word2vec 论文讲解 - b站深度之眼
https://www.bilibili.com/video/BV1A7411u7zh?p=4&vd_source=db1f7cb82e86cfc9050cdc20ec10c8ab
前置知识
- one-hot
- SVD(Singular Value Decomposition) 奇异值分解
- Distributed Representation 分布式表示/稠密表示
- Word Embedding 词向量/词嵌入
- 意义:
- 衡量词相似程度,词类比(中国-北京)
- 作为预训练任务提升其他任务效果
- N-gram模型, https://zhuanlan.zhihu.com/p/32829048
前置知识
-
语言模型概念:
- 衡量一个句子是句子的概率,的模型。
-
基于专家语法规则的语言模型:
- 不够通用
-
统计语言模型:

-
2个问题:
- 没有出现过的语料;
- 句子太长
-
平滑操作: laplace 加一平滑
-
平滑之后的问题:
- 参数空间过大,解决方案:马尔可夫假设
- 数据稀疏严重
-
评价指标:
- 困惑度:句子概率越大,困惑度越小
对比方法
-
NNLM(neural network language model):
-
根据前n-1单词预测第n个单词概率,concat-hidden-softmax-output层
-
优化:使得输出单词概率最大
-
输入层:1 x V的句子,乘以V x D的矩阵,得到的1 x D的向量,其实one-hot对应的那一个下标就是V x D矩阵中对应的那一行,其他都乘以0了
-
tips: Loss函数和困扰度公式表示一样
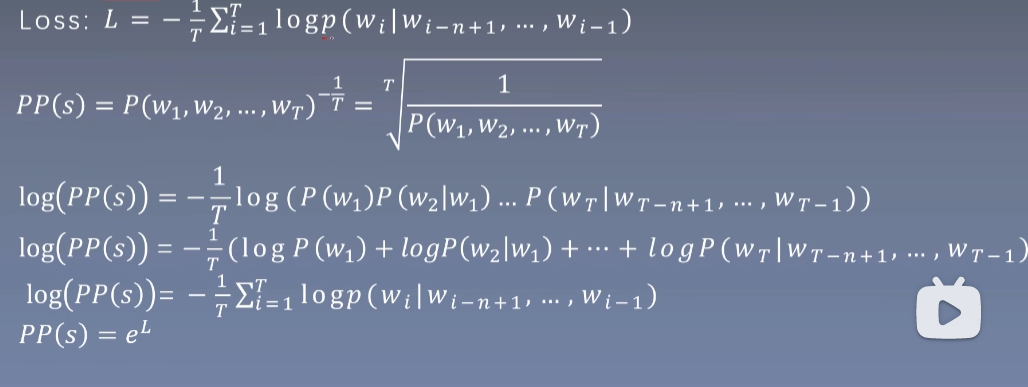
-
网络结构回顾:
- 仅对一部分输出进行梯度传播(比如对于一些例如the a and的词汇不进行或者降低梯度传播)
- 引入先验知识,如词性等(实验证明,模型在一定规则下也可以对词性进行自主学习)
- 解决一词多义的问题
- 加速softmax层。(1、层次softmax 2、负采样)
-
-
RNNLM 类似的
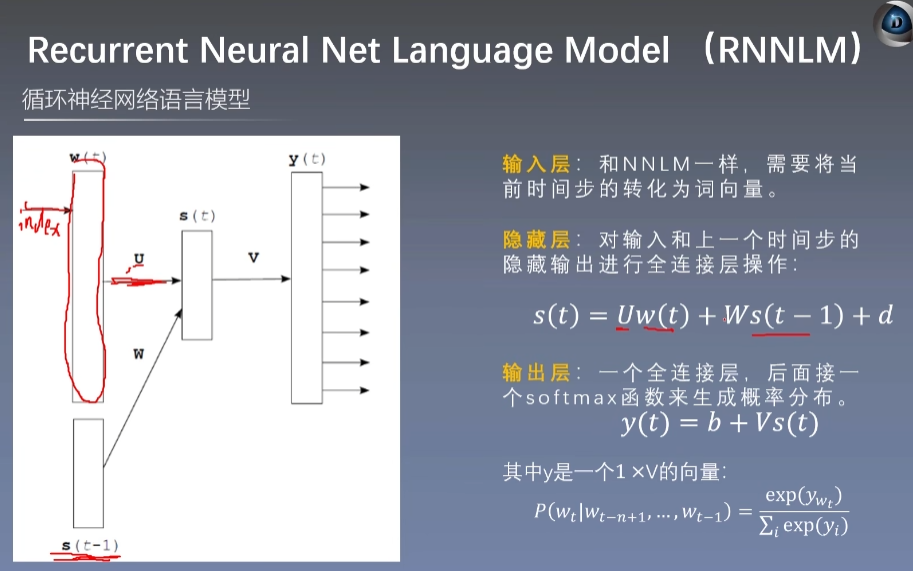
-
skip-gram
核心:中心词矩阵,周围词矩阵
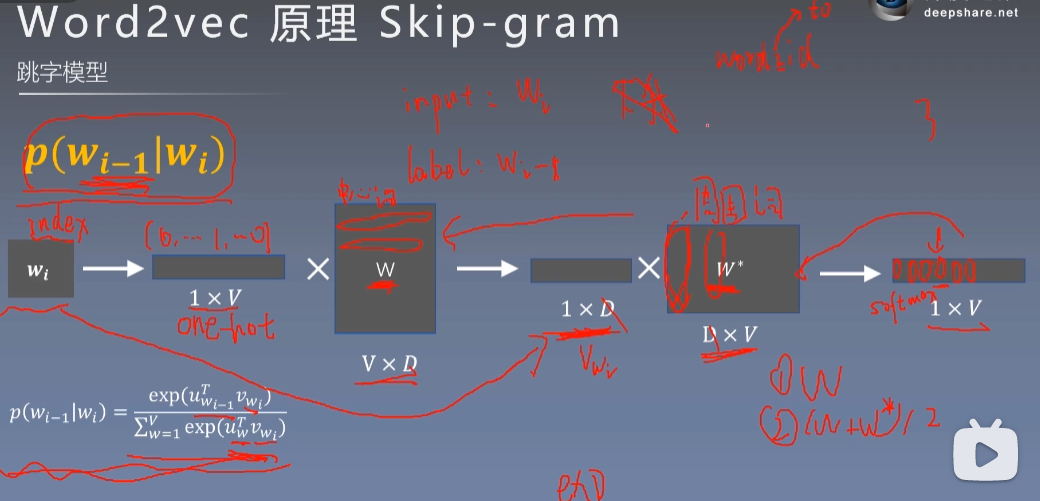
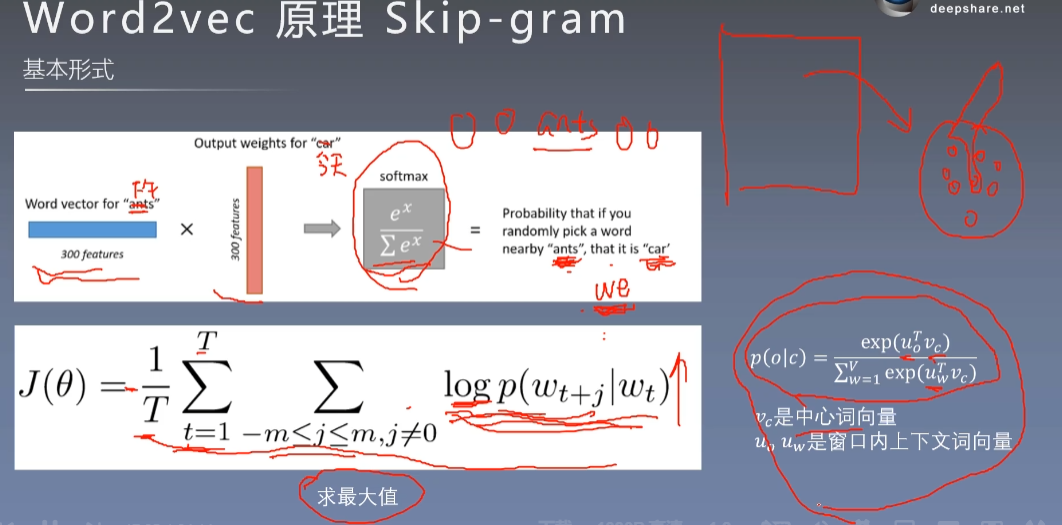
种一棵树最好的时间是十年前,其次是现在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号