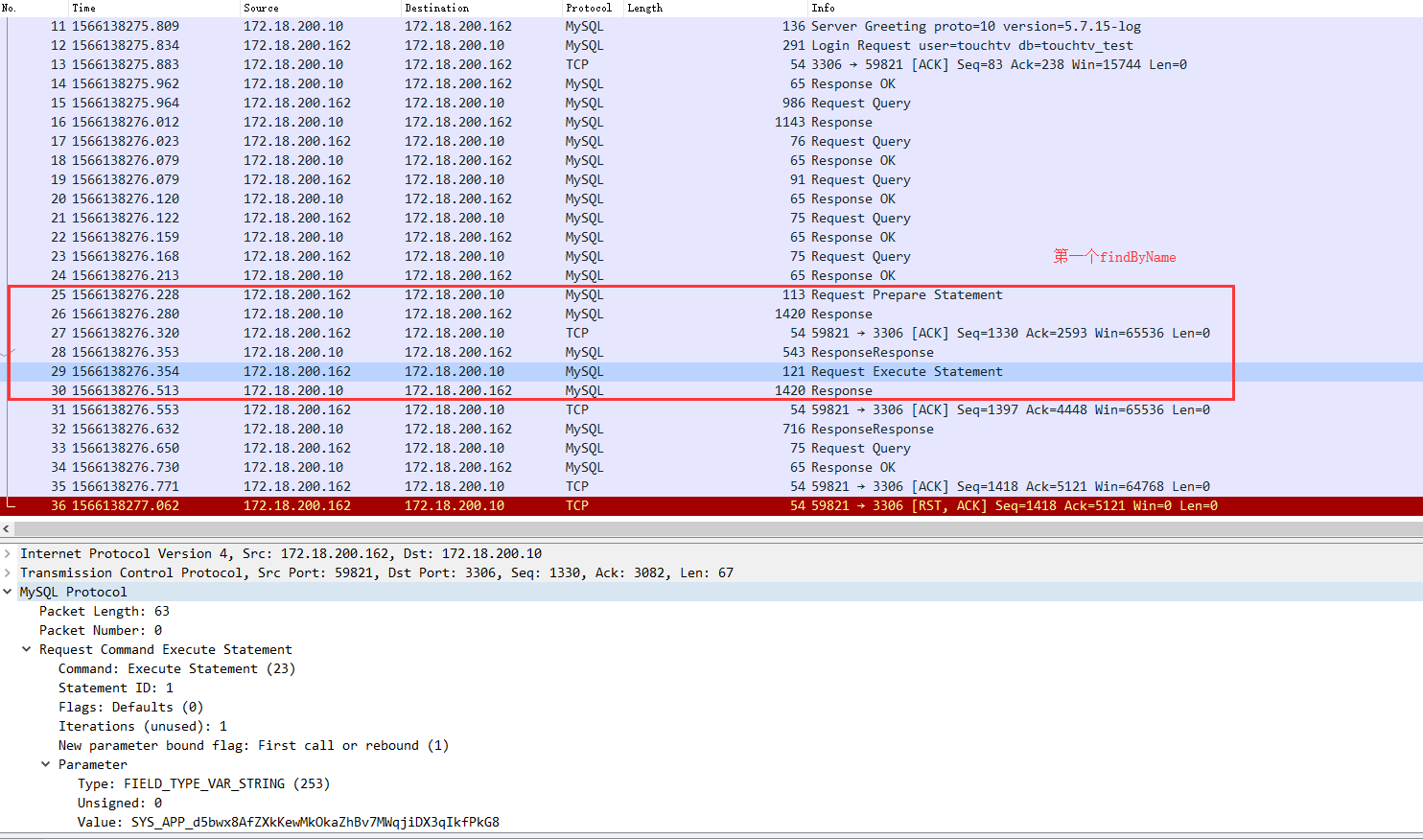
通过上图发现,怎么第二个findByName,压根就没发请求到mysql服务器,原来是因为本地的jdbc发现是相同的查询,直接返回了上一个查询的结果,所以不需要重新到mysql服务器去请求数据。那我在第二个findByName改一个和第一个不一样的参数,测试用例如下:
@Test public void findByPk() throws IOException { String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); try (SqlSession session = sqlSessionFactory.openSession()) { UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.findByName("SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8"); if (user != null || user == null) { user = mapper.findByName("SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG9"); } System.out.println(user); } }
执行上面这个测试用例,wireshark抓包结果如下:
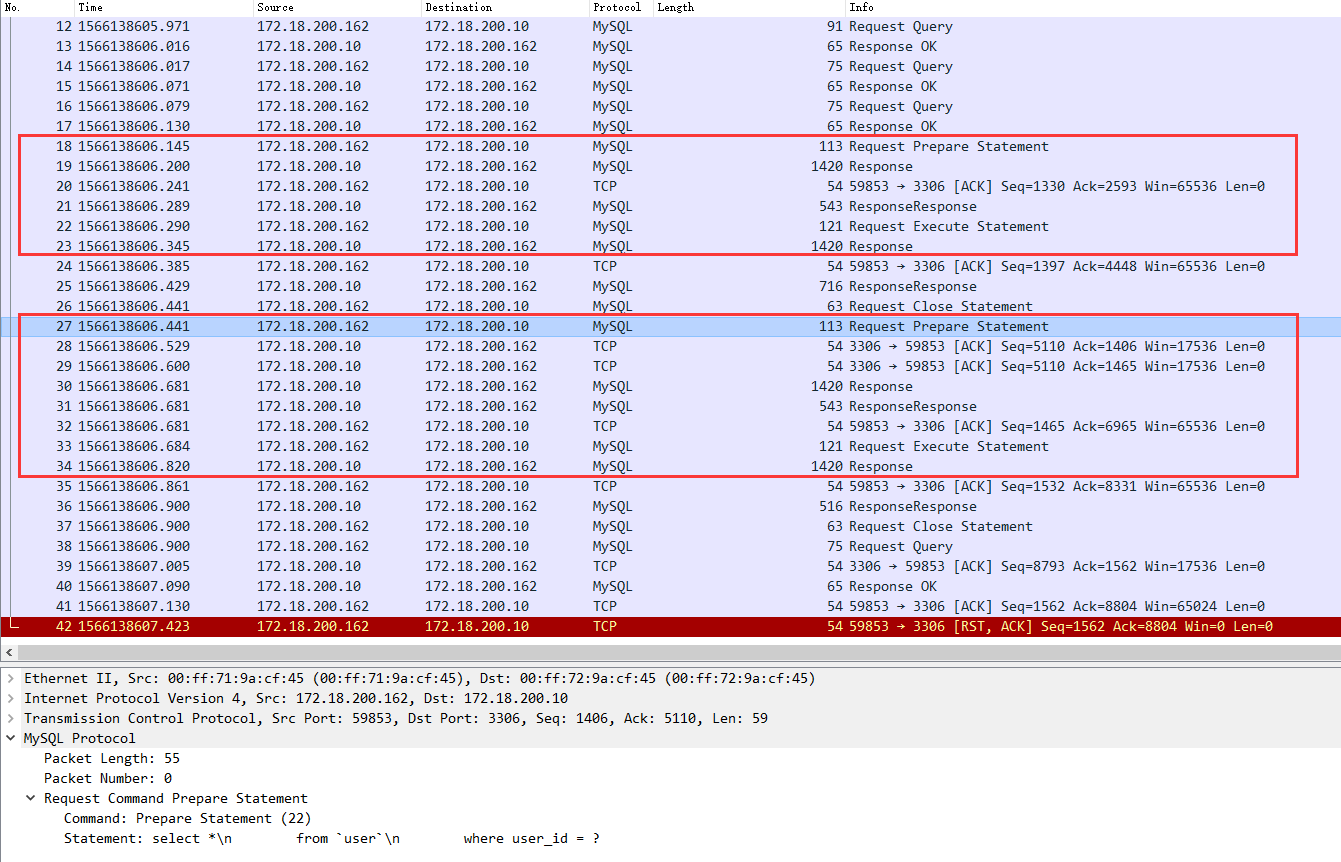
上图发现,竟然两次请求都重复发送了模板sql到mysql服务器预编译,为何呢?原来db的url配置里面还漏了一个属性配置(cachePrepStmts),增加cachePrepStmts配置之后,db的url配置如下:
jdbc:mysql://xxx.xxx.xxx.xxx:3306/test?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&useServerPrepStmts=true&cachePrepStmts=true
更新db的url配置之后,再执行测试用例,wireshark抓包结果如下:
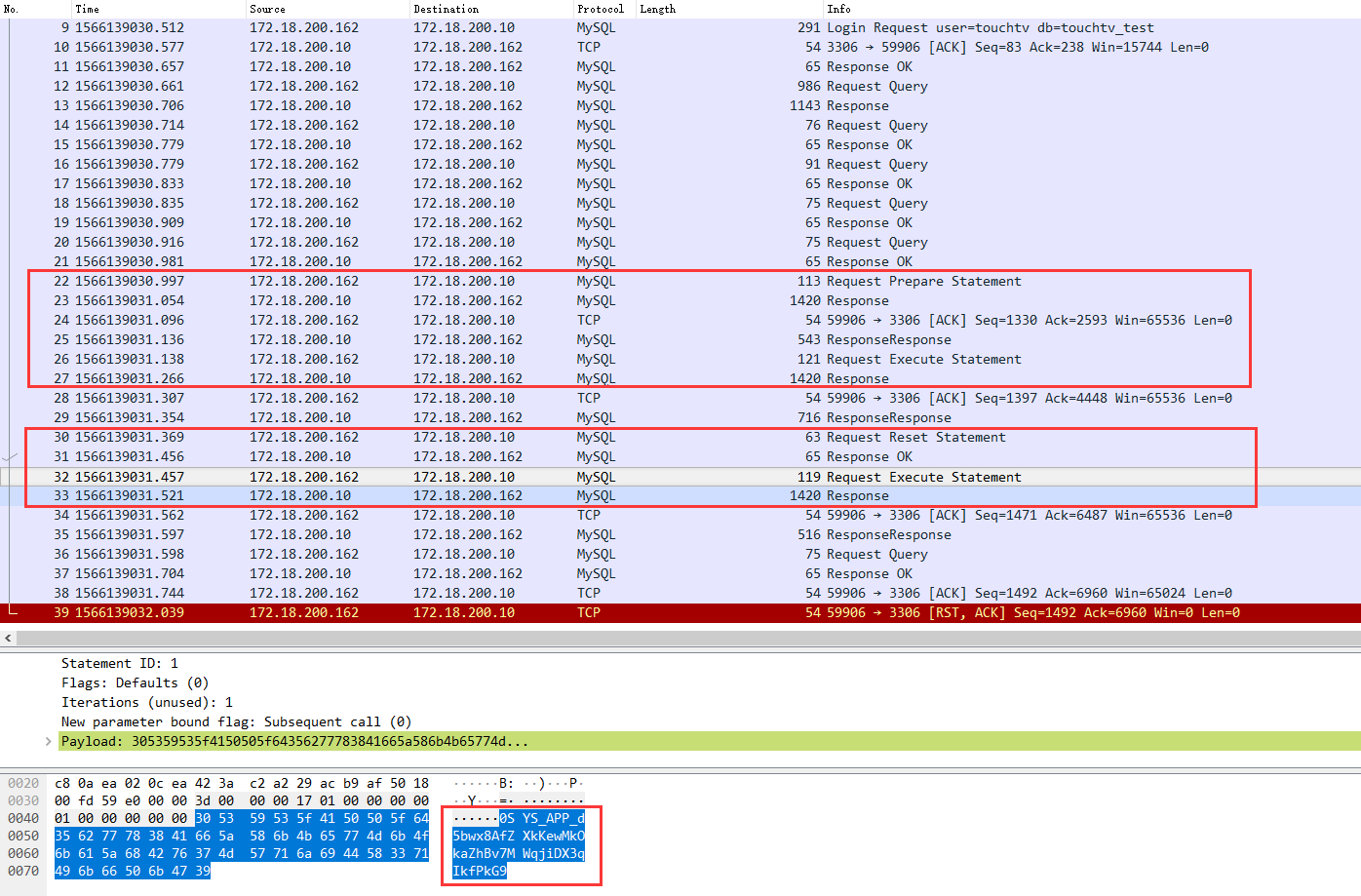
通过上图发现,第二次findByName不再发送模板sql了,直接就是发送Execute Statement了,其实Execute Statement就是执行sql的参数和statement ID(该connection第一次预编译模板sq的时候l返回的)。但是中间还是会发一个Reset Statement的mysql数据包,为什么要发这个Reset Statement数据包,有知道的同学,可以评论回复一下,我也还没去深究~谢谢~
这里附带再说一下mybatis的参数化sql可以防止sql注入的理解,其实防止sql注入,有两点,其一,mybatis本身会有一个sql参数化的过程,这里涉及到mybatis的#和$的区别,参数化sql是用#引用变量,mybatis会对参数进行特殊字符以及敏感字符的转义以防止sql注入;其二,db的url配置中加了useServerPrepStmts=true之后,mysql服务端会对Execute Statement发送的参数中涉及的敏感字符进行转义,以防止sql注入,所以,如果不加useServerPrepStmts=true的话,会发现,mybatis在本地就已经对参数中涉及的敏感字符进行了转义之后,再发往mysql server,可以使用wireshark抓包看到;但是如果是加了useServerPrepStmts=true之后,会发现client发往mysql server的参数(Execute Statement),mybatis不会对其中的参数进行转义了,参数敏感字符转义这一块交给了mysql server去做,也可以通过wireshark抓包看到。so,这里会有两块地方防止sql注入,一块在client,一块在mysql server(使用存储过程防止sql注入也是使用了mysql server的该功能),就看你是否使用useServerPrepStmts。
附录:
1.useServerPrepStmts=false/true,wireshark抓包结果
useServerPrepStmts=false,wireshark抓包结果如下:

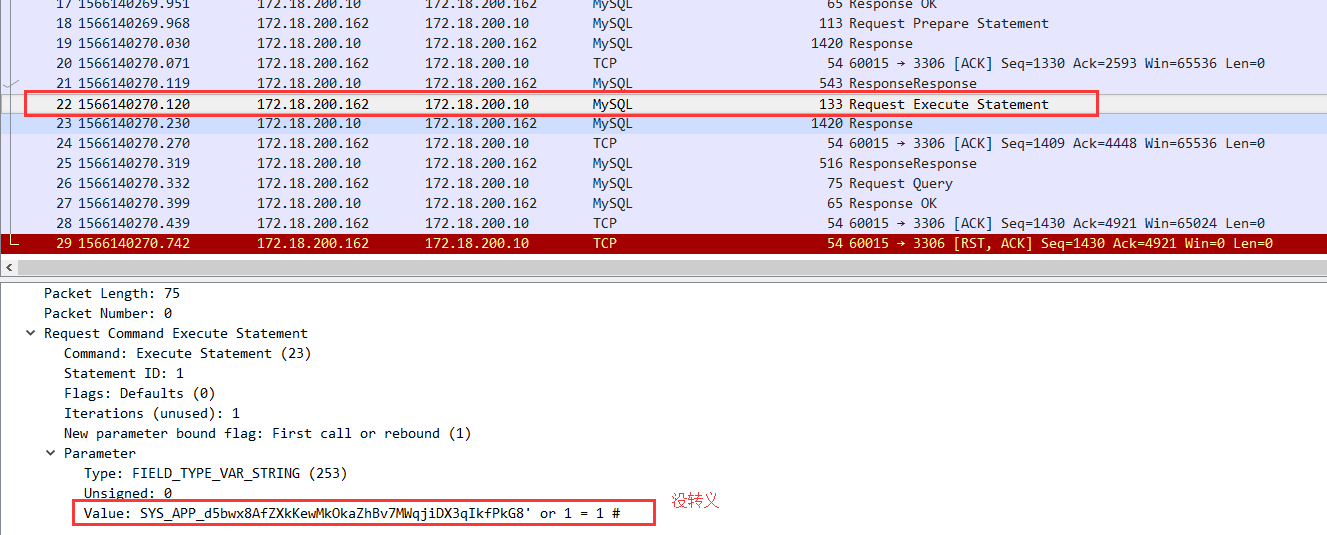
useServerPrepStmts=true,wireshark抓包结果如下:

2. mysql server的general_log角度检测到useServerPrepStmts=false/true的执行sql
useServerPrepStmts=false的general_log
2019-08-18T15:19:12.330744Z 38 Query SET autocommit=0 2019-08-18T15:19:12.345704Z 38 Query select * from `user` where user_id = 'SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8\' or 1 = 1 #' 2019-08-18T15:19:12.358669Z 38 Query select * from `user` where user_id = 'SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG9' 2019-08-18T15:19:12.359666Z 38 Query SET autocommit=1
useServerPrepStmts=true的general_log
2019-08-18T09:39:42.533289Z 30 Query SET autocommit=0 2019-08-18T09:39:42.546254Z 30 Prepare select * from `user` where user_id = ? 2019-08-18T09:39:42.550244Z 30 Execute select * from `user` where user_id = 'SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG8\' or 1 = 1 #' 2019-08-18T09:39:42.560217Z 30 Reset stmt 2019-08-18T09:39:42.561214Z 30 Execute select * from `user` where user_id = 'SYS_APP_d5bwx8AfZXkKewMkOkaZhBv7MWqjiDX3qIkfPkG9' 2019-08-18T09:39:42.563210Z 30 Query SET autocommit=1
最后,附上上面的测试用例:https://download.csdn.net/download/ismallboy/11577637

 浙公网安备 33010602011771号
浙公网安备 33010602011771号