TCC
理解TCC
TCC是Try、Confirm、Cancel三个词语的缩写,TCC要求每个分支事务实现三个操作:预处理Try、确认Confirm、撤销Cancel。Try操作做业务检查及资源预留,Confirm做业务确认操作,Cancel实现一个与Try相反的操作即回滚操作。TM首先发起所有的分支事务的Try操作,任何一个分支事务的try操作执行失败,TM将会发起所有分支事务的Cancel操作,若try操作全部成功,TM将会发起所有分支事务的confirm操作,其中confirm/cancel操作若执行失败,TM会重试。
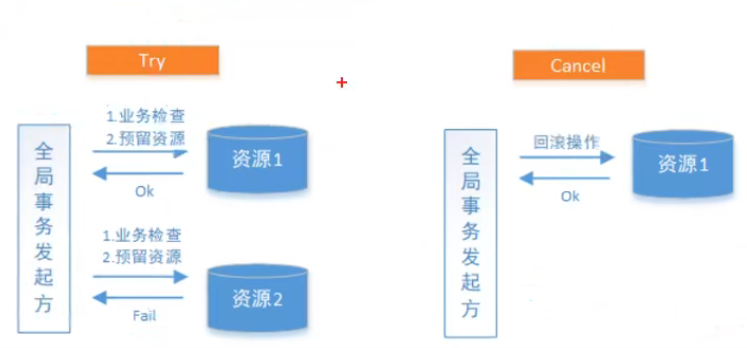
分支事务失败的情况:
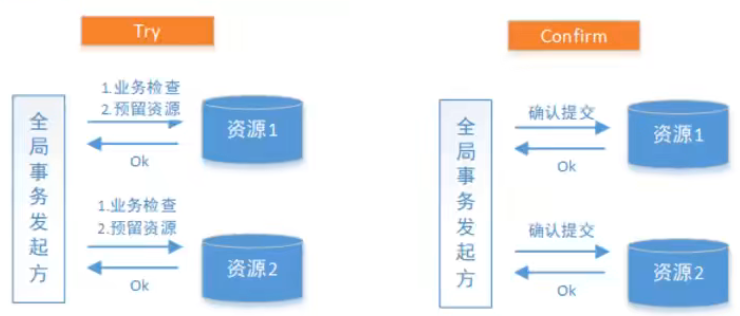
TCC分为3个阶段
-
Try 阶段是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的Confirm一起才能真正构成一个完整的业务逻辑。
-
Confirm 阶段是做确认提交,Try 阶段所有分支事务执行成功后开始执行Confirm。通常情况下,采用TCC则认为Confirm阶段是不会出错的。即:只要Try 成功,confirm一定成功。若Confirm阶段真的出错了,需引入重试机制或人工处理。
-
Cancel阶段是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采用TCC则认为Cancel 阶段也一定是成功的。若Cancel阶段真的出错了,需引入重试机制或人工处理。
-
TM事务管理器
TM事务管理器可以实现为独立的服务,也可以让全局事务发起方充当TM的角色,TM独立出来是为了成为公用组件,是为了考虑系统结构和软件复用。
TM在发起全局事务时生成全局事务记录,全局事务ID贯穿整个分布式事务调用链路,用来记录事务上下文,追踪和记录状态,由于Confirm 和 Cancel 失败需进行重试,因此需要实现为幂等,幂等性是指同一个操作无论请求多少次,其结果都相同。
TCC解决方案
轻量级框架Hmily,Hmily是一个高性能分布式事务TCC开源框架。基于Java语言来开发(JDK1.8),支持Dubbo,SpringCloud等RPC框架进行分布式事务。它支持以下特性:
-
支持嵌套事务(Nested transaction support)
-
采用disruptor框架进行事务日志的异步读写,与RPC框架的性能毫无差别。
-
支持SpringBoot-Starter项目启动,使用简单。
-
RPC框架支持:dubbo,motan,springcloud
-
本地事务存储支持:redis,mongodb,zookeeper,file,mysql
-
事务日志序列化支持:java,hessian,kryo,protostuff
-
采用Aspect AOP 切面思想与Spring无缝集成,天然支持集群
-
RPC事务回复,超时异常恢复等。
Hmily 利用AOP对参与分布式事务的本地方法与远程方法进行拦截处理,通过多方拦截,事务参与者能透明的调用到另一方的Try、Confirm、Cancel方法;传递事务上下文;并记录事务日志,酌情进行补偿,重试等。
Hmily不需要事务协调服务,但需要提供一个数据库(redis,mongodb,zookeeper,file,mysql)来进行日志存储。
Hmily实现的TCC服务与普通的服务一样,只需要暴露一个接口,也就是它的Try业务。Confirm/Cancel业务逻辑,只是因为全局事务提交/回滚的需要才提供的,因此Confirm/Cancel业务只需要被Hmily TCC事务框架发现即可,不需要被调用它的其它业务服务所感知。
TCC需要注意三种异常处理分别是空回滚、幂等、悬挂:
- 空回滚:
- 在没有调用TCC资源Try方法的情况下,调用了二阶段的Cancel方法,Cancel方法需要识别出这是一个空回滚,然后直接返回成功。
- 出现原因是当一个分支事务所在服务宕机或网络异常,分支事务调用记录为失败,这个时候其实是没有执行Try阶段,当故障恢复后,分布式事务进行回滚则会调用二阶段的Cancel方法,从而形成空回滚。
- 解决思路的关键就是要识别出这个空回滚。思路很简单就是需要直到一阶段是否执行,如果执行了,那就是正常回滚;如果没有执行,那就是空回滚。前面已经说过TM在发起全局事务时生成全局事务记录,全局事务ID贯穿整个分布式事务调用链路。再额外增加一张分支事务记录表,其中有全局事务ID和分支事务ID,第一阶段Try方法里会插入一条记录,表示一阶段执行了。Cancel接口里读取该记录,如果该记录存在,则正常回滚;如果该记录不存在,则是空回滚。
- 幂等:
- 为了保证TCC二阶段提交重试机制不会引发数据不一致,要求TCC的二阶段Try、Confirm和Cancel接口保证幂等,这样不会重复使用或者释放资源。如果幂等控制没有做好,很有可能导致数据不一致等严重问题。
- 解决思路再上述“分支事务记录”中增加执行状态,每次执行前都查询该状态。
- 悬挂:
- 悬挂就是对于一个分布式事务,其二阶段Cancel接口比Try接口先执行。
- 出现原因是再RPC调用分支事务try时,先注册分支事务,再执行RPC调用,如果此时RPC调用的网络发生阻塞,通常RPC调用是有超时时间的,RPC超时以后,TM就会通知RM回滚该分布式事务,可能回滚完成后,RPC请求才到达参与者真正执行,而一个Try方法预留的业务资源,只有该分布式事务才能使用,该分布式事务第一阶段预留的业务资源就再也没有人能够处理了,对于这种情况,我们就称为悬挂,即业务资源预留后没法继续处理。
比较
- 如果拿TCC事务的处理流程与2PC两阶段提交做比较,2PC通常都是在跨库的DB层面,而TCC则是应用层面的处理,需要通过业务逻辑来实现。这种分布式事务的实现方式的优势在于可以让应用自己定义数据操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
- 不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现try、confirm、cancel三个操作。此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号