当前仍可用的爬取Youtube视频方法
import yt_dlp
import http.cookiejar
import time
import logging
import os
import random
# Setup logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def load_cookies_from_netscape(cookie_file):
cookie_jar = http.cookiejar.CookieJar()
with open(cookie_file, 'r') as file:
for line in file:
if line.startswith('#') or not line.strip():
continue
parts = line.strip().split('\t')
if len(parts) >= 7:
domain, flag, path, expires, name, value = parts[0:6]
cookie_jar.set_cookie(http.cookiejar.Cookie(
version=0,
name=name,
value=value,
port=None,
port_specified=False,
domain=domain,
domain_specified=True,
domain_initial_dot=domain.startswith('.'),
path=path,
path_specified=True,
secure=flag == 'TRUE',
expires= None,
discard=True,
comment=None,
comment_url=None,
rest=None
))
return cookie_jar
def download_youtube_videos(video_urls, cookie_file, output_path, user_agent):
cookie_jar = load_cookies_from_netscape(cookie_file)
ydl_opts = {
'cookiejar': cookie_jar,
'outtmpl': f'{output_path}/%(id)s.%(ext)s', # Save file as video ID
'http_headers': {
'User-Agent': user_agent
}
}
for video_url in video_urls:
attempt = 0
max_attempts = 2 # Maximum number of retries
while attempt < max_attempts:
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([video_url]) # Note: must pass a list
break # Break if download is successful
except Exception as e:
logging.error(f"Failed to download {video_url}: {e}")
attempt += 1
time.sleep(5) # Delay before retrying
else:
logging.error(f"Exceeded maximum retries for {video_url}")
# Example usage
video_urls = []
with open('mission.txt', 'r') as file:
datas = file.readlines()
random.shuffle(datas)
for data in datas:
video_urls.append('https://www.youtube.com/watch?v=' + data.strip()) # Ensure no extra whitespace
cookie_file = 'youtube.com_cookies.txt' # Replace with your cookie file path
output_path = './' # Replace with your desired output path
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.96 Safari/537.36' # Replace with your user agent string
download_youtube_videos(video_urls, cookie_file, output_path, user_agent)需要注意的几点是
1,yt_dlp库
2,UA模仿正常用户浏览
3,携带Cookie
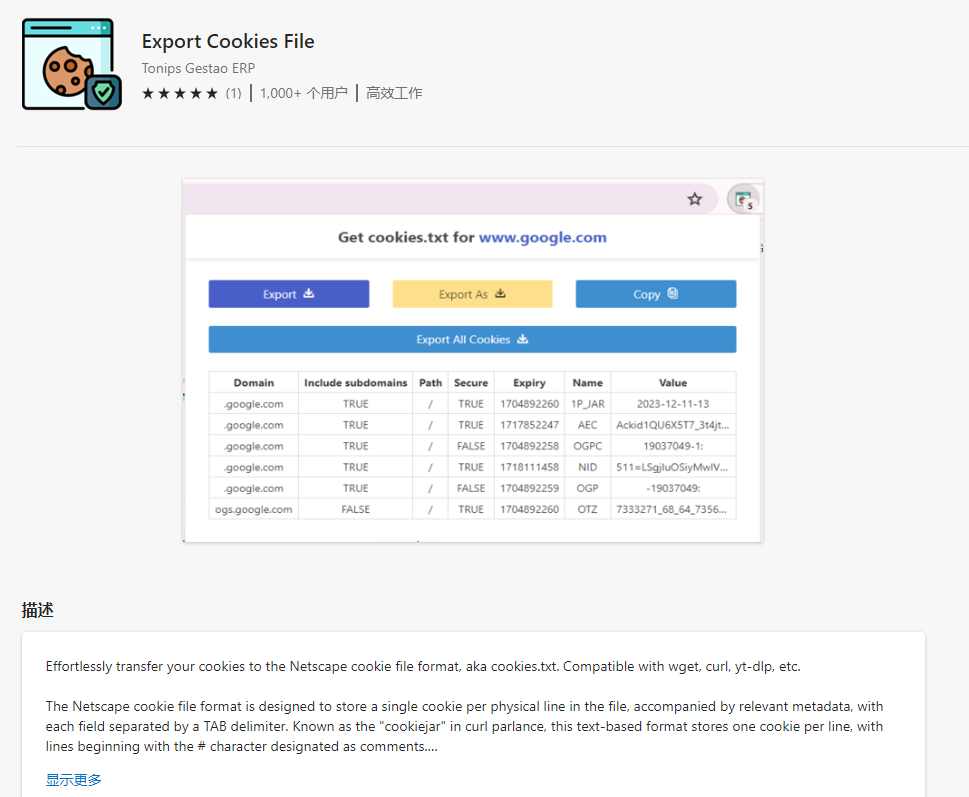
其中,mission.txt是待下载的视频ID,youtube.com_cookies.txt为登录Youtube后导出的Cookie,格式如下:
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# This is a generated file! Do not edit.
.youtube.com TRUE / TRUE ......可以使用此类工具导出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号