

Python中调用R语言代码(rpy2)的一些报错和解决
我搭建网站的过程中,需要将可视化的图下载下来,使用Echarts是比较好看,但是下载的是图片格式(png),项目需求是下载PDF的R绘制的图。
所以我这边使用Python调用R代码,借rpy实现这个功能。
在 Python 中调用 R 代码有多种方式,其中最常用的是通过 rpy2 库,它允许在 Python 中运行 R 代码并获取结果。
rpy2 是一个非常强大的 Python 库,可以直接在 Python 中运行 R 代码并返回结果。
安装 rpy2:
1.
R_HOME must be set in the environment or Registry
Process finished with exit code 2
已解决,解决方案:配置环境变量:
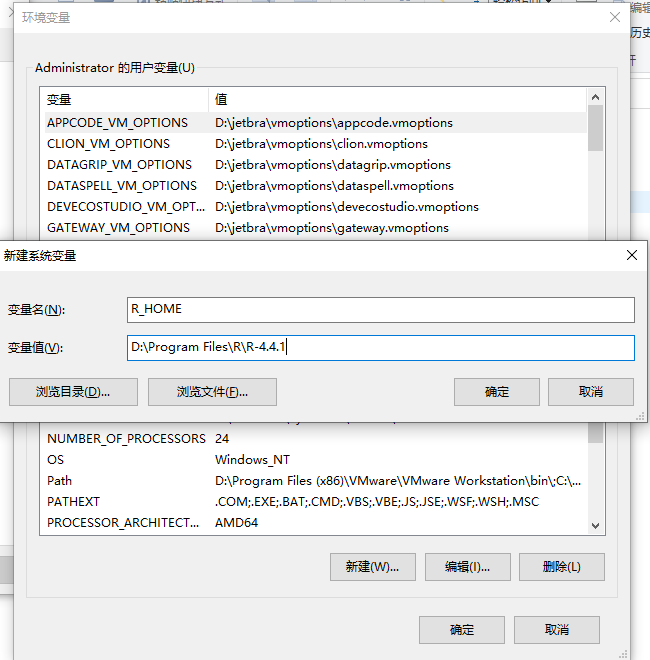
path里还需要配置R_HOME下的bin别忘了。
2.
R调用成功,但是生成的文件保存在本地,浏览器访问不到。
浏览器有同源政策,需要跨域。但是访问本地文件这种操作一般是不允许的,我换了存储了路径,保存在代码同一目录下,就可以了。
在 Django 视图中,使用 rpy2 调用 R 生成图像,并保存到 MEDIA_ROOT,然后返回图像的 URL:
①确保在 settings.py 中配置 MEDIA_ROOT 和 MEDIA_URL,用于保存和访问生成的图像。
settings.py:
# settings.py import os # 用于保存媒体文件的目录 MEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/'
②视图调用生成PNG和PDF并返回URL:
views.py:
def generate_r_plot():
import rpy2.robjects as robjects # 这个为什么要放在这里才有效啊,我真麻了
# 获取保存图像的目录
image_dir = os.path.join(settings.MEDIA_ROOT, 'rplots', 'analysisDiff')
if not os.path.exists(image_dir):
os.makedirs(image_dir)
# 定义保存 PNG 和 PDF 的文件路径,使用当前时间戳命名文件
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
png_filename = f"analysis_plot_{timestamp}.png"
pdf_filename = f"analysis_plot_{timestamp}.pdf"
png_path = os.path.join(image_dir, png_filename)
pdf_path = os.path.join(image_dir, pdf_filename)
# 数据文件路径 (假设 test.txt 位于项目的 data 目录下)
data_file = os.path.join(settings.DATA_ROOT, 'analysisDiff', 'test.txt')
# import chardet
# with open(data_file, 'rb') as f:
# result = chardet.detect(f.read())
# print(result) # 这个文件读出来就是ascii码了
# 转换路径为R兼容的格式 总觉得这样很多重复代码
pdf_path_r = pdf_path.replace("\\", "/")
png_path_r = png_path.replace("\\", "/")
data_path_r = data_file.replace("\\", "/")
# 将路径传递给R环境
robjects.globalenv['pdf_path_r'] = pdf_path_r
robjects.globalenv['png_path_r'] = png_path_r
robjects.globalenv['data_path_r'] = data_path_r
# 调用 R(PNG 和 PDF 两种格式)
r = robjects.r
r('''
library(data.table)
library(dplyr)
library(ggplot2)
library(tidyr)
df <- read.table(data_path_r, header = T, check.names = F, fileEncoding = "ASCII")
df1 <- df %>% pivot_longer(cols = normal:disease, names_to = "category", values_to = "ExpressionFPKM")
p <- ggplot(df1, aes(x = dataset, y = ExpressionFPKM, fill = category)) +geom_col(width=0.5,position='dodge')
ggsave(pdf_path_r,width = 20,height = 6,family="GB1")
ggsave(png_path_r,width = 20,height = 6)
''')
return png_path, pdf_path
# 差异分析异步出图-用R绘图展示PNG以及下载PDF
def diff_analysis_plot_use_r(request):
png_path, pdf_path = generate_r_plot()
if not os.path.exists(pdf_path) or not os.path.exists(png_path):
return JsonResponse({'error': 'Plot generation failed'}, status=500)
# 返回 PNG 图像的 URL 和 PDF 路径
# pdf_url = f'/media/rplots/analysisDiff/{os.path.basename(pdf_path)}'
pdf_name = os.path.basename(pdf_path) # pdf不需要路径了,只要名字就可以
png_url = f'/media/rplots/analysisDiff/{os.path.basename(png_path)}'
return JsonResponse({'png_url': png_url, 'pdf_name': pdf_name})
③为视图添加url路由:
urlpatterns = [
path('/analysis/differential/plot/R', diff_analysis_plot_use_r),
]
④前端ajax发送请求并展示图像:
js部分:
document.getElementById('plot-ECharts').style.display = 'none';
document.getElementById('plot-R').style.display = 'block';
document.getElementById('downloadLink').style.display = 'inline'; // 下载按钮给加上
$.ajax({
type: 'POST',
dataType: 'json',
data: {},
url: '/cuDB/analysis/differential/plot/R',
success: function (data) {
pdfname = data.pdf_name;
$('#R_png').attr('src', data.png_url).show();
// 动态更新a标签的href
const downloadLink = document.getElementById('downloadLink');
downloadLink.href = '/cuDB/analysis/differential/plot/R/download/?file_path=' + pdfname;
console.log("这里2")
},
});
按钮部分:
<!--为echart准备一个具备大小的dom 大小还要调整 -->
<div id="plot-ECharts" style="width: 100%;height: 300px;margin-left: auto">
</div>
<!-- 用于显示 R 生成的图像 -->
<div id="plot-R">
<img id="R_png" src="" alt="Scatter Plot" style="display:none; max-width: 100%;">
</div>
⑤项目结构大致如下:
your_project/
│
├── your_app/
│ ├── migrations/
│ ├── templates/
│ │ └── template.html
│ ├── views.py
│ ├── urls.py
│ └── ...
│
├── media/ # 保存 R 生成图像的文件夹(实际我分得更细,还有一层)
│ └── rplots/
│
├── settings.py
└── ...
3.NotImplementedError:
Conversion rules for `rpy2.robjects` appear to be missing. Those rules are in a Python `contextvars.ContextVar`. This could be caused by multithreading code not passing context to the thread. Check rpy2's documentation about conversions.
NotImplementedError 的间歇性出现通常与以下因素有关:
-
多线程/异步环境:如果在多线程或异步代码中调用
generate_r_plot,可能导致上下文丢失,导致不一致的行为。 -
上下文管理:在某些情况下,未正确管理上下文会导致错误。例如,某些线程可能没有访问到正确的上下文变量。
-
R 和 rpy2 版本兼容性:不同版本之间的兼容性问题可能导致间歇性的错误。某些函数在不同版本下的实现可能不同。
-
变量的生命周期:确保在使用之前,所有传递给
globalenv的变量都是有效的。如果变量在某个线程中被修改或失效,可能会导致错误。 -
运行环境:在不同的环境(如 Jupyter Notebook 和标准 Python 脚本)中,行为可能会有所不同。
但是我尝试了使用上下文管理器,依然没有解决。
最终我将rpy2版本降级为3.5.1,解决了这个问题。
版本降级方法:
- 查看当前版本:
import rpy2 print(rpy2.__version__)
- 我的当前版本是3.5.16,我要降级为3.5.1。
-
打开 PyCharm,然后打开项目。
-
转到 "File" 菜单,选择 "Settings"(对于 macOS 用户,选择 "PyCharm" 菜单中的 "Preferences")。
-
在设置或首选项窗口中,选择 "Project: 项目名称",然后点击 "Project Interpreter" 下拉菜单。
-
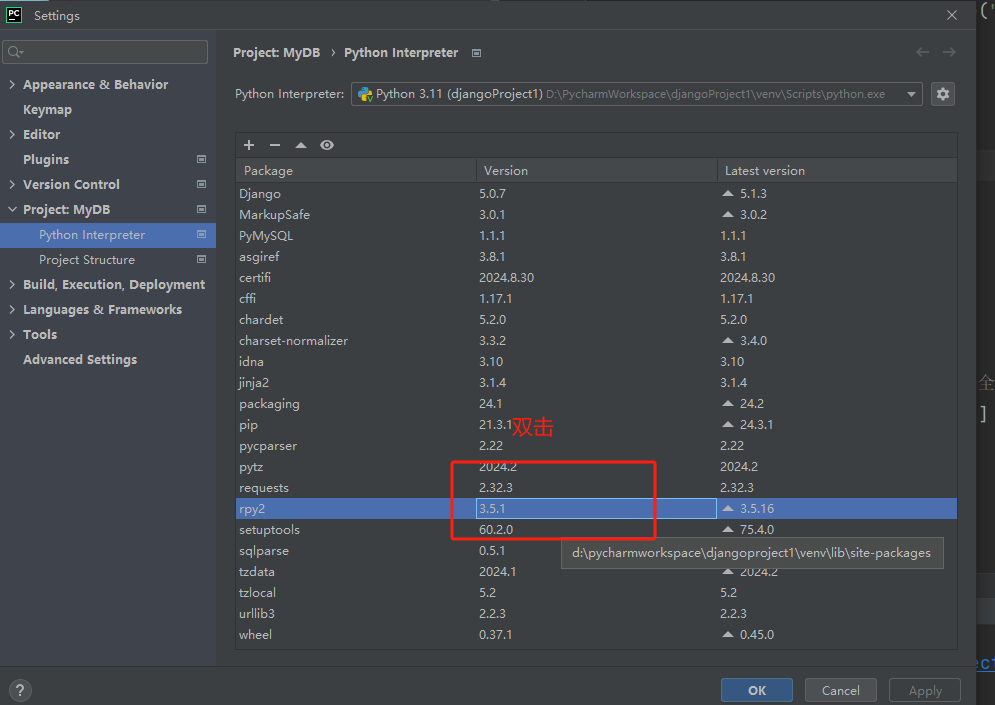
在下拉菜单中,看到当前项目关联的解释器列表。选择想要从中改变版本
rpy2的解释器,双击。![]()
-
这个时候打开一个新窗口。选择特殊版本,选到3.5.1.
![]()
然后左下角install package。
- 依次ok。
注意:版本降级之后,可能还会出下面的错误5,再解决一下就好。
-

4.调用R生成的PDF,对这个PDF文件实现下载功能:
直接定义一个a标签,动态更新a标签的href:
html:
<!-- 下载按钮 -->
<a id="downloadLink" href="#" class="btn btn-primary">download pdf</a>
js部分:在上面调用的时候就完成了这个动态更新的动作
document.getElementById('plot-ECharts').style.display = 'none';
document.getElementById('plot-R').style.display = 'block';
document.getElementById('downloadLink').style.display = 'inline'; // 下载按钮给加上
$.ajax({
type: 'POST',
dataType: 'json',
data: {},
url: '/cuDB/analysis/differential/plot/R',
success: function (data) {
pdfname = data.pdf_name;
$('#R_png').attr('src', data.png_url).show();
// 动态更新a标签的href
const downloadLink = document.getElementById('downloadLink');
downloadLink.href = '/cuDB/analysis/differential/plot/R/download/?file_path=' + pdfname;
},
});
后端加个路径:
path('/analysis/differential/plot/R/download/', diff_analysis_download),
views.py:
def diff_analysis_download(request):
file_path = request.GET.get('file_path') # 从查询参数获取文件路径
print(file_path)
if file_path:
# 构建完整的文件系统路径
abs_file_path = os.path.join(settings.MEDIA_ROOT, 'rplots', 'analysisDiff', file_path)
# 检查文件是否存在
if os.path.exists(abs_file_path):
with open(abs_file_path, 'rb') as file:
response = HttpResponse(file.read(), content_type='application/pdf')
response['Content-Disposition'] = f'attachment; filename="{os.path.basename(file_path)}"'
return response
else:
return HttpResponse('文件不存在', status=404)
else:
return HttpResponse('文件路径无效', status=400)
5.rpy调用R语言的时候UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 79: invalid start byte
在使用 rpy2 调用 R 代码时遇到 UnicodeDecodeError 通常是因为读取的数据文件的编码与 Python 默认的 UTF-8 编码不匹配。
首先可以使用chardet库检测文件编码:
import chardet
with open("your_file.tsv", 'rb') as f:
result = chardet.detect(f.read())
print(result)
根据检测到的编码选择相应的编码读取文件。我这里尝试改变R里的读取文件的编码,但是依然没有解决:
data_file_surv_r <- file("TCGA-BLCA.survival.tsv.gz", encoding = "UTF-8") # 这段是r代码,没有解决,还是报错
应该是R最终返回给Python的信息和python编码不统一,并不是文件的问题。
最后我更改了rpy包的相关代码:../site-packages/rpy2/rinterface_lib/conversion.py文件中的代码如下:(如果找不到这个文件,可以在报错提示那里找到哦)
更改前:

更改后:
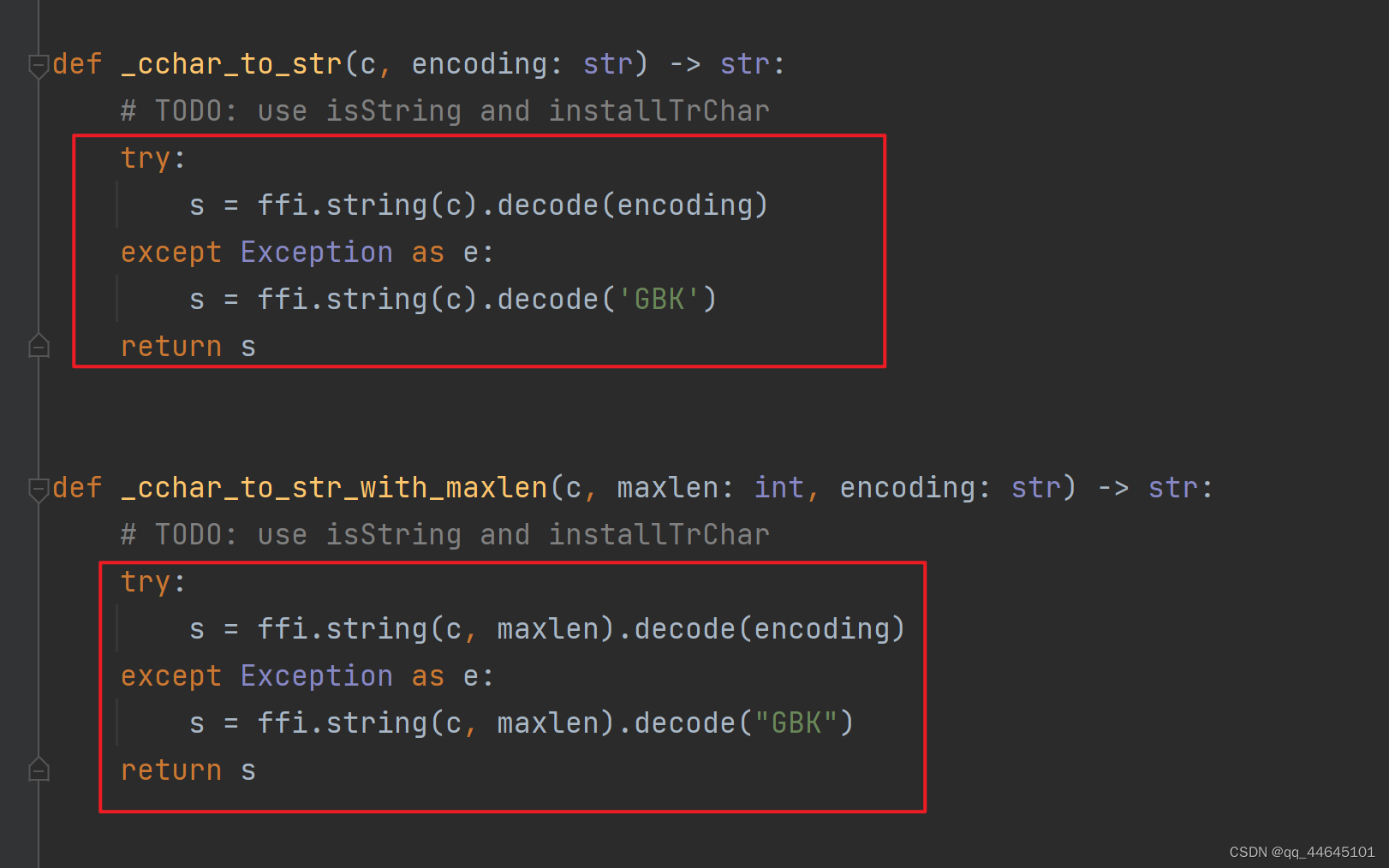
def _cchar_to_str(c, encoding: str) -> str:
# TODO: use isString and installTrChar
try:
s = ffi.string(c).decode(encoding)
except Exception as e:
s = ffi.string(c).decode('GBK')
return s
def _cchar_to_str_with_maxlen(c, maxlen: int, encoding: str) -> str:
# TODO: use isString and installTrChar
try:
s = ffi.string(c, maxlen).decode(encoding)
except Exception as e:
s = ffi.string(c, maxlen).decode('GBK')
return s
参考:https://blog.csdn.net/qq_44645101/article/details/127069531

 浙公网安备 33010602011771号
浙公网安备 33010602011771号