SpringIOC循环依赖
1. 什么是循环依赖
循环依赖其实就是循环引⽤,也就是两个或者两个以上的 Bean 互相持有对⽅,最终形成闭环。⽐如A依赖于B,B依赖于C,C⼜依赖于A
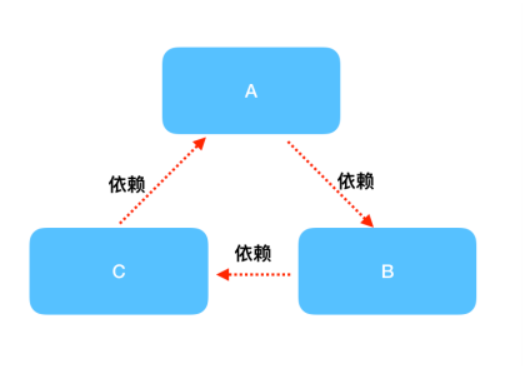
注意:
这⾥不是函数的循环调⽤,是对象的相互依赖关系。
循环调⽤其实就是⼀个死循环,除⾮有终结 条件。
Spring中循环依赖场景有:
- 构造器的循环依赖(构造器注⼊)
- Field 属性的循环依赖(set注⼊)
其中,构造器的循环依赖问题⽆法解决,只能拋出 BeanCurrentlyInCreationException 异常,在解决属性循环依赖时,spring采⽤的是提前暴露对象的⽅法。
2. 循环依赖处理机制
- 单例 bean 构造器参数循环依赖(⽆法解决)
- prototype 原型 bean循环依赖(⽆法解决)
因为prototype 原型 bean ,产生对象之后是不在容器中管理的。 - 单例bean通过setXxx或者@Autowired进行循环依赖(可以解决)
2.1 演示场景:
//lagouBen 依赖于 ItBean
public class LagouBean {
private ItBean itBean;
public void setItBean(ItBean itBean) {
this.itBean = itBean;
}
public LagouBean() {
System.out.println("LagouBean 构造器");
}
}
//ItBean 依赖于 LagouBen
public class ItBean {
private LagouBean lagouBean;
public void setLagouBean(LagouBean lagouBean) {
this.lagouBean = lagouBean;
}
public ItBean() {
System.out.println("ItBean...构造器");
}
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="lagouBean" class="com.lagou.edu.LagouBean" >
<property name="ItBean" ref="itBean>"></property>
</bean>
<bean id="itBean" class="com.lagou.edu.ItBean" >
<property name="LagouBean" ref="lagouBean>"></property>
</bean>
</beans>
2.2 处理机制简图
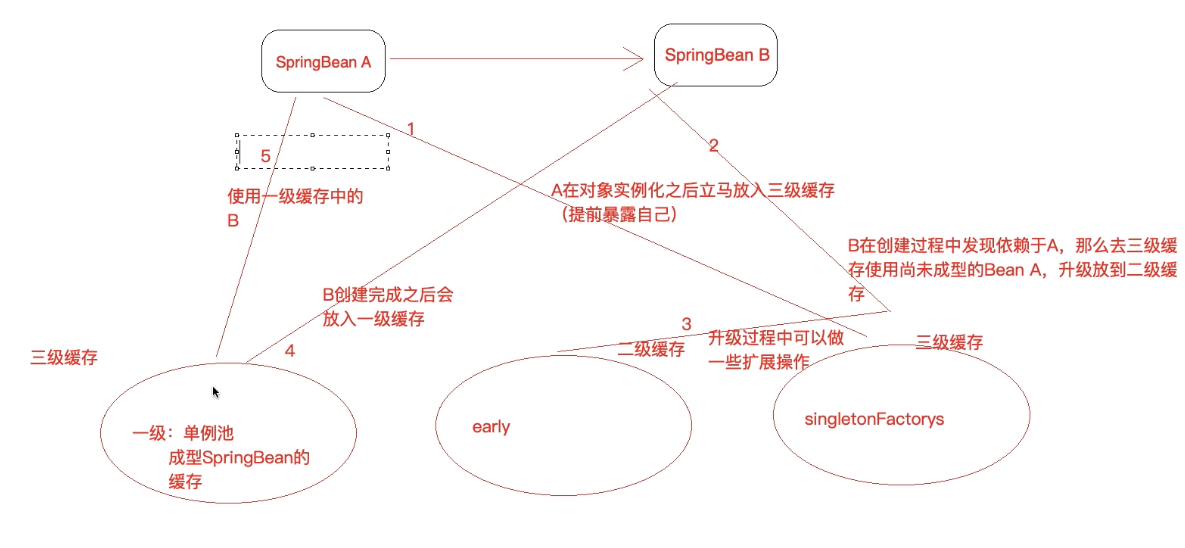
总结:
A依赖于B ,B 依赖于A
A在创建过程中 :
-
首先会创建Bean实例(仅仅调用构造方法,但是尚未设置属性,通过反射完成对象的初始化),
-
然后判断是否是单例,是否有循环依赖。
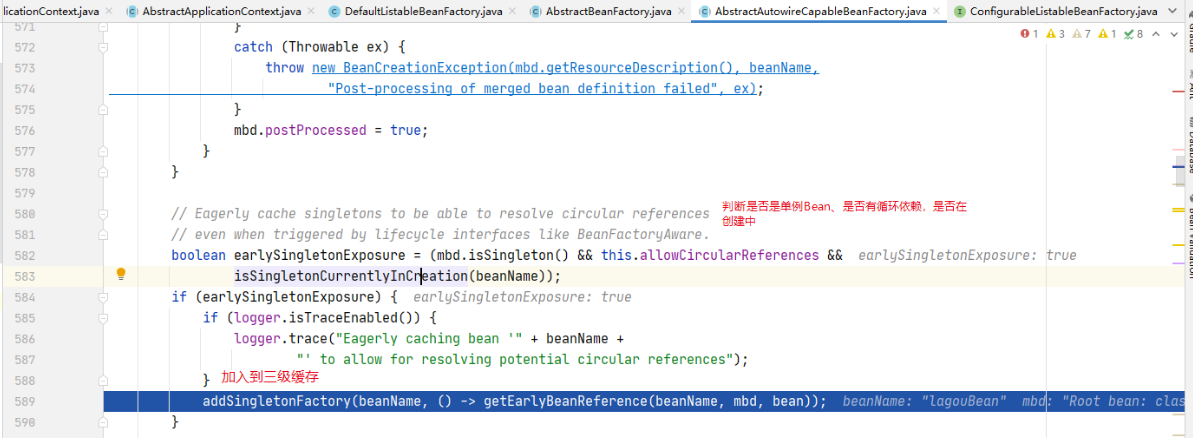
-
把创建好的Bean实例放入三级缓存——singletonFactories
-
然后将要给A Bean装配属性,发现依赖B

-
调用deGetBean() 想拿到B,首先从一级缓存(singletonObjects)中拿,然后从二级缓存中(earlySingletonObjects)拿,然后从三级缓存(singletonFactories)拿,都拿不到,那就开始创建B Bean
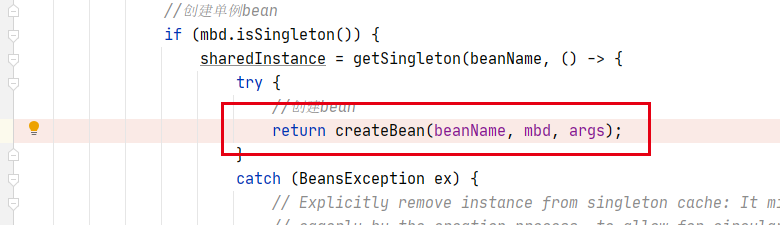
-
把创建好的B Bean实例放入三级缓存——singletonFactories,发现依赖于A
-
调用deGetBean() 想拿到A,首先从一级缓存(singletonObjects)中拿,然后从二级缓存中(earlySingletonObjects)拿,都没拿到。然后从三级缓存中拿,拿到了
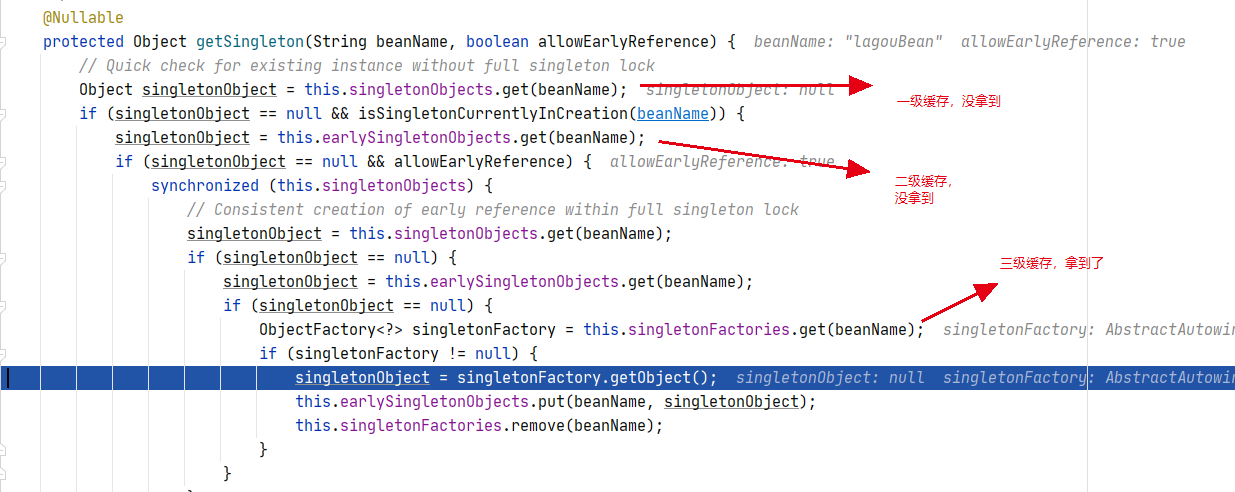
-
拿到A Bean之后如上图,放到二级缓存(earlySingletonObjects)中,然后从三级缓存(singletonFactories)中删除。然后给B bean赋值了。
-
此时B Bean 就装配好了 放入一级缓存池中。
-
B 装配好了之后,A 就能顺利的装配了,然后调用
addSingleton()方法,把A 从二级三级缓存中删除,然后放到一级缓存也就是单例池中。
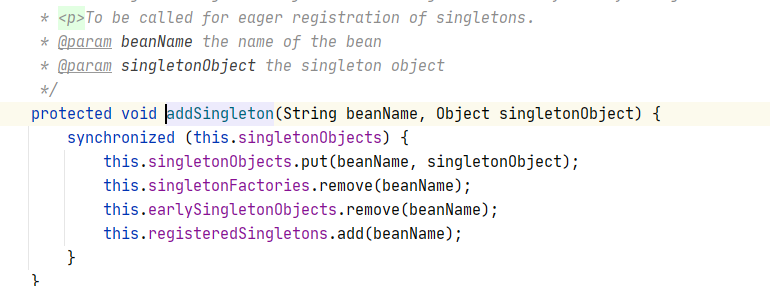
-
完成
注意:
这个案例中,B不会放到二级缓存,只有在B依赖的一个对象尚未实例化的时候才会把B放到二级缓存。例如:
A依赖B,B依赖A和C,C依赖B。 先创建A,把尚未赋值的A放到三级缓存,然后赋值B,找不到B,然后创建B,然后把尚未赋值的B放到三级缓存,然后在创建B的过程中从三级缓存找A(同时把A从三级缓存中删除然后加入到二级缓存),然后B还有个属性C,赋值C,从缓存中找不到C,然后创建C,然后把尚未赋值的B放到三级缓存,创建C的过程中发现C依赖于B,然后可以从三级缓存中找到B,然后把B放到二级缓存,C就装配完毕了,放到一级缓存。同时B也有了A和C,B装配完毕了,放到一级缓存。 A依赖B,B已经OK了,那么A也装配完毕了。
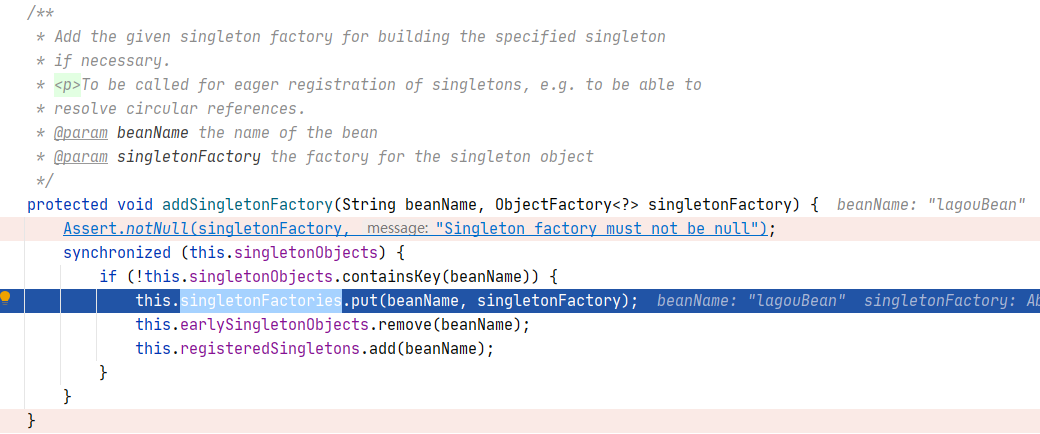
/** Cache of singleton factories: bean name to ObjectFactory. */
//三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
//二级缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
/** Cache of singleton objects: bean name to bean instance. */
//一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
本文来自博客园,作者:邓晓晖,转载请注明原文链接:https://www.cnblogs.com/isdxh/p/14068337.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号